目录
3.总结pg服务管理相关命令 pg_ctl 和pgsql命令选项及示例和不同系统的初始化操作
6.总结库,模式,表的添加和删除操作。表数据的CURD。同时总结相关信息查看语句。
8.添加mage用户,magedu模式,准备zabbix库,配置mage用户的默认模式magedu,要求mage用户给zabbix库有所有权限。
10.pg_hba.conf #认证配置文件,配置了允许哪些IP的主机访问数据库,认证的方法是什么等信息
14.实现WAL日志完成主从流复制,要求在从节点上进行crontab数据备份,同时手工让主节点宕机,让从节点切换为主节点,并添加新的从节点。
16.总结日志分类, 优先级别。图文并茂解释应用如何将日志发到rsyslog,并写到目标。
18.完成功能,sshd应用将日志写到rsyslog的local6分类,过滤所有级别,写入到/var/log/ssh.log。
19.完成功能,将3个主机(要求主机名为ip)的ssh日志,通过rsyslog服务将ssh日志写入到集中的主机上的rsyslog服务,写入到/var/log/all-ssh.log文件
22.完成将多个主机(要求主机名为ip)的nginx日志集中写入到mysql表中
22.尝试使用logrotate服务切割nginx日志,每天切割一次,要求大于不超过3M, 保存90天的日志, 旧日志以时间为后缀,要求压缩。
1.总结pg和mysql的优劣势。
PostgreSQL优势 PostgreSQL完全免费,BSD协议,开源软件很多,容易实现读写分离,负载均衡,数据水平拆分等方案,支持复制查询,支持用户自定义类型或域,支持sequence,PostgerSQL是多进程的,当并发高时,总体处理性能强,DDL支持事务,explain返回信息丰富,可以支持秒以下的存储类型
劣势 并发不高时,Mysql处理速度快
2.总结pg二进制安装和编译安装。
二进制安装 各个Linux的版本较旧,很多都内置了PostgreSQL的二进制安装包,但内置的版本可能较久,对于二进制包的安装方法是通过不同发行版本的Linux下的包管理器进行的,如在THEL系统相关版本下用yum命令,在Ubuntu下用apt命令
源码编译安装 使用源码编译安装更为灵活,用户可以有更多的选择,可以选择较新的版本、配置不同的编译选项,编译出用户喜欢的功能
3.总结pg服务管理相关命令 pg_ctl 和pgsql命令选项及示例和不同系统的初始化操作
初始化数据库 initdb -D $PGDATA #
-D 指定数据库实例的数据目录,使用环境变量PGDATA指定的路径 pg_ctl init
查看服务状态 pg_ctl status #-D
启动服务 pg_ctl -D $PGDATA -l logfile start
-D datadir#指定数据库实例的数据目录 -l #服务器日志输出到logfile中
停止数据库服务 pg_ctl stop -D $PGDATA -m #指定数据库停止方法 smart:等待所有连接终止后,关闭数据库 fast:快速关闭数据库,断开客户端的连接 immediate:立刻关闭数据库
重启服务 pg_ctl restart
加载配置 pg_ctl reload
将从服务器提升为主服务器,恢复读写操作 pg_ctl promote
psql命令 psql -h <ip or hostname> -p<端口> [数据库名称] -U [用户名称] -h #指定要连接的数据库主机名或IP地址 -p #指定连接的数据库端口
4.总结pg数据库结构组织
数据的组织结构可以分为五层:
实例:一个postsql对应安装的数据目录$PGDATA,即一个instance实例
数据库:一个postgresql数据库服务下可以管理多个数据库,当应用连接到一个数据库时,一般只能访问这个数据库中的数据
模式:一个数据库可以创建多个不同的名称空间Schema,用于分隔不同的业务数据
表和索引:一个数据库可以有多个表和索引,在postgressql中的术语为Relation,在其他数据库叫Table
行和列:每张表有很多列和行数据,在postgresql的术语Tuple,在其他数据库叫Row
5.实现pg远程连接。输入密码和无密码登陆
#需要输入密码登录
postgres@ubuntu1804:~$ vim /pgsql/data/pg_hba.conf
# TYPE DATABASE USER ADDRESS METHOD
host all all 0.0.0.0/0 md5
给postgres设置密码
postgres=# alter user postgres with password '123456';
ALTER ROLE
postgres@ubuntu1804:~$#vim /pgsql/data/postgresql.conf
listen_addresses = '0.0.0.0' # what IP address(es) to listen on;
[root@rocky ~]#vim /pgsql/data/pg_hba.conf
# TYPE DATABASE USER ADDRESS METHOD
# IPv6 local connections:
host all all ::1/128 trust
host all all 0.0.0.0/0 md5 #加这一行
postgres@ubuntu1804:~$#pg_ctl restart
[root@rocky ~]#psql -h 10.0.0.180 -U postgres
Password for user postgres:
psql (14.2)
Type "help" for help.
postgres=#
postgres@ubuntu1804:~$ vim /pgsql/data/pg_hba.conf
# TYPE DATABASE USER ADDRESS METHOD
host all postgres 0.0.0.0/0 trust
[root@rocky ~]#psql -h 10.0.0.180 -U postgres
psql (14.2)
Type "help" for help.
postgres=#
[root@rocky ~]#vim .pgpass
10.0.0.180:5432:db1:postgres:123456
[root@rocky ~]#chmod 600 .pgpass
[root@rocky ~]#ll .pgpass
-rw------- 1 root root 36 Nov 27 19:45 .pgpass
[root@rocky ~]#psql -h 10.0.0.180 -U postgres -d db1
psql (14.2)
Type "help" for help.
db1=#
6.总结库,模式,表的添加和删除操作。表数据的CURD。同时总结相关信息查看语句。
管理和查看数据库
创建库
postgres@ubuntu1804:~$createdb -h 10.0.0.180 -U postgres db2
postgres=#create dababase db3;
删除数据库
postgres=#drop dababase db3;
#查看数据库存放的目录
postgres=#select oid,datname from pg_datbase;管理和查看模式
#创建模式
creat schema schma_name;
#删除模式
drop schema schema_name;
#列出所有schema
postgres=#\dn
create table n70_sch.t1 (id int);
#列出表
db1=#\dt
db1=# create schema n71_sch;
CREATE SCHEMA
db1=# create table n71_sch.t1(id int);
db1=# \dt n71_sch.t1
db1=# \dt n71_sch.* #查看n71_sch模式下所有表
\l #查看数据库
\l+ #查看更多详细的信息
\c db1 #连接到db1的数据库
db1=# create table t2 (id serial primary key,name text);
CREATE TABLE
Time: 22.247 ms
db1=# insert into t2 (name) select (md5(random()::text)) from generate_series (1,1000000);
INSERT 0 1000000
Time: 4952.041 ms (00:04.952)
db1=# select * from t2;
db1=# create table t3 ( like t2);
CREATE TABLE
Time: 12.028 ms
db1=# \d t3
Table "public.t3"
Column | Type | Collation | Nullable | Default
--------+---------+-----------+----------+---------
id | integer | | not null |
name | text | | |
db1=# select * from t3
db1-# ;
id | name
----+------
(0 rows)
Time: 0.335 ms
db1=# drop table t3;
hellodb=# insert into teachers values(5,'zhao',23,'F');
hellodb=# update teachers set name='lin' where tid=5;
hellodb=# delete from teachers where tid=5;
hellodb=# select * from teachers
db1=# truncate t2; #清空表
db1=# create table t1(id int,info text,crt_time timestamp);
CREATE TABLE
Time: 11.289 ms
db1=# insert into t1 select generate_series(1,100000),md5(random()::text),clock_timestamp();
INSERT 0 100000
Time: 102.038 ms
db1=# create index idx_t1_id on t1(id);
db1=# explain analyze select info from t1 where info = 'd86b9b5cc1a6d81647b7307f730a5d91';
db1=# explain analyze select info from t1 where id = 99999;
db1=# select info from t1 where id = 99999;
db1=# select version();
version
-----------------------------------------------------------------------------------------------------
PostgreSQL 14.2 on x86_64-pc-linux-gnu, compiled by gcc (Ubuntu 7.5.0-3ubuntu1~18.04) 7.5.0, 64-bit
(1 row)
Time: 0.583 ms
db1=# select pg_postmaster_start_time();
pg_postmaster_start_time
-------------------------------
2022-11-29 20:28:09.349821+08
(1 row)
Time: 0.676 ms
db1=# select pg_conf_load_time();
pg_conf_load_time
-------------------------------
2022-11-29 20:28:09.293068+08
(1 row)
Time: 0.364 ms
db1=# show timezone;
TimeZone
---------------
Asia/Shanghai
(1 row)
Time: 0.860 ms
db1=# select user;
db1=# show archive_mode
db1-# ;
archive_mode
--------------
on
(1 row)
Time: 0.397 ms
db1=# select name,setting from pg_settings;
db1=# show archive_mode
db1-# ;
archive_mode
--------------
on
(1 row)
Time: 0.397 ms
db1=# select name,setting from pg_settings;7.总结pg的用户和角色管理。
创建用户
create user name [with] option
创建角色
create role name [with] option #创建的角色默认无法连接
#修改用户
alter user
#删除用户
drop user
#显示所有的用户和角色
\du8.添加mage用户,magedu模式,准备zabbix库,配置mage用户的默认模式magedu,要求mage用户给zabbix库有所有权限。
postgres=# create database zabbix;
CREATE DATABASE
postgres=# \c zabbix
You are now connected to database "zabbix" as user "postgres".
zabbix=# create schema magedu;
CREATE SCHEMA
zabbix=# create user mage;
CREATE ROLE
zabbix=# alter schema magedu owner to mage;
ALTER SCHEMA
zabbix=# alter database zabbix owner to mage;-
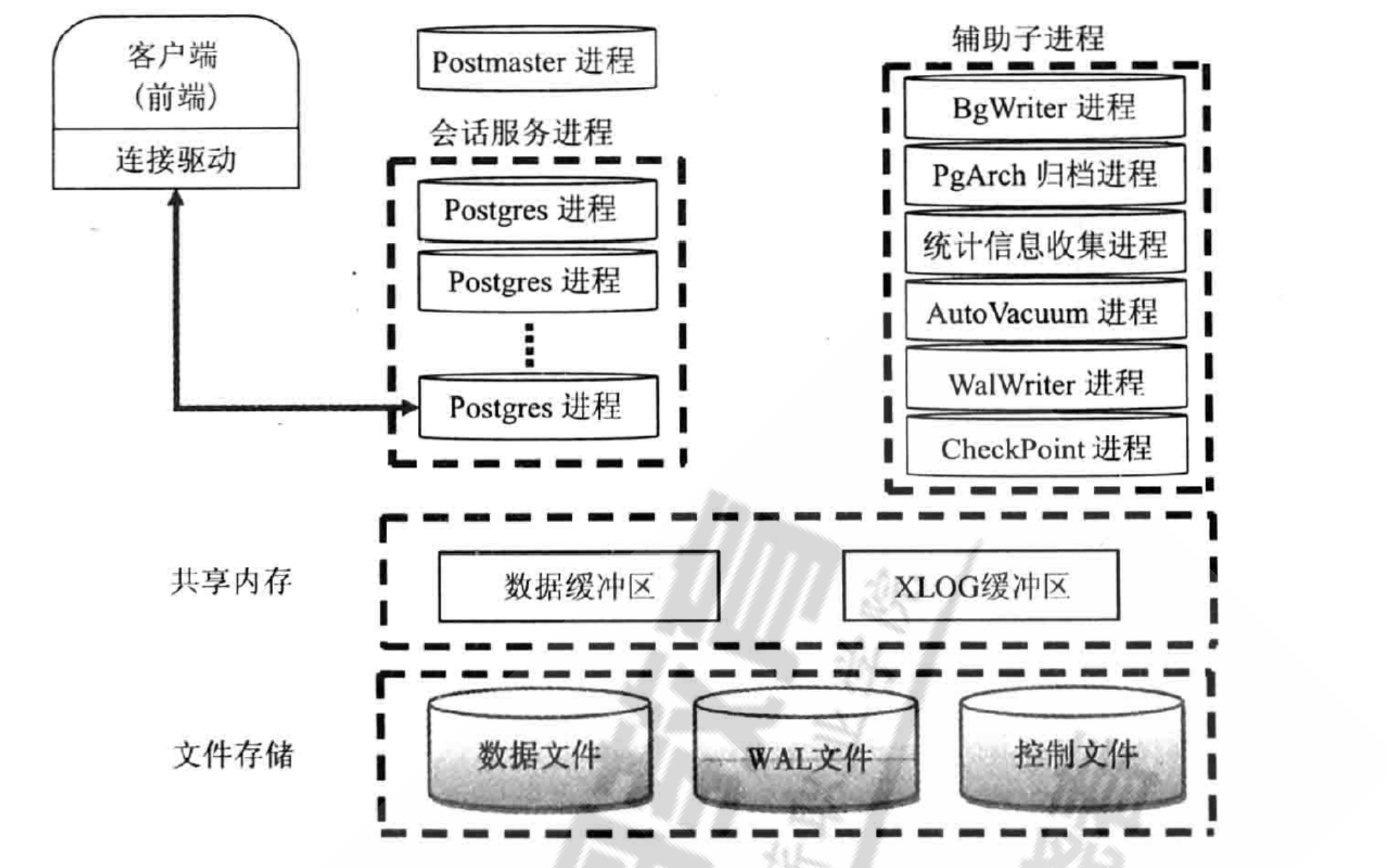
9.总结pgsql的进程结构,说明进程间如何协同工作的。
-
-
postmaster 主进程,负责启动和关闭数据库实例 创建子进程 当用户发起连接时,postmaster会和用户建立连接,然后创建子进程 当某个服务出现问题,postmaster会自动完成系统的修复 BgWriter 后台写进程 当往数据库中插入或更新数据时,并不会马上把数据持久化到数据文件中,而是先写入Buffer中 该辅助进程可以周期性的把内存中的脏数据刷新到磁盘中 WalWriter 预写式日志进程 修改数据之前,把修改操作记录到磁盘中,不需要实时的把数据持久化到文件中,即使机器突然宕机或服务器异常退出,导致一部分内存的脏数据没有及时刷新到文件中,在数据库重启时,通过读取WAL日志,并把最后一部分WAL日志重新执行一遍,就能恢复宕机时的状态 保留数据完整性,写日志是顺序写入速度快 WAL日志保存在pg_wal目录(早期版本为pg_xlog)下。每个xlog 文件默认是16MB,为了满足恢复要求,在pg_wal目录下会产生多个WAL日志,这样就可保证在宕机后,未持久化的数据都可以通过WAL日志来恢复,那些不需要的WAL日志将会被自动覆盖 Checkpointer 检查点进程 检查点(Checkpoints)是事务序列中的点,保证在该点之前的所有日志信息都更新到数据文件中 在检查点时,所有脏数据页都冲刷到磁盘并且向日志文件中写入一条特殊的检查点记录。在发o生崩溃的时候,恢复器就知道应该从日志中的哪个点(称做 redo 记录)开始做 REDO 操作,因为在该记录前的对数据文件的任何修改都已经在磁盘上了。在完成检查点处理之后,任何在redo记录之前写的日志段都不再需要,因此可以循环使用或者删除。在进行 WAL 归档的时候,这些日志在循环利用或者删除之前应该必须先归档保存检查点进程(CKPT)在特定时间自动执行一个检查点通过向数据库写入进程(BgWriter) 传递消o息来启动检查点请求 AutoVacuum 自动清理进程 1.执行delete操作时,旧的数据并不会立即被删除,在更新数据时,也不会在旧的数据上做更新,而是新生成一行数据。旧的数据只是被标识为删除状态,在没有并发的其他事务读到这些日数据时,它们才会被清除掉 2.autovacuum lanucher 负责回收垃圾数据的master进程,如果开启了autovacuum的话,那么0postmaster会fork这个进程 3.autovacuum worker 负责回收垃圾数据的worker进程,是lanucher进程fork出来的0 PgStat 统计数据收集进程 1.此进程主要做数据的统计收集工作 2.收集的信息主要用于查询优化时的代价估算。统计的数据包括对一个表或索引进行的插入、删除、更新操作,磁盘块读写的次数以及行的读次数等。 3.系统表pg statistic中存储了PgStat收集的各类统计信息 PgArch 归档进程 1.默认没有此进程,开启归档功能后才会启动archiver进程。 2.WAL日志文件会被循环使用,也就是说WAL日志会被覆盖,利用PgArch进程会在覆盖前把WAL日志备份出来,类似于binlog,可用于备份功能 3.PostgresQL从8.X版本开始提供了PITR (Point-n-Time-Recovery)技术,即就是在对数据库0进行过一次全量备份后,该技术将备份时间点后面的WAL日志通过归档进行备份,将来可以使用数据库的全量备份再加上后面产生的WAL 日志,即可把数据库向前恢复到全量备份后的任意一个时间点的状态 SysLogger 系统日志进程 1.默认没有此进程,配置文件 postgresql.conf 设置参数logging_collect设置为"on"时,主进程才会启动SysLogger辅助进程 2.它从Postmaster主进程、所有的服务进程以及其他辅助进程收集所有的stderr输出,并将这些输出写入到日志文件中 startup 启动进程 用于数据库恢复的进程 Session 会话进程 每一个用户发起连接后,一旦验证成功,postmaster进程就会fork一个新的子进程负责连接此o用户。 通常表现为进程形式: postgres postgres [local] idleo 10.总结pgsql的数据目录中结构,说明每个文件的作用,并可以配上一些示例说明文件的作用。 postgresql.conf #数据库实例的主配置文件,基本上所有的配置参数都在此文件中 范例: listen_addresses='*' #监听客户端的地址,默认是本地的,需要修改为*或者0.0.0.0 port = 5432 #pg端口,默认是5432 max_connections = 2000 #最大连接数,默认100 unix socket directories #socket文件的位置,默认在/tmp下面 shared_buffers #数据缓存区,建议值1/4--1/2主机内存,和oracle的buffer cache类似maintenance_work_mem #维护工作内存,用于vacuum,create index,reindex等。建议值(1/4主机内存)/autovacuum max workers max_worker_processes #总worker数\ max_parallel_workers_per_gather #单条QUERY中,每个node最多允许开启的并行计算WORKER数wa1_l wal_level #wa1级别,版本11+默认是replica wa1_buffers #类似oracTe的1og buffercheckpoint timeout #checkpoint时间间隔max_wal_size #控制wa1的最大数量 min_wal_size #控制wa1的最小数量 archive command #开启归档命令,示例:'test ! -f /arch/%f && cp %p /arch/%fl autovacuum #开启自动vacuum
10.pg_hba.conf #认证配置文件,配置了允许哪些IP的主机访问数据库,认证的方法是什么等信息
-
范例: pg_ident.conf #认证方式ident的用户映射文件 base #默认表空间的目录,每个数据库都对应一个base目录下的子目录,每个表和索引对应一个独立文件 global #这个目录对应pg_global表空间,存放实例中的共享对象 pg_clog #存储事务提交状态数据 pg_bba.conf #数据库访问控制文件 pg_log #数据库系统日志目录,在查询一些系统错误时就可查看此目录下日志文件。(根据配置定义,可能没有这个目录) pg_xact #提交日志commit 1og的目录,pg 9之前叫pg_clog pg_multixact #共享行锁的事务状态数据 pg_notify #异步消息相关的状态数据 pg_serial #串行隔离级别的事务状态数据 pg_snapshots #存储执行了事务snapshot导出的状态数据 pg_stat_tmp #统计信息的临时文件 pg_subtrans #子事务状态数据 pg_stat #统计信息的存储目录。关闭服务时,将pg_stat_tmp目录中的内容移动至此目录实现保存 pg_stat_tmp #统计信息的临时存储目录。开启数据库时存放统计信息 pg_tblsp #存储了指向各个用户自建表空间实际目录的链接文件 pg_twophase#使用两阶段提交功能时分布式事务的存储目录 pg_wal #wAL日志的目录,早期版本目录为pg_xlog PG VERSION #数据库版本 postmaster.opts #记录数据库启动时的命令行选项 postmaster.pid #数据库启动的主进程信息文件,包括PID,SPGDATA目录,数据库启动时间,监听端口,socket文件路径,临听地址,共享内存的地址信息(ipsc可查看),主进程状态11.尝试将pgsql新版本的运行日志存储到数据库。
-
13版本 [root@ubuntu1804 ~]$vim /pgsql/data/postgresql.conf log_destination = 'csvlog' logging_collector = on # Enable capturing of stderr and csvlog [root@ubuntu1804 ~]$pg_ctl restart CREATE table postgres_log ( log_time timestamp(3) with time zone, user_name text, database_name text, process_id integer, connection_from text, session_id text, session_line_num bigint, command_tag text, session_start_time timestamp with time zone, virtual_transaction_id text, transaction_id bigint, error_severity text, sql_state_code text, message text, detail text, hint text, internal_query text, internal_query_pos integer, context text, query text, query_pos integer, location text, application_name text, backend_type text, PRIMARY KEY (session_id, session_line_num) ) copy postgres_log from '/pgsql/data/log/postgresql-2022-11-30_100805.csv' with csv;12.图文并茂总结LSN和WAL日志相关概念
LSN:Log Sequence Number 用于记录WAL文件当前的记录,这是WAL日志唯一的,全局的标识
WAL日志中写入是有顺序的,所有必须得记录WAL日志的写入顺序,而LSN就是负责给每条产生WAL日志记录唯一的编号

postgres=# select pg_current_wal_lsn(); #当前LSN号
pg_current_wal_lsn
--------------------
0/1AB3F430
(1 row)
postgres=# select pg_walfile_name(pg_current_wal_lsn()); #查看当前LSN对应的WAL的日志文件
pg_walfile_name
--------------------------
00000001000000000000001A
(1 row)
postgres=# select txid_current(); #查看当前事务ID
txid_current
--------------
844
(1 row)
13.实现WAL日志多种类型的备份,及数据还原。
[root@ubuntu1804 ~]$vim /pgsql/data/postgresql.conf
archive_mode = on # enables archiving; off, on, or always
# (change requires restart)
archive_command = '[ ! -f /mnt/server/archivedir/%f ] && cp %p /archive/%f'
mkdir /archive
chown postgre. /archive
pg_ctl restart
数据还原
[root@rocky ~]#pg_dump -h10.0.0.180 -U postgres -f /backup/hellodb hellodb
[root@ubuntu1804 ~]$psql
psql (14.2)
Type "help" for help.
postgres=# create database hellodb2;
[root@rocky ~]#psql -h 10.0.0.180 -U postgres -f /backup/hellodb -d helldb2
[root@rocky ~]#pg_dump -h10.0.0.180 -U postgres -C -f /backup/hellodb hellodb
[root@rocky ~]#pg_dump -Fc -h10.0.0.180 -U postgres hellodb > /backup/hellodb.dump
Password:
[root@rocky ~]#pg_restore -h10.0.0.180 -U postgres -d hellodb3 /backup/hellodb.dump
PITR
[root@ubuntu1804 ~]$vim /pgsql/data/pg_hba.conf
# TYPE DATABASE USER ADDRESS METHOD
local replication all trust
host replication all 127.0.0.1/32 trust
host replication all 0.0.0.0/0 md5
pg_ctl restart
mkdir /pgsql/backup/
chown -R posgres. /pgsql/backup
pg_basebackup -D /pgsql/backup -Ft -Pv -U postgres -h 10.0.0.180 -R
rm /archive/*
su - postgres
pg_ctl stop
rm -rf /pgsql/data/*
chown -R postgres. /pgsql/backup/
chmod 700 /pgsql/data/
su - postgres
tar xf /pgsql/backup/base.tar -C /pgsql/data/
tar xf /pgsql/backup/pg_wal.tar -C /archive/
vim /pgsql/data/postgresql.conf
restore_command = 'cp /archive/%f %p' # command to use to restore an archived
recovery_target = 'immediate'
pg_ctl start -D /pgsql/data/10.0.0.180
hellodb=# \c db1
You are now connected to database "db1" as user "postgres".
db1=# create table t1 (id int);
CREATE TABLE
db1=# insert into t1 values(2);
INSERT 0 1
db1=# insert into t1 values(1);
INSERT 0 1
db1=# insert into t1 values(3);
INSERT 0 1
db1=# \c hellodb;
You are now connected to database "hellodb" as user "postgres".
hellodb=# drop database db1;
DROP DATABASE
hellodb=# select pg_walfile_name(pg_current_wal_lsn());
pg_walfile_name
--------------------------
00000001000000000000002A
(1 row)
hellodb=# select pg_walfile_name(pg_current_wal_lsn());
pg_walfile_name
--------------------------
00000001000000000000002A
(1 row)
hellodb=# select txid_current();
txid_current
--------------
924
(1 row)
hellodb=# select pg_switch_wal();
pg_switch_wal
---------------
0/2A019D50
(1 row)
10.0.0.18
[postgres@rocky ~]$pg_ctl stop
waiting for server to shut down.... done
server stopped
[postgres@rocky ~]$rm -rf /pgsql/data/*
[postgres@rocky ~]$rm -rf /archive/*
[postgres@rocky ~]pg_basebackup -D /pgsql/backup -Ft -Pv -U postgres -h 10.0.0.180 -R
[root@rocky backup]#chown -R postgres. /pgsql/backup/
[root@rocky backup]#su - postgres
[postgres@rocky ~]$tar xf /pgsql/backup/base.tar -C /pgsql/data/
[postgres@rocky ~]$tar xf /pgsql/backup/pg_wal.tar -C /archive/
[root@rocky ~]#rsync -a 10.0.0.180:/archive/ /archive/
[root@rocky ~]#pg_waldump /archive/00000001000000000000001E
rmgr: Database len (rec/tot): 38/ 38, tx: 923, lsn: 0/2A019C30, prev 0/2A019BB8, desc: DROP dir 1663/32978
[postgres@rocky ~]$vim /pgsql/data/postgresql.conf
restore_command = 'cp /archive/%f %p'
recovery_target_xid = '922'
pg_ctl start -D /pgsql/data/
select pg_wal_replay_resume();14.实现WAL日志完成主从流复制,要求在从节点上进行crontab数据备份,同时手工让主节点宕机,让从节点切换为主节点,并添加新的从节点。
流复制
10.0.0.200 master
postgres=# create role repluser with replication login password '123456';
postgres@ubuntu1804:~$ vim /pgsql/data/pg_hba.conf
# TYPE DATABASE USER ADDRESS METHOD
host replication all 0.0.0.0/0 md5
postgres@ubuntu1804:~$ pg_ctl restart10.0.0.18 slave
[postgres@rocky ~]$pg_ctl stop -D /pgsql/data/
[postgres@rocky ~]$rm -rf /pgsql/data/*
[postgres@rocky ~]$rm -rf /archive/*
[postgres@rocky ~]$rm -rf /pgsql/backup/*
[postgres@rocky ~]$pg_basebackup -D /pgsql/backup -Ft -Pv -U postgres -h 10.0.0.180 -R
[postgres@rocky ~]$tar xf /pgsql/backup/base.tar -C /pgsql/data/
[postgres@rocky ~]$tar xf /pgsql/backup/pg_wal.tar -C /archive/
[postgres@rocky ~]$vim /pgsql/data/postgresql.conf
restore_command = 'cp /archive/%f %p'
primary_conninfo = 'host=10.0.0.180 port=5432 user=repluser password=123456'
[postgres@rocky ~]$pg_ctl start -D /pgsql/data/
在从节点上进行crontab数据备份
[root@18 ~]#crontab -e
no crontab for root - using an empty one
0 0 * * * bash /root/pg_backup.sh
#!/bin/bash
DIR=/data/backup-`date +%F`
[ -d $DIR ] || mkdir -p $DIR
expect <<EOF
set timeout 20
spawn pg_basebackup -D $DIR -Ft -Pv -U postgres -h 10.0.0.180 -R
expect {
"Password" { send "123456\n" }
}
expect eof
EOF
pg_ctl promote #将从节点提升为主节点添加新的从节点
postgres@180:~$ pg_ctl stop
postgres@180:~$ rm -rf /pgsql/data/*
postgres@180:~$ rm -rf /archive/*
postgres@180:~$ mkdir /pgsql/backup
postgres@180:~$ pg_basebackup -D /pgsql/backup -Ft -Pv -U postgres -h 10.0.0.18 -R
postgres@180:~$ tar xf /pgsql/backup/base.tar -C /pgsql/data/
postgres@180:~$ tar xf /pgsql/backup/pg_wal.tar -C /archive/
postgres@180:~$ vim /pgsql/data/postgresql.conf
restore_command = 'cp /archive/%f %p'
primary_conninfo = 'host=10.0.0.18 port=5432 user=repluser password=123456'
postgres@180:~$ pg_ctl start -D /pgsql/data/15.总结日志记录的内容包含什么
日志记录的内容包括: 历史事件:时间,地点,人物,事件 日志级别:事件的关键性程度,Loglevel
16.总结日志分类, 优先级别。图文并茂解释应用如何将日志发到rsyslog,并写到目标。
facility:设施,从功能或程序上对日志进行归类
#内置分类 auth, authpriv, cron, daemon,ftp,kern, lpr, mail, news, security(auth), user, uucp, syslog #自定义的分类 local0-local7
Priority 优先级别,从低到高排序
debug,info, notice, warn(warning), err(error), crit(critical), alert, emerg(panic)

应用程序发生一个事件通过rsyslog记录在文件或数据库中,也可以通过邮件发送给别人。
rsyslog 特性:
多线程
UDP, TCP, SSL, TLS, RELP
MySQL, PGSQL, Oracle实现日志存储
强大的过滤器,可实现过滤记录日志信息中任意部分
自定义输出格式
适用于企业级中继链
17.总结rsyslog配置文件格式
/etc/rsyslog.conf配置文件格式:由三部分组成
MODULES:相关模块配置
GLOBAL DIRECTIVES:全局配置
RULES:日志记录相关的规则配置
*RULES*配置格式:
facility.priority; facility.priority… target
*facility*格式:
* #所有的facility facility1,facility2,facility3,... #指定的facility列表
*priority*格式:
*: 所有级别 none:没有级别,即不记录 PRIORITY:指定级别 (含) 以上的所有级别=PRIORITY:仅记录指定级别的日志信息
*target*格式:
文件路径:通常在/var/log/,文件路径前的-表示异步写入 用户:将日志事件通知给指定的用户,* 表示登录的所有用户 日志服务器:@host,把日志送往至指定的远程UDP日志服务器 @@host 将日志发送到远程TCP日志服务器 管道: | COMMAND,转发给其它命令处理
18.完成功能,sshd应用将日志写到rsyslog的local6分类,过滤所有级别,写入到/var/log/ssh.log。
[root@rocky ~]#vim /etc/ssh/sshd_config # Logging #SyslogFacility AUTH SyslogFacility LOCAL6 #SyslogFacility AUTHPRIV [root@rocky ~]#vim /etc/rsyslog.d/test.conf local6.* /var/log/ssh.log ~ [root@rocky ~]#systemctl restart sshd rsyslog.service
19.完成功能,将3个主机(要求主机名为ip)的ssh日志,通过rsyslog服务将ssh日志写入到集中的主机上的rsyslog服务,写入到/var/log/all-ssh.log文件
[root@18 ~]##vim /etc/rsyslog.conf module(load="imudp") # needs to be done just once input(type="imudp" port="514") local6.* /var/log/ssh.log [root@180 ~]$systemctl restart rsyslog.service
[root@8 ~]##vim /etc/ssh/sshd_config # Logging #SyslogFacility AUTH SyslogFacility LOCAL6 #SyslogFacility AUTHPRIV [root@8 ~]##vim /etc/rsyslog.d/test.conf local6.* /var/log/ssh.log local6.* @10.0.0.18:514 [root@8 ~]##systemctl restart sshd rsyslog.service
[root@180 ~]$vim /etc/rsyslog.d/50-default.conf *.*;auth,authpriv.none @10.0.0.18:514 [root@180 ~]$systemctl restart rsyslog.service
20.总结/var/log/目录下常用日志文件作用。
/var/log/secure:系统安全日志,文本格式,应周期性分析 /var/log/btmp:当前系统上,用户的失败尝试登录相关的日志信息,二进制格式,lastb命令进行 查看 /var/log/wtmp:当前系统上,用户正常登录系统的相关日志信息,二进制格式,last命令可以查看 /var/log/lastlog:每一个用户最近一次的登录信息,二进制格式,lastlog命令可以查看 /var/log/dmesg:CentOS7 之前版本系统引导过程中的日志信息,文本格式,开机后的硬件变化 将不再记录,也可以通过专用命令dmesg查看,可持续记录硬件变化的情况 /var/log/boot.log 系统服务启动的相关信息,文本格式 /var/log/messages :系统中大部分的信息 /var/log/anaconda : anaconda的日志
21.总结journalctl命令的选项及示例
--no-full, --full, -l 如果字段内容超长则以省略号(...)截断以适应列宽。 默认显示完整的字段内容(超长的部分换行显示或者被分页工具截断)。 老旧的 -l/--full 选项 仅用于撤销已有的 --no-full 选项,除此之外没有其他用处。 -a, --all 完整显示所有字段内容, 即使其中包含不可打印字符或者字段内容超长。 -f, --follow 只显示最新的日志项,并且不断显示新生成的日志项。 此选项隐含了 -n 选项。 -e, --pager-end 在分页工具内立即跳转到日志的尾部。 此选项隐含了 -n1000 以确保分页工具不必缓存太多的日志行。 不过这个隐含的行数可以被明确设置的 -n 选项覆盖。 注意,此选项仅可用于 less(1) 分页器。 -n, --lines= 限制显示最新的日志行数。 --pager-end 与 --follow 隐含了此选项。 此选项的参数:若为正整数则表示最大行数; 若为 "all" 则表示不限制行数; 若不设参数则表示默认值10行。 --no-tail 显示所有日志行, 也就是用于撤销已有的 --lines= 选项(即使与 -f 连用)。 -r, --reverse 反转日志行的输出顺序, 也就是最先显示最新的日志。 -o, --output= 控制日志的输出格式。 可以使用如下选项: short 这是默认值, 其输出格式与传统的 syslog[1] 文件的格式相似, 每条日志一行。 short-iso 与 short 类似,只是将时间戳字段以 ISO 8601 格式显示。 short-precise 与 short 类似,只是将时间戳字段的秒数精确到微秒级别。 short-monotonic 与 short 类似,只是将时间戳字段的零值从内核启动时开始计算。 short-unix 与 short 类似,只是将时间戳字段显示为从"UNIX时间原点"(1970-1-1 00:00:00 UTC)以来的秒数。 精确到微秒级别。 verbose 以结构化的格式显示每条日志的所有字段。 export 将日志序列化为二进制字节流(大部分依然是文本) 以适用于备份与网络传输(详见 Journal Export Format[2] 文档)。 json 将日志项按照JSON数据结构格式化, 每条日志一行(详见 Journal JSON Format[3] 文档)。 json-pretty 将日志项按照JSON数据结构格式化, 但是每个字段一行, 以便于人类阅读。 json-sse 将日志项按照JSON数据结构格式化,每条日志一行,但是用大括号包围, 以适应 Server-Sent Events[4] 的要求。 cat 仅显示日志的实际内容, 而不显示与此日志相关的任何元数据(包括时间戳)。 --utc 以世界统一时间(UTC)表示时间 --no-hostname 不显示来源于本机的日志消息的主机名字段。 此选项仅对 short 系列输出格式(见上文)有效。 -x, --catalog 在日志的输出中增加一些解释性的短文本, 以帮助进一步说明日志的含义、 问题的解决方案、支持论坛、 开发文档、以及其他任何内容。 并非所有日志都有这些额外的帮助文本, 详见 Message Catalog Developer Documentation[5] 文档。 注意,如果要将日志输出用于bug报告, 请不要使用此选项。 -q, --quiet 当以普通用户身份运行时, 不显示任何警告信息与提示信息。 例如:"-- Logs begin at ...", "-- Reboot --" -m, --merge 混合显示包括远程日志在内的所有可见日志。 -b [ID][±offset], --boot=[ID][±offset] 显示特定于某次启动的日志, 这相当于添加了一个 "_BOOT_ID=" 匹配条件。 如果参数为空(也就是 ID 与 ±offset 都未指定), 则表示仅显示本次启动的日志。 如果省略了 ID , 那么当 ±offset 是正数的时候, 将从日志头开始正向查找, 否则(也就是为负数或零)将从日志尾开始反响查找。 举例来说, "-b 1"表示按时间顺序排列最早的那次启动, "-b 2"则表示在时间上第二早的那次启动; "-b -0"表示最后一次启动, "-b -1"表示在时间上第二近的那次启动, 以此类推。 如果 ±offset 也省略了, 那么相当于"-b -0", 除非本次启动不是最后一次启动(例如用 --directory 指定了另外一台主机上的日志目录)。 如果指定了32字符的 ID , 那么表示以此 ID 所代表的那次启动为基准 计算偏移量(±offset), 计算方法同上。 换句话说, 省略 ID 表示以本次启动为基准 计算偏移量(±offset)。 --list-boots 列出每次启动的 序号(也就是相对于本次启动的偏移量)、32字符的ID、 第一条日志的时间戳、最后一条日志的时间戳。 -k, --dmesg 仅显示内核日志。隐含了 -b 选项以及 "_TRANSPORT=kernel" 匹配项。 -t, --identifier=SYSLOG_IDENTIFIER 仅显示 syslog[1] 识别符为 SYSLOG_IDENTIFIER 的日志项。 可以多次使用该选项以指定多个识别符。 -u, --unit=UNIT|PATTERN 仅显示属于特定单元的日志。 也就是单元名称正好等于 UNIT 或者符合 PATTERN 模式的单元。 这相当于添加了一个 "_SYSTEMD_UNIT=UNIT" 匹配项(对于 UNIT 来说), 或一组匹配项(对于 PATTERN 来说)。 可以多次使用此选项以添加多个并列的匹配条件(相当于用"OR"逻辑连接)。 --user-unit= 仅显示属于特定用户会话单元的日志。 相当于同时添加了 "_SYSTEMD_USER_UNIT=" 与 "_UID=" 两个匹配条件。 可以多次使用此选项以添加多个并列的匹配条件(相当于用"OR"逻辑连接)。 -p, --priority= 根据日志等级(包括等级范围)过滤输出结果。 日志等级数字与其名称之间的对应关系如下 (参见 syslog(3)): "emerg" (0), "alert" (1), "crit" (2), "err" (3), "warning" (4), "notice" (5), "info" (6), "debug" (7) 。 若设为一个单独的数字或日志等级名称, 则表示仅显示小于或等于此等级的日志 (也就是重要程度等于或高于此等级的日志)。 若使用 FROM..TO.. 设置一个范围, 则表示仅显示指定的等级范围内(含两端)的日志。 此选项相当于添加了 "PRIORITY=" 匹配条件。 -c, --cursor= 从指定的游标(cursor)开始显示日志。 [提示]每条日志都有一个"__CURSOR"字段,类似于该条日志的指纹。 --after-cursor= 从指定的游标(cursor)之后开始显示日志。 如果使用了 --show-cursor 选项, 则也会显示游标本身。 --show-cursor 在最后一条日志之后显示游标, 类似下面这样,以"--"开头: -- cursor: s=0639... 游标的具体格式是私有的(也就是没有公开的规范), 并且会变化。 -S, --since=, -U, --until= 显示晚于指定时间(--since=)的日志、显示早于指定时间(--until=)的日志。 参数的格式类似 "2012-10-30 18:17:16" 这样。 如果省略了"时:分:秒"部分, 则相当于设为 "00:00:00" 。 如果仅省略了"秒"的部分则相当于设为 ":00" 。 如果省略了"年-月-日"部分, 则相当于设为当前日期。 除了"年-月-日 时:分:秒"格式, 参数还可以进行如下设置: (1)设为 "yesterday", "today", "tomorrow" 以表示那一天的零点(00:00:00)。 (2)设为 "now" 以表示当前时间。 (3)可以在"年-月-日 时:分:秒"前加上 "-"(前移) 或 "+"(后移) 前缀以表示相对于当前时间的偏移。 关于时间与日期的详细规范, 参见 systemd.time(7) -F, --field= 显示所有日志中某个字段的所有可能值。 [译者注]类似于SQL语句:"SELECT DISTINCT 某字段 FROM 全部日志" -N, --fields 输出所有日志字段的名称 --system, --user 仅显示系统服务与内核的日志(--system)、 仅显示当前用户的日志(--user)。 如果两个选项都未指定,则显示当前用户的所有可见日志。 -M, --machine= 显示来自于正在运行的、特定名称的本地容器的日志。 参数必须是一个本地容器的名称。 -D DIR, --directory=DIR 仅显示来自于特定目录中的日志, 而不是默认的运行时和系统日志目录中的日志。 --file=GLOB GLOB 是一个可以包含"?"与"*"的文件路径匹配模式。 表示仅显示来自与指定的 GLOB 模式匹配的文件中的日志, 而不是默认的运行时和系统日志目录中的日志。 可以多次使用此选项以指定多个匹配模式(多个模式之间用"OR"逻辑连接)。 --root=ROOT 在对日志进行操作时, 将 ROOT 视为系统的根目录。 例如 --update-catalog 将会创建 ROOT/var/lib/systemd/catalog/database --new-id128 此选项并不用于显示日志内容, 而是用于重新生成一个标识日志分类的 128-bit ID 。 此选项的目的在于 帮助开发者生成易于辨别的日志消息, 以方便调试。 --header 此选项并不用于显示日志内容, 而是用于显示日志文件内部的头信息(类似于元数据)。 --disk-usage 此选项并不用于显示日志内容, 而是用于显示所有日志文件(归档文件与活动文件)的磁盘占用总量。 --vacuum-size=, --vacuum-time=, --vacuum-files= 这些选项并不用于显示日志内容, 而是用于清理日志归档文件(并不清理活动的日志文件), 以释放磁盘空间。 --vacuum-size= 可用于限制归档文件的最大磁盘使用量 (可以使用 "K", "M", "G", "T" 后缀); --vacuum-time= 可用于清除指定时间之前的归档 (可以使用 "s", "m", "h", "days", "weeks", "months", "years" 后缀); --vacuum-files= 可用于限制日志归档文件的最大数量。 注意,--vacuum-size= 对 --disk-usage 的输出仅有间接效果, 因为 --disk-usage 输出的是归档日志与活动日志的总量。 同样,--vacuum-files= 也未必一定会减少日志文件的总数, 因为它同样仅作用于归档文件而不会删除活动的日志文件。 此三个选项可以同时使用,以同时从三个维度去限制归档文件。 若将某选项设为零,则表示取消此选项的限制。 --list-catalog [128-bit-ID...] 简要列出日志分类信息, 其中包括对分类信息的简要描述。 如果明确指定了分类ID(128-bit-ID), 那么仅显示指定的分类。 --dump-catalog [128-bit-ID...] 详细列出日志分类信息 (格式与 .catalog 文件相同)。 如果明确指定了分类ID(128-bit-ID), 那么仅显示指定的分类。 --update-catalog 更新日志分类索引二进制文件。 每当安装、删除、更新了分类文件,都需要执行一次此动作。 --setup-keys 此选项并不用于显示日志内容, 而是用于生成一个新的FSS(Forward Secure Sealing)密钥对。 此密钥对包含一个"sealing key"与一个"verification key"。 "sealing key"保存在本地日志目录中, 而"verification key"则必须保存在其他地方。 详见 journald.conf(5) 中的 Seal= 选项。 --force 与 --setup-keys 连用, 表示即使已经配置了FSS(Forward Secure Sealing)密钥对, 也要强制重新生成。 --interval= 与 --setup-keys 连用,指定"sealing key"的变化间隔。 较短的时间间隔会导致占用更多的CPU资源, 但是能够减少未检测的日志变化时间。 默认值是 15min --verify 检查日志文件的内在一致性。 如果日志文件在生成时开启了FSS特性, 并且使用 --verify-key= 指定了FSS的"verification key", 那么,同时还将验证日志文件的真实性。 --verify-key= 与 --verify 选项连用, 指定FSS的"verification key" --sync 要求日志守护进程将所有未写入磁盘的日志数据刷写到磁盘上, 并且一直阻塞到刷写操作实际完成之后才返回。 因此该命令可以保证当它返回的时候, 所有在调用此命令的时间点之前的日志, 已经全部安全的刷写到了磁盘中。 --flush 要求日志守护进程 将 /run/log/journal 中的日志数据 刷写到 /var/log/journal 中 (如果持久存储设备当前可用的话)。 此操作会一直阻塞到操作完成之后才会返回, 因此可以确保在该命令返回时, 数据转移确实已经完成。 注意,此命令仅执行一个单独的、一次性的转移动作, 若没有数据需要转移, 则此命令什么也不做, 并且也会返回一个表示操作已正确完成的返回值。 --rotate 要求日志守护进程滚动日志文件。 此命令会一直阻塞到滚动完成之后才会返回。 -h, --help 显示简短的帮助信息并退出。 --version 显示简短的版本信息并退出。 --no-pager 不将程序的输出内容管道(pipe)给分页程序
#查看所有日志(默认情况下 ,只保存本次启动的日志) journalctl #查看内核日志(不显示应用日志) journalctl -k #查看系统本次启动的日志 journalctl -b journalctl -b -0 #查看上一次启动的日志(需更改设置) journalctl -b -1 #查看指定时间的日志 journalctl --since="2017-10-30 18:10:30" journalctl --since "20 min ago" journalctl --since yesterday journalctl --since "2017-01-10" --until "2017-01-11 03:00" journalctl --since 09:00 --until "1 hour ago" #显示尾部的最新10行日志 journalctl -n #显示尾部指定行数的日志 journalctl -n 20 #实时滚动显示最新日志 journalctl -f #查看指定服务的日志 journalctl /usr/lib/systemd/systemd #查看指定进程的日志 journalctl _PID=1 #查看某个路径的脚本的日志 journalctl /usr/bin/bash #查看指定用户的日志 journalctl _UID=33 --since today #查看某个 Unit 的日志 journalctl -u nginx.service journalctl -u nginx.service --since today #实时滚动显示某个 Unit 的最新日志 journalctl -u nginx.service -f #合并显示多个 Unit 的日志 journalctl -u nginx.service -u php-fpm.service --since today #查看指定优先级(及其以上级别)的日志,共有8级 0: emerg 1: alert 2: crit 3: err 4: warning 5: notice 6: info 7: debug journalctl -p err -b #日志默认分页输出,--no-pager 改为正常的标准输出 2 实战案例:利用 MySQL 存储日志信息 2.1 目标 利用rsyslog日志服务,将收集的日志记录于MySQL中 2.2 环境准备 2.3 实现步骤 2.3.1 在rsyslog服务器上安装连接mysql模块相关的程序包 journalctl --no-pager #日志管理journalctl #以 JSON 格式(单行)输出 journalctl -b -u nginx.service -o json #以 JSON 格式(多行)输出,可读性更好 journalctl -b -u nginx.service -o json-pretty #显示日志占据的硬盘空间 journalctl --disk-usage #指定日志文件占据的最大空间 journalctl --vacuum-size=1G
#指定日志文件保存多久 journalctl --vacuum-time=1years
22.完成将多个主机(要求主机名为ip)的nginx日志集中写入到mysql表中
环境:4台主机 10.0.0.8 10.0.0.180 10.0.0.18接受8和18的日志, 28为mysql
[root@180 ~]$vim /etc/rsyslog.d/50-default.conf *.*;auth,authpriv.none -/var/log/syslog *.*;auth,authpriv.none @10.0.0.18:514 systemctl restart rsyslog.service [root@180 ~]$apt -y install nginx [root@180 ~]$systemctl enable --now nginx
[root@8 ~]#vim /etc/rsyslog.d/test.conf local6.* /var/log/ssh.log *.info @10.0.0.18:514 [root@8 ~]#vim /etc/ssh/sshd_config #SyslogFacility AUTH SyslogFacility LOCAL6 systemctl restart sshd rsyslog.service [root@8 ~]#yum -y install nginx [root@8 ~]#systemctl enable --now nginx.service
10.0.0.18 [root@18 ~]#yum -y install rsyslog-mysql [root@18 ~]#scp /usr/share/doc/rsyslog/mysql-createDB.sql 10.0.0.28: [root@18 ~]#vim /etc/rsyslog.conf module(load="ommysql") *.info;mail.none;authpriv.none;cron.none /var/log/messages *.info;mail.none;authpriv.none;cron.none :ommysql:10.0.0.28,Syslog,rsyslog,123456
10.0.0.28 [root@mycat ~]#yum -y install mysql-server [root@mycat ~]#systemctl enable --now mysqld mysql> create user rsyslog@'10.0.0.%' identified by '123456'; Query OK, 0 rows affected (0.00 sec) mysql> grant all on Syslog.* to rsyslog@'10.0.0.%'; Query OK, 0 rows affected (0.00 sec) mysql> source /root/mysql-createDB.sql
22.尝试使用logrotate服务切割nginx日志,每天切割一次,要求大于不超过3M, 保存90天的日志, 旧日志以时间为后缀,要求压缩。
[root@8 ~]#vim /etc/logrotate.d/nginx
/var/log/nginx/*log {
create 0664 nginx root
daily
rotate 90
missingok
notifempty
compress
delaycompress
size 3M
sharedscripts
postrotate
/bin/kill -USR1 `cat /run/nginx.pid 2>/dev/null` 2>/dev/null || true
echo `date +%F_%T` >> nginx.log
endscript
}
23.总结DAS, NAS, SAN区别,使用场景
| DAS | NAS | SAN | |
|---|---|---|---|
| 传输类型 | SCSI,FC | IP | IP,FC,SAS |
| 数据类型 | 数据块 | 文件 | 数据块 |
| 典型应用 | 任何 | 文件服务器 | 数据库应用 |
| 优点 | 磁盘与服务器分离,便于统一管理 | 不占用应用服务器资源,广泛支持操作系统,扩展较容易,即插即用,安装简单方便 | 高扩展性,高可用性,数据集中,易管理 |
| 缺点 | 连接距离远,数据分散,共享困难,存储空间利用率不高,扩展性有限 | 不适合存储量大的块级应用数据备份即恢复占用网络带宽 | 相比NAS成本较高安装和升级比NAS复杂 |
三种存储架构的应用场景
DAS虽然比较古老了,但是还是很适用于那些数据量不大,对磁盘访问速度要求较高的中小企业NAS多适用于文件服务器,用来存储非结构化数据,虽然受限于以太网的速度,但是部署灵活,成
本低
SAN则适用于大型应用或数据库系统,缺点是成本高、较为复杂
24.完成 文件同步和LAMP架构实现负载均衡实战案例
7 dns 18 lmp 28 mysql 8tongb
48 DNS
[root@localhost ~]#vim /etc/named.conf
// listen-on port 53 { 127.0.0.1; };
// allow-query { localhost; };
[root@localhost ~]#vim /etc/named.rfc1912.zones
zone "gaojingjun.org" {
type master;
file "gaojingjun.org.zone";
[root@localhost ~]#vim /var/named/gaojingjun.org.zone
$TTL 1D
@ IN SOA master admin.gaojingjun.org ( 1 ; serial
1D ; refresh
1H ; retry
1W ; expire
3H ) ; minimum
NS master
master A 10.0.0.48
www A 10.0.0.58
[root@localhost ~]#systemctl restart named
[root@localhost ~]#vim /var/named/gaojingjun.org.zone
$TTL 1D
@ IN SOA master admin.gaojingjun.org ( 1 ; serial
1D ; refresh
1H ; retry
1W ; expire
3H ) ; minimum
NS master
master A 10.0.0.48
www A 10.0.0.58
www A 10.0.0.28
[root@localhost ~]#rndc reload
58 LMP WORDPRESS
[root@slave1 ~]#yum -y install httpd php php-mysqlnd php-json
[root@slave1 ~]#unzip wordpress-6.1.1-zh_CN.zip
[root@slave1 ~]#mv wordpress/* /var/www/html/
[root@slave1 ~]#chown apache. /var/www/html/ -R
[root@slave1 wp-content]#yum -y install nfs-utils
[root@slave1 wp-content]#showmount -e 10.0.0.8
Export list for 10.0.0.8:
/data/www *
[root@slave1 wp-content]#scp -r /var/www/html/wp-content/uploads/ 10.0.0.8:/data/www
[root@slave1 wp-content]#vim /etc/fstab
/dev/mapper/rl-swap none swap defaults 0 0
10.0.0.8:/data/www /var/www/html/wp-content/uploads nfs _netdev 0 0
[root@slave1 wp-content]#mount -a
68 mysql
mysql> create user wordpress@'10.0.0.%' identified by '123456';
Query OK, 0 rows affected (0.00 sec)
mysql> grant all on wordpress.* to wordpress@'10.0.0.%';
8 同步
[root@8 ~]#mkdir /data/www
[root@8 ~]#useradd -u 666 www
[root@8 ~]#vim /etc/exports
/data/www *(rw,all_squash,anonuid=666,anongid=666)
[root@8 ~]#mv /data/www/uploads/* /data/www/
[root@8 ~]#cd /data/www/
[root@8 ~]#chown www.www /data/www
[root@8 ~]#yum -y install nfs-utils
[root@8 www]#chown -R www.www .
[root@8 www]#vim /etc/rsync.pas
123456
[root@8 ~]#tar xf sersync2.5.4_64bit_binary_stable_final.tar.gz
[root@8 GNU-Linux-x86]#vim confxml.xml
<remote ip="10.0.0.18" name="backup"/>
<!--<remote ip="192.168.8.39" name="tongbu"/>-->
<!--<remote ip="192.168.8.40" name="tongbu"/>-->
</localpath>
<rsync>
<commonParams params="-artuz"/>
<auth start="true" users="rsyncuser" passwordfile="/etc/rsync.pas"/>
[root@8 GNU-Linux-x86]#./sersync2 -dro confxml.xml
28 lmp2
[root@mycat ~]#yum -y install nfs-utils
[root@mycat ~]#vim /etc/fstab
/dev/mapper/cl-swap none swap defaults 0 0
10.0.0.8:/data/www /var/www/html/wp-content/uploads nfs _netdev 0 0
[root@mycat ~]#mount -a
主机18 rsync 数据同步10.0.0.8
[root@18 ~]#vim /etc/rsync.pas
rsyncuser:123456
[root@18 ~]#cd /data/backup/
[root@18 backup]#ll
total 0
drwxr-xr-x 3 666 1002 16 Dec 1 19:30 2022
-rw-r--r-- 1 root root 0 Dec 1 20:36 a.txt
25.总结 Redis多种安装方法和内核参数优化
二进制包安装
centos
yum -y install redis
ubuntu
apt -y instll redis
编译安装
[root@18 ~]#wget https://download.redis.io/releases/redis-6.2.7.tar.gz
[root@18 ~]#tar xf redis-6.2.7.tar.gz
[root@18 ~]#cd redis-6.2.7/
[root@18 redis-6.2.7]#make -j 2 USE_SYSTEMD=yes PREFIX=/apps/redis install
[root@18 redis-6.2.7]#echo 'PATH=/apps/redis/bin:$PATH' > /etc/profile.d/redis.sh
[root@18 redis-6.2.7]#. /etc/profile.d/redis.sh
[root@18 redis-6.2.7]#mkdir /apps/redis/{data,etc,run,log}
[root@18 redis-6.2.7]#tree /apps/redis
[root@18 redis-6.2.7]#cp redis.conf /apps/redis/etc/
[root@18 ~]#vim /etc/sysctl.conf
net.core.somaxconn=511
vm.overcommit_memory = 1
[root@18 redis-6.2.7]#sysctl -p
26.总结 Redis 常见指令和数据类型
常见指令
INFO #显示当前节点redis运行状态信息 redis info server SELECT #切换数据库 SELECT 1 KEYS #查看当前数据库所有KEY SELECT 0 KEYS * KEYS *o* KEYS t?? KEYS t[w]* BGSAVE #手动在后台执行RDB持久化操作 redis -cli -h 127.0.0.1 BGSAVE DBSIZE #返回当前库下的所有key数量 FLUSHDB #清空库中所有key FLUSHALL #删除所有数据 SHUTDOWN #关闭redis服务,停止所有客户端连接
redis数据类型
1.字符串 string 2.列表 list 3.集合 sets 4.有序集合 sorted sets 5.哈希 hash