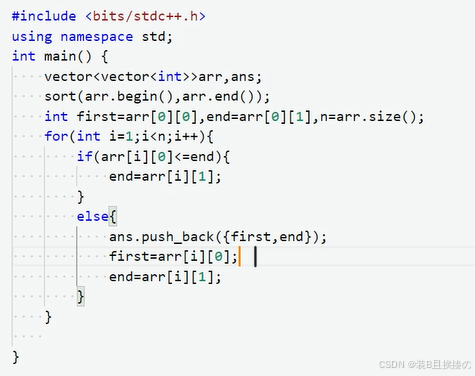
进程间通信方式有哪些
1、管道通信,分为匿名管道和有名管道,匿名管道只能在有亲缘关系如父子进程间使用。有名管道可以允许无亲缘关系进程间的通信。它们都是半双工的通信方式,数据只能单向流动。
2、消息队列,用内核中的链表实现,可以实现任意进程间的异步通信。但是涉及频繁的用户内核态切换。
3、共享内存,一个线程创建共享内存,多个线程可以访问,速度最快,但需要额外同步机制
4、信号量,用于进程同步的机制,可以防止多个进程访问共享内存数据不一致情况。
5、Socket,可用于跨主机不同进程间通信,支持TCP、UDP等,支持异步通信。
6、信号:对于异常的进程,可以用信号来处理,比如终止进程。
7、RPC:允许一个进程调用另一个网络进程的过程或函数,隐藏了复杂的网络编程。
客户端和服务端通信,会用什么方式
WebSocket
WebSocket基于什么协议
HTTP协议
WebSocket和Socket是一样的吗,之间有什么区别和联系
不一样,WebSocket基于HTTP,是应用层协议,Socket基于TCP或UDP,是传输层协议。
WebSocket过程是先进行一次HTTP连接,再升级为WebSocket协议。
Socket一般基于TCP,建立三次握手后传输数据。
WebSocket有加密,Socket明文。
WebSocket一般用于聊天室、实时协作等,Socket用于传统客户端和服务器、P2P等。
HTTP的502和504分别代表什么,有什么区别
502代表网关错误,504表示网关超时。
502一般是后端服务器出错或nginx配置出错,nginx无法从后端获得响应。
504表示nginx无法及时获得后端服务器响应,可能网络延迟或连接不稳定。
HTTP的POST请求的报文内容
请求行
POST请求的报文内容通常包括请求行、请求头部(Headers)和请求体(Body)三个部分。
POST /resource HTTP/1.1 这里,
/resource表示请求的资源路径,而HTTP/1.1指的是HTTP协议的版本。请求头部(Headers)
请求头部包含了若干键值对,用于提供关于请求或响应的附加信息。对于POST请求,常见的请求头部包括:
Content-Type:指示请求体的媒体类型(MIME类型)。对于表单数据,它通常是application/x-www-form-urlencoded;对于JSON数据,它通常是application/json;对于上传文件,则可能是multipart/form-data。Content-Length:请求体的长度,以字节为单位。Accept:告诉服务器客户端能够接收的内容类型。Authorization:包含认证信息,如令牌(Token)等。请求体(Body)
请求体是POST请求中真正携带的数据部分。根据
Content-Type的不同,请求体的格式也会有所不同。
application/x-www-form-urlencoded:这是最常见的表单数据提交方式。数据被编码为类似
key1=value1&key2=value2的形式。例如,如果表单中有两个字段,分别是name和age,则请求体可能看起来像这样:name=John+Doe&age=30。注意,空格被编码为+,特殊字符(如&、=、空格等)被百分号编码。application/json:在这种情况下,请求体是JSON格式的数据。例如:
{"name": "John Doe", "age": 30}。这种方式常用于API调用,因为它易于阅读和解析。multipart/form-data:这种类型用于文件上传。请求体被分为多个部分,每个部分都是表单的一个字段。文件内容会以二进制形式直接包含在请求体中,并带有适当的MIME类型和其他信息。
POST /api/user HTTP/1.1Host: example.comContent-Type: application/jsonContent-Length: 44{"name": "John Doe", "age": 30}
HTTP协议和TCP协议的区别与联系
区别
- 层级不同:
- TCP(传输控制协议)是传输层协议,它负责在网络上可靠地传输数据。
- HTTP(超文本传输协议)是应用层协议,用于在客户端和服务器之间传输超文本文档,如HTML页面、图片、视频等。
- 功能不同:
- TCP提供数据的可靠传输,包括数据分割、流量控制、拥塞控制和错误恢复等功能,确保数据能够按照正确的顺序、无损地传输到接收方。
- HTTP则定义了客户端和服务器之间的通信规则,特别是如何发送请求和接收响应。HTTP使用请求-响应模型,客户端发送HTTP请求到服务器,服务器响应请求并返回相应的数据。
- 连接方式不同:
- TCP是面向连接的协议,在通信双方之间建立连接,并维护连接的状态,直到通信结束或连接被显式关闭。TCP连接的建立采用三次握手机制,释放连接采用四次挥手机制。
- HTTP在HTTP 1.0中,客户端的每次请求都要求建立一次单独的连接,处理完请求后自动释放连接。在HTTP 1.1中,虽然可以在一次连接中处理多个请求,但每个请求-响应对仍然是独立的,HTTP本身并不维护连接的状态。
- 数据传输方式不同:
- TCP提供字节流的传输,即TCP将数据视为无结构的字节流,不关心数据的内容。
- HTTP则以文本或二进制格式传输数据,HTTP请求和响应都包含特定的报文头和数据体,这些报文头和数据体按照一定的格式进行编码和解码。
联系
依赖关系:HTTP协议是建立在TCP协议之上的。HTTP使用TCP作为传输层协议,以提供可靠的数据传输。这意味着HTTP协议中的所有数据都是通过TCP连接来传输的。
协同工作:当HTTP客户端(如Web浏览器)想要从HTTP服务器获取资源时,它会首先与服务器建立TCP连接,然后通过这个连接发送HTTP请求。服务器在收到请求后,会处理请求并返回相应的HTTP响应,这个响应也是通过之前建立的TCP连接发送给客户端的。
HTTP基于TCP做了什么,变成了一种新的协议
1. 定义通信格式
HTTP协议在TCP提供的可靠传输服务基础上,定义了客户端和服务器之间的通信格式。这包括:
- 请求格式:HTTP请求由请求行(如GET / HTTP/1.1)、请求头部(包含多个字段,如User-Agent、Accept等)和请求体(可选,用于POST和PUT请求)组成。
- 响应格式:HTTP响应由状态行(如HTTP/1.1 200 OK)、响应头部(包含多个字段,如Content-Type、Content-Length等)和响应体(包含请求的资源内容)组成。
2. 引入应用层特性
HTTP协议在TCP之上引入了一系列应用层特性,以支持Web应用的运行,包括:
- 超文本传输:HTTP最初的目的就是传输超文本(Hypertext),即包含链接的文本。这使得Web页面能够相互链接,形成复杂的网络结构。
- 请求-响应模型:HTTP使用请求-响应模型进行通信。客户端发送HTTP请求到服务器,服务器处理请求并返回响应。这种模型简化了Web应用的开发和使用。
- 资源标识:HTTP通过URL(统一资源定位符)来标识和定位互联网上的资源。这使得客户端能够精确地请求所需的资源。
- 缓存机制:HTTP协议支持缓存机制,允许客户端和服务器缓存资源以减少网络传输的负载和提高访问速度。
描述一下HTTP请求报文长什么样,请求行、header、body,以及body之间有没有什么分隔符
1. 请求行(Request Line)
请求行位于请求报文的第一行,由三个字段组成:请求方法(如GET、POST)、请求的URL(统一资源定位符)和HTTP协议版本(如HTTP/1.1),这三个字段之间用空格分隔。例如:
GET /index.html HTTP/1.1这里,
GET是请求方法,/index.html是请求的URL,HTTP/1.1是HTTP协议版本。2. 请求头部(Headers)
请求头部紧随请求行之后,由一系列的字段组成,每个字段由字段名和字段值构成,字段名和字段值之间用冒号(:)分隔,字段之间通过回车符(CR)和换行符(LF)分隔。请求头部包含了客户端发送给服务器的附加信息,如客户端类型(User-Agent)、可接受的响应内容类型(Accept)、请求的主机名(Host)等。例如:
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8Accept-Language: en-US,en;q=0.5Host: www.example.comConnection: keep-alive3. 空行
在请求头部之后,有一个空行(即只包含回车符和换行符的行),用于分隔请求头部和请求体。这个空行是必需的,它告诉服务器请求头部已经结束,接下来的部分是请求体(如果有的话)。
4. 请求体(Body)
请求体位于空行之后,包含了客户端发送给服务器的实际数据。不是所有的HTTP请求都包含请求体,例如GET请求通常不包含请求体,因为GET请求的参数直接附加在URL后面。而POST、PUT等请求方法则经常包含请求体,用于提交表单数据、文件上传等。请求体的格式和内容类型由请求头部中的
Content-Type字段指定。
Header和Payload怎么隔开,如果不隔开,并不知道哪个是header,哪个是载荷
一个空行
HTTP协议报文的结尾有没有什么特殊的符号之类的
HTTP报文的结尾并没有一个显式的分隔符来标记报文的结束。相反,它依赖于内容长度、HTTP/2及更高版本的流和帧机制来隐式地表示报文的结束。
在HTTP/2及更高版本中,引入了流(Stream)和帧(Frame)的概念,以及流控制、多路复用等机制。这些机制允许在单个TCP连接上并发地传输多个HTTP消息,并且每个消息都有明确的边界。然而,这些边界是在HTTP/2的帧级别上定义的,而不是在HTTP报文的级别上。
TCP建立握手为什么需要三次,而不是两次或者四次
如果两次,可能出现历史报文连接问题,有可能出现第二次握手丢失服务端等待。
为什么不是四次:三次握手足够判断双方接送发送能力以及确认序列号,建立全双工连接。
TCP是全双工的协议吗,怎么理解全双工
全双工(Full Duplex)通信指的是在发送数据的同时也能够接收数据,两者的操作可以同时进行,即数据的传输可以在两个方向上同时进行,不需要进行方向的切换。这种通信方式要求通信双方都有发送和接收的能力,并且通信线路也支持双向传输。
提到全双工,那TCP三次握手来建立两个连接还是一个连接呢
单个连接,这个连接是全双工的,就是通信双方可以同时在这个连接上接收发送。
为什么Mysql推荐用自增ID而不是随机的UUID,请你从数据结构或者写入这块聊聊。
- UUID是一个128位的标识符,通常表示为36个字符(包括4个连字符)。相比之下,自增ID通常是整数类型,如INT(4字节)或BIGINT(8字节)。因此,UUID在存储上占用更多的空间。
- 由于自增ID的顺序性,插入操作可以快速地定位到B+树的末尾,并添加新记录。这种顺序插入的方式通常比随机插入要快。
- 相反,UUID的随机性导致插入操作需要更多的时间来找到正确的位置,并可能触发页分裂。这增加了插入操作的延迟和开销。
假设有一个应用用了UUID做了主键,在构建Innodb索引过程,就是从数据结构方面,b+树会怎么去调整
B+树是一种自平衡的树数据结构,它保持数据排序
UUID是一种128位的唯一标识符,通常表示为32个十六进制数字
由于UUID的随机性,新插入的UUID值几乎总是与现有值完全不同,这会导致B+树索引在插入新记录时频繁地进行页分裂。
当向B+树中插入一个新键值对,而该键值对无法放入当前叶子节点(页)时,会发生页分裂:
- 选择分裂点:通常选择页的中间位置作为分裂点,将页中的键值对分为两部分。
- 创建新页:分配一个新的页来存储分裂后的一部分键值对。
- 更新父节点:在父节点中插入一个新的目录项,该目录项包含分裂点的键值和新页的指针。
- 递归分裂:如果父节点也满了,则继续向上分裂,直到根节点。如果根节点分裂,则树的高度会增加。
聊一下四种隔离级别
读未提交,不加任何锁,可能读到其他事务未提交的数据,即脏读。
读已提交和可重复读。通过MVCC实现,不同的是读已提交每次使用快照读都产生新的readview,这可能导致一个事务内多次快照读的结果不一致,即不可重复读。可重复读则是一个事务只产生一个readview,事务内多次使用快照读结果一致。但可能出现幻读。
串行化,通过加锁串行,该级别下,会自动将所有普通select转化为select … lock in share mode执行,即针对同一数据的所有读写都变成互斥的,解决幻读,但效率低。
读已提交会不会存在幻读问题
会存在幻读问题
什么是幻读
一个事务多次范围查询结果不一致
事务A先开启,读了一次范围查询,读了100条,事务B删除其中一条,事务A再去读,是读到99条算幻读,还是读到100条算幻读。
读到99条算幻读
mysql的索引长度有没有一些限制
innodb没开innodb_large_prefix时,如果字符最大字节为1,那么单列最大767字节,总列最大为其4倍。
开了innodb_large_prefix,则单列总列大小都是原来4倍。
Mysam则是单列总列都不超过1000字节,
redis的key的过期策略
1、定时过期:给每个key设置定时器,过期直接删除,对内存友好。
2、定期删除:隔一段时间随机扫描key,把过期的删除,如果过期比例高就继续。
3、惰性删除:使用key前检查是否过期,过期删除。对CPU友好。
Redis采用定期+惰性策略。
redis的zset的底层实现是怎样实现的,时间复杂度是多少

 https://blog.csdn.net/weixin_61067952/article/details/141158722?spm=1001.2014.3001.5502
https://blog.csdn.net/weixin_61067952/article/details/141158722?spm=1001.2014.3001.5502
解题思路:
维护一个左指针和右指针,左指针表示一个区间的左端点,初始为排序后第一个左端点,右指针表示上一个区间的右端点,每次比较当前区间和右指针,包含则更新右指针,否则将左右指针放入答案,同时更新左右指针。