基本情况
《A Unified Multi-scale Deep Convolutional Neural Network for Fast Object Detection》是发表于ECCV16的一篇很出色的文章,来自加州圣地亚哥的Zhaowei Cai。其基本思路是提出了一种多尺度卷积神经网络,由于不同层的feature map的优势不一样,如较低层的feature map由于感知野较小,因此对与小物体的检测相对较好;较高层由于考虑到了很大感知野的信息,因此可以忽略掉大量噪声,对大物体检测较为精确。作者便是考虑到了这一特性首次将在feature map上针对不同层设计不同尺度的检测器。同时使用了特征图的解卷积层来代替input图像的上采样,提升了速度和精度。
总体结构
该网络总体结构的设计参考Fast RCNN, 由两个子网络构成,且每个子网络都是端对端的,同时也是权值共享的。一个是object proposal network, 另外一个是accurate detection network。
下面将对两部分的结构进行具体分析:
Object Proposal Network
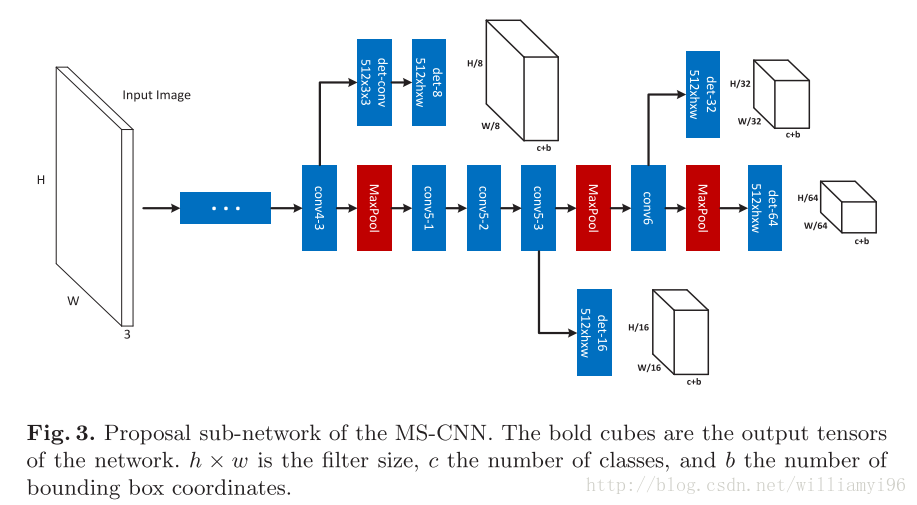
注意到Object Proposal Network是基于VGG来进行设计的,其像一棵树。主干就是原始的VGG,分支上是另外为了实现多尺度目标检测而设计的网络,构成相同。
然而虽然其是基于VGG的5*5 卷积和7×7卷积,考虑3 × 3卷积和1 × 1 卷积的使用效果是否会更好。
关于其具体参数,如det-8的含义将在后文中继续进行说明。
Accurate Detection Network
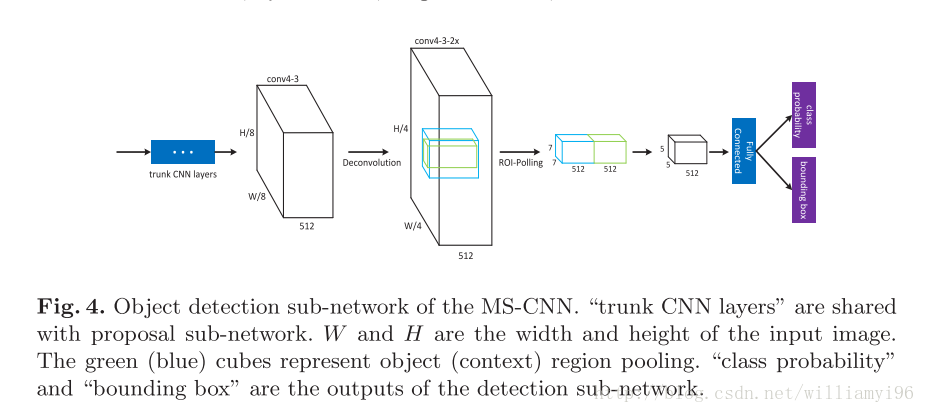
关于Accurate Detection Network的结构将在接下来进行具体说明。
Object Proposal Network
Multi-scale Detection
在进行Object Proposal 网络设计的时候,我们会遇到一个较为突出的问题,也就是物体的size是各种各样的,我们如何采取一定的标准去适应这种多变的size。总体而言,有两种主流的方式:一种是分类器不变,但是将图片的size规范化到一个特定的大小(如 RCNN 中的 228 × 228);另一种是针对同一张图片使用不同分类器。
关于多尺度size问题的解决,作者深入地围绕下面这幅图展开了分析:
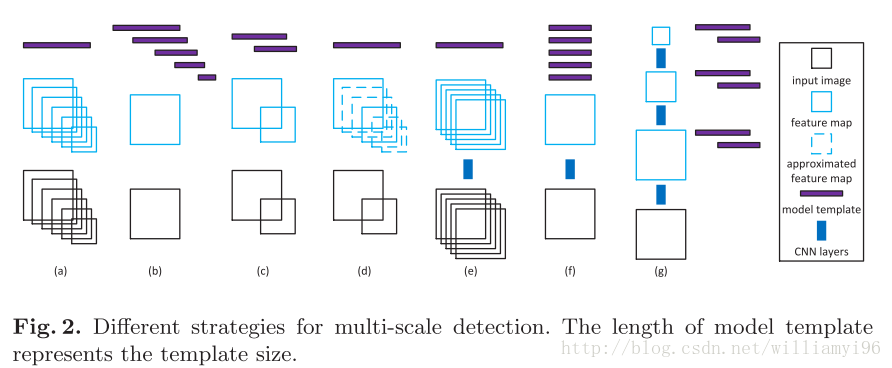
- (a) 将各种尺度的图片规范化到同一个大小,然后由单分类器进行分类。优势是一般精度较高,但是太过于耗时;
- (b) 对一张照片,采用不同的分类器,然后生成长度不等的model template。优点是避免了图片的重复计算同时算法效率较高,但是往往不能够较好地生成proposals;
- (c) rescale the input a few times and learn a small number of model templates
- (d) this consists of rescaling the input a small number of times and interpolating the missing feature maps
- (e) the R-CNN simply warps object proposal patches to the natural scale of the CNN
- (f) similar to b, but multiple sets of templates of the same size are applied to all feature maps.
- (g) 作者推荐的方式,是e和f两者的结合产物,也就是做了一个trade-off。
配合作者上述multi-scale的策略,选用了g的总体结构。
Architecture
该部分的整体结构已经在上文中进行了说明,为了设计多尺度的检测,在网络的不同深度处进行了相同的检测网络的设计。
此外,值得注意的是,出于防止较低深度的conv4-3的梯度直接汇入主干,使用到了det-conv进行缓冲。
在训练阶段,由于理论证明联合损失函数的效果较好,因此这篇文章中也使用了联合损失函数。具体的定义如下所示:
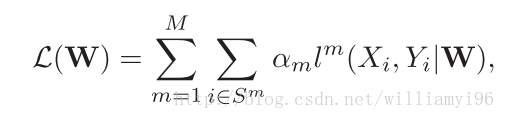
其中M是检测分支的数量,在本论文中为4;S^m 是尺度m的实例,其具体值的是啥,将在后续源码中仔细分析, Xi是训练的图片的patch,Yi是对应的图片的类标签和对应的bounding box 坐标。但是其并不是仅仅针对一张图片啊??
关于损失函数的设计采用的是通用的模板,详情参加论文介绍。在此不进行赘述。
Sampling
在本篇论文中采用到的sampling的方法,作者从三个角度分别进行了讨论。
分别为如下三个部分:
- random sampling
- bootstrapping
- mixture
这三个部分的设计概念的解释以及具体实现的方式已经在文章中进行了具体的说明。将在后续的进一步了解中进行深化。
Implementation Details
Data Augmentation
在Fast RCNN以及SPP-Net中,提到由于深度神经网络善于学习尺度不变性,因此没有必要设计multi-scale 的方法。作者指出,这一观点针对于KITTI数据集和Caltech数据集是有问题的,就拿KITTI来说,小物体和大物体的尺寸差距较大,同时大物体的数量在所有物体中所占的比例相对还较小。因此将原始的图片随机地resize是很有必要的。(这里为什么涉及到将原始图片进行大小缩放的问题?作者的逻辑在何?)
Fine Tuning
处于训练Fast RCNN和RPN网络需要大量内存的考虑,我们仅仅选择的是围绕物体的周围小的patch进行训练(448 × 448)。 这种方式极大地减轻了内存需求。
另外,训练的过程采用了流行的VGG-Net。但是由于bootstrapping和multi-task loss在早起的迭代中会让训练变得不稳定,因此作者提出了一种two-stage的方法。
The first stage uses random sampling and a small trade-off coefficient λ (e.g. 0.05). 10,000 iterations are run with a learning rate of 0.00005. The resulting model is used to initialize the second stage, where random sampling is switched to bootstrapping and λ = 1. We set αi = 0.9 for “det-8” and αi = 1 for the other layers. Another 25,000 iterations are run with an initial learning rate of 0.00005, which decays 10 times after every 10,000 iterations. This two-stage learning procedure enables stable multi-task training.
Accurate Detection Network
CNN Feature Map Approximation
关于CNN Feature Map Approximation部分的具体设计与实现有许多存在着不是太理解的地方,将在后续进行分析。
Context Embedding
关于Context Embedding也有许多不是十分理解的地方,将在后文中进行仔细分析。
Implementation Details
Learning is initialized with the model generated by the first learning stage of the proposal network, described in Section 3.4. The learning rate is set to 0.0005, and reduced by a factor of 10 times after every 10,000 iterations. Learning stops after 25,000 iterations. The joint optimization of (6) is solved by back-propagation throughout the unified network. Bootstrapping is used and λ = 1. Following [4], the parameters of layers“conv1-1” to “conv2-2” are fixed during learning, for faster training.
Experimental Evaluation
原始的MSCNN的代码是通过C++基于caffe实现的,其配置总体而言似乎与其他的实验配置并没有太大区别。关于具体的参数将在之后基于源码进行分析。
Proposal Evaluation
由于MSCNN是基于两个网络结合的产物,因此将会对两个部分分别进行评估。
独立的检测层功能
实验发现,使用Multi-scale的方法确实对目标高度差距较大的数据集上的效果较好,关于其比较的具体信息参见下图:
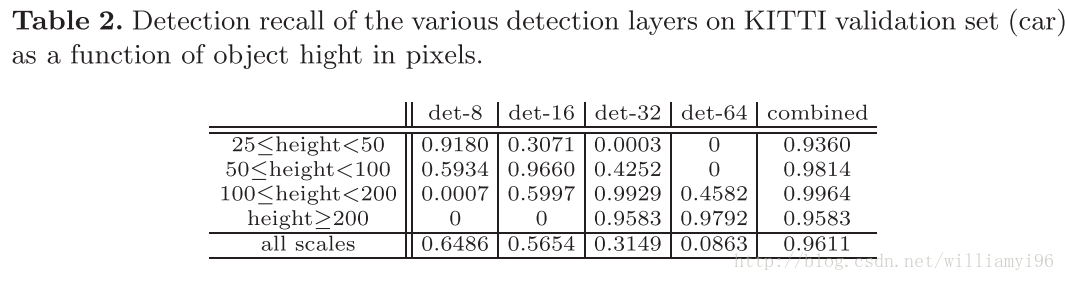
输入规模的影响
实验证明,proposal network在车辆和行人检测中,是输入图片的尺寸是十分鲁邦的,而针对cyclist,其性能在高度为384到576之间性能会逐步提升,但是其他的高度范围没有明显的变化。
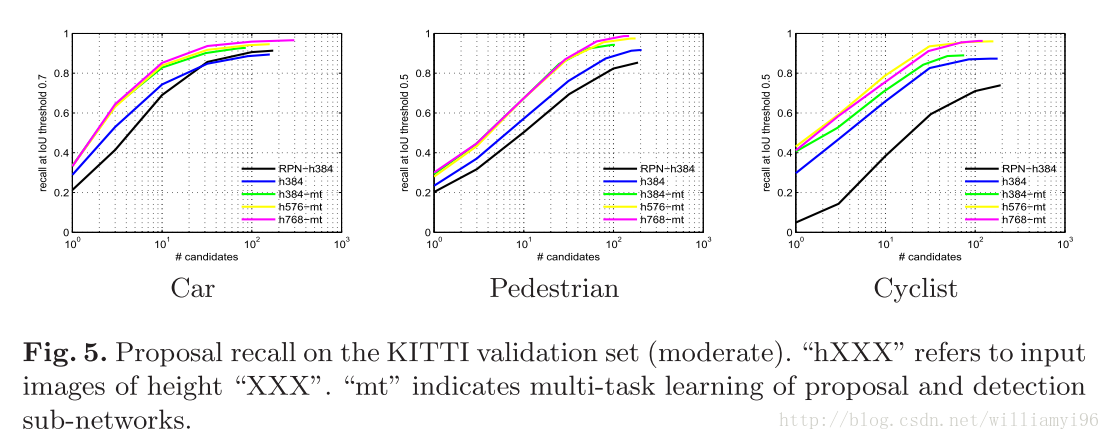
检测子网络提升了proposal子网络的性能
尽管有一些研究表明,共享参数并不会提升网络的性能,同时multi-task learning的策略既能够有利于bounding box regression, 又能够有利于classification。
仍然是通过上述图五可以发现,MSCNN联合训练网络可以提升检测的性能,特别是针对cyclist更是如此。
与当前state-of-art的方法比较
与当前前沿方法的对比:
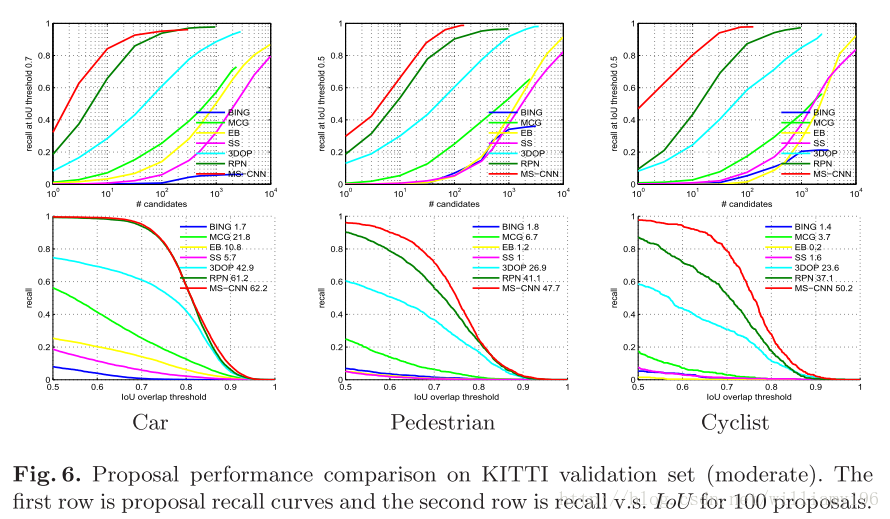
值得注意到是,使用到的RPN网络是经过了两倍Input upsampled 的结果。
Object Detection Evaluation
作者在实际的检测比较中,仅仅分析了车辆检测和行人检测的效果,对于cyclist,作者通过分析认为,一方面cyclist检测的效果与数据集的关系联系太大,另外一方面在实际数据集上cyclist的出现频率太低,不利于训练。
input upsampling的影响
下述的表格表明,input upsampling是一个检测效果的重要影响因素。通过实验表明,upsampling的倍数在1.5到2倍之间时,性能会大大提升;然而再增加其倍数,发现效果并没有得到较大的提升,同时导致了检测效率的下降和更多的内存需求。
关于其具体的比较可以参见下面这张图:
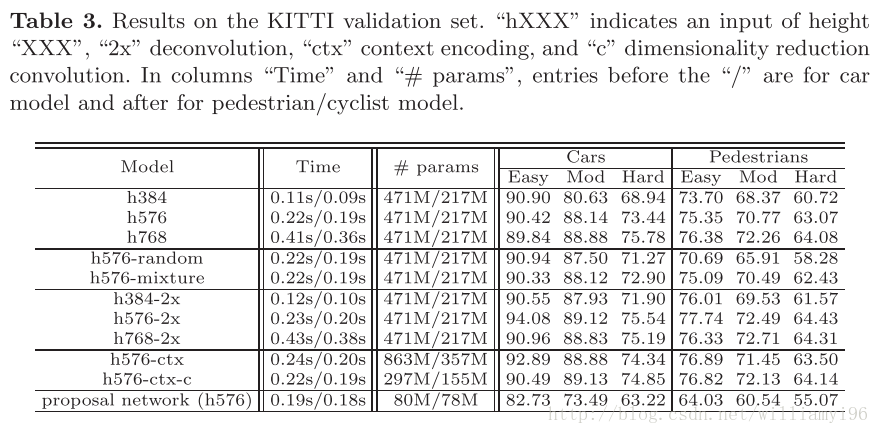
sampling 策略
作者比较了random sampling, bootstrapping 和 mixture三种采样方法,对于车辆检测来说,三者效果相当;但是针对行人检测来说,随机采样的效果较差,其他两者相当。
具体的信息可以看上述的图片说明。
CNN feature approximation
作者测试了三种解卷积层的训练方法,分别为
- 双线性差值
- 双线性差值初始化+BP训练
- 高斯噪声初始化+BP训练
图表三结果表明,使用双线性差值的方法得到的效果最好。
上下文嵌入
Table 3 shows that there is a gain in encoding context. However, the number of model parameters almost doubles. The dimensionality reduction convolution layer significantly reduces this problem, without impairment of accuracy or speed.
上下文嵌入的好坏也是一个trade-off的过程,虽然其可以提升性能,但是却几乎是参数数量翻倍了。不过有一点不是太清楚的是,’dimensionality reduction convolution layer’ 指的是不是对于卷积层层数较少时,效果显著提升。
Object detection by the proposal network
The proposal network can work as a detector, by switching the class-agnostic classification to class-specific. Ta- ble 3 shows that, although not as strong as the unified network, it achieves fairly good results, which are better than those of some detectors on the KITTI leaderboard1.
总结
We have proposed a unified deep convolutional neural network, denoted the MS- CNN, for fast multi-scale object detection. The detection is preformed at various intermediate network layers, whose receptive fields match various object scales. This enables the detection of all object scales by feedforwarding a single input image through the network, which results in a very fast detector. CNN feature approximation was also explored, as an alternative to input upsampling. It was shown to result in significant savings in memory and computation. Overall, the MS-CNN detector achieves high detection rates at speeds of up to 15 fps.
总体而言,这篇文章还是十分有参考价值的。将在后续进行其源码的分析。