说明
欠拟合和过拟合是回归和分类问题中可能会遇到的现象。这两概念的解释以及解决的办法我在之前的博文[1]中有过介绍,不过在这篇文章中介绍得比较粗糙,本文想要更系统地对这两个概念进行阐述和实践。也算是对博文[1]的补充和拓展。
Blog
2024.10.29 博文第一次写作
目录
一、过拟合与正则化概述
1.1 欠拟合与过拟合概述
欠拟合和过拟合这两个概念其实很容易理解: 欠拟合是指训练得到的模型对训练数据集和测试数据集都无法有效拟合。其表现为损失函数的值很大、对数据集样本(包括训练集和测试集)的预测或分类的准确性差。 过拟合则是指训练得到的模型对训练集的拟合效果很好,但是对测试集的拟合效果差。其表现为损失函数的值可以到很小,对训练集的预测或分类效果很好,但是对测试集样本的预测或分类的准确性差。
发生欠拟合主要的原因是:1、模型过于简单;比如在博文[2]的3.3节中,我们使用一元线性模型去拟合基于一元四次函数生成的数据集时,不管对于训练集还是测试集,得到的均方误差和都很大。 2、训练数据集太少; 3、特征不足或特征选择不当。(后两者也是不难理解的:试想只是给出两三个样本,但是要求拟合一个一元四次函数,这必然导致拟合效果很差;而特征不足的表现和我们用一元线性模型去拟合一元四次函数生成的数据集本质是一样的。)
欠拟合是很容易被发现的:如果在训练时,发现损失函数的值收敛到一个很大的值,我们就应该意识到是欠拟合了。如果训练集的样本数比较多,那么就应该考虑增加模型的复杂度,重新进行训练。
发生过拟合主要的原因是:1、模型太过复杂;2、训练数据集太少;3、特征数过多。其导致的现象是,训练得到的模型几乎完美拟合训练集,损失函数的值为接近0,对训练集的预测/分类的准确率接近100%,但是放到测试集里效果大打折扣。
过拟合我们需要借助测试集进行对比(效果有很大的落差)才能发现。过拟合的解决办法则是:如果训练集的样本数足够多,那么就应该降低模型的复杂度。
1.2 正则化概述
不管对欠拟合还是过拟合的解决,都存在相似的问题:前文说到,欠拟合下我们需要增加模型的复杂度,可是,增加到什么程度合适?如果模型复杂度增加太少还是会欠拟合,而如果模型变得过于复杂又会导致过拟合。(比如要拟合的对象是一元四次函数,我们用一元一次线性模型时发现欠拟合,此时改成一元二次或者三次还是会欠拟合,改成一元五次的线性模型则会过拟合)。过拟合下通过降低模型复杂度也会有类似的问题。 有没有更一般的,不需要进行多次试错的方法解决这个问题? 有的:正则化!
正则化解决过拟合的思路是:在不丢掉特征、不减少模型复杂度的情况下,通过给模型里各特征的权值增加惩罚项(也称为正则化项)来约束权值的大小,从而达到限制模型复杂度的效果,以增加模型的泛化能力。
回到前面的两个问题,欠拟合下其实我们可以一开始就设计比较复杂的模型把欠拟合变成过拟合,从而杜绝欠拟合的发生… 而可能导致的过拟合我们则可以通过正则化来解决。所以我们一般更多的是讨论过拟合问题的解决。
1.3 各类回归和分类模型下的正则化方法
进一步地,这里给出线性回归、逻辑回归、Softmax回归模型下的正则化方法。如前所述,正则化不改变模型,只是在优化准则(损失函数)中增加正则化项:(关于前述三个模型的相关概念,读者可以参考我之前的博文[2]、[3]、[4])。
【线性回归】
线性回归的线性模型为:
(1-1)
式中x为样本的特征,n为样本的特征数量,θ为各特征的权值(也是我们想要训练求解的东西)。
线性回归的优化准则(损失函数)为:

我们一般将均方误差和设计为损失函数。式中,m为训练集样本的数量。后续优化时,我们的目标是使得该损失函数的值越小越好。
如前所述,正则化就是在原有损失函数的基础上增加了正则化项:
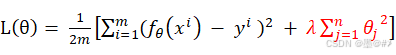
式中,红色部分是加入的正则化项(还要乘以外边的1/2/m),n为样本特征数(累加是从1开始,我们并没有对θ0施加惩罚)。其本质就是把各个权值拿出来然后取平方后相加,λ为常数,或称为惩罚系数,可以用来调节惩罚项的大小。
正则化的方法有很多种,比如L1正则化是计算权值的绝对值之和,不过一般我们用得更多的是上式中的L2正则化:模型权值平方和均值的一半。L1正则化倾向于产生稀疏权重矩阵,也即很多参数会变为零,因此可以用于特征选择(可以先使用L1正则化来筛选有用的特征,随后再使用L2正则化来优化模型?以后可以尝试一下,不过本文暂不讨论有关特征选取的问题)。L2正则化倾向于使参数值均匀变小,但不会使它们变为零。
需要注意的是,式(1-3)中,因为θ0没有与特征相乘,所以并没有把θ0引入。我们还是用梯度下降法来进行求解,式(1-3)下,我们对权值的更新公式为:(引入学习率α)
Repeat:
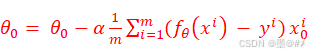
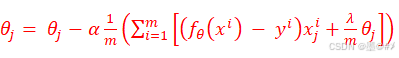
或:
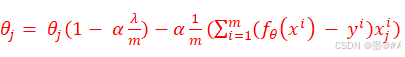
式(1-4)是专门针对θ0的更新,取1。式(1-6)是针对θ1到θn的更新,式中
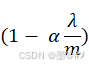
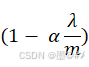
我们也可以用正规方程法求解,在没有加入正则化项前,正规方程法的求解公式为:
(1-7)
加入正则化项之后,求解公式为:
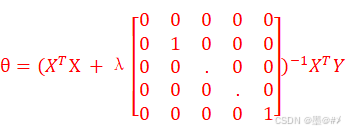
本文将只使用梯度下降法求解。正规方程法的编程很简单,读者可以自行编写,也可以参考我在博文[2]中所提供的代码。
【逻辑回归(二分类)】
逻辑回归的模型为:
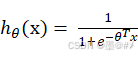
式中x为样本的特征,θ为各特征的权值(也是我们想要训练求解的东西)。
逻辑回归的优化准则(损失函数)为:

式中,m为训练集的样本数。如前所述,正则化就是在原有损失函数的基础上增加了正则化项:
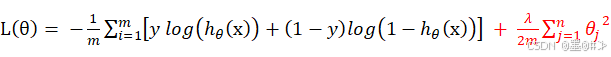
式中,红色部分是加入的正则化项。我们还是用梯度下降法来进行求解,式(1-11)下,我们对权值的更新公式为:(引入学习率α)
Repeat:
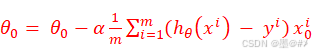
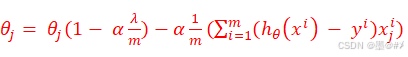
其实上面两式在形式上和式(1-4)、(1-6)一样。不过要注意模型函数的不同,从上面两式的f(x)变成了这里的h(x)。f和h的定义分别见式(1-1)和式(1-9)。在逻辑回归中,没有正规方程法可以直接求解。
【softmax回归(多分类)】
Softmax回归的模型是:
(1-14)
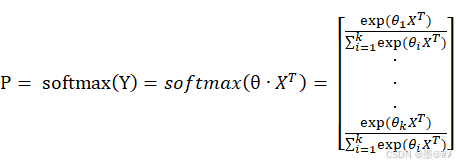
式中,argmax为取P中的最大值的索引,X为训练集样本构成的矩阵,θ是权值构成的矩阵,k是类别数量,更具体的读者可以参考博文[4]。
Softmax回归的优化准则(损失函数)为:
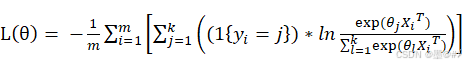
给其加入正则化项后得到:
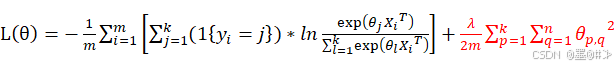
式中,m为样本数量,n为单样本的特征数。用梯度下降法来进行求解,式(1-17)下,我们对权值的更新公式为:
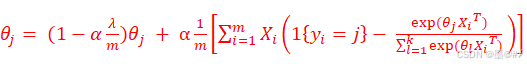
(注:因为我们没有对截距θp,1进行惩罚,所以在更新这里的权值时,和前面两种模型类似,θj的第一个数需要特殊处理,此时λ= 0)
1.4 本章小结
本章首先对欠拟合以及过拟合的相关概念做了介绍,随后针对过拟合问题,引入了正则化的概念,对正则化的相关理论做了介绍,并给出了线性回归、逻辑回归以及Softmax回归三种模型下的正则化方法和权值更新公式。后文将在本章的基础上,分别实践线性回归和逻辑回归下的正则化。
二、线性回归中的正则化实践
2.1 数据集简介
本章使用在博文[2]中用过的数据集[5],关于房屋价格的数据集。(读者可以从链接中下载,不过我也连同代码一并打包在了第七章的链接中)。 有关该数据集的介绍这里不做展开,读者可以移步博文[2]的4.1节查看。
原始数据中一共有414个样本,每个样本有6个特征:交易日期、房屋年龄、离最近交通枢纽的距离、周边商场的数量、房屋的地理维度、地理经度,其样本值为房屋价格。
本章的实践中,随机选择其中1/3的数据作为训练集,剩余2/3的数据作为测试集(训练集的数量小于测试集,是为了减少训练样本,使得过拟合的效果更显著);预设学习率在(0 0.3)区间内随机生成;预设正则化项的惩罚系数为5;此外,为提高模型的复杂度,我额外增加了两个特征:房屋年龄的平方、房屋经纬度的乘积,构建了一个8元线性模型;各特征权值的初始化是在(0 1)区间内随机生成的;迭代次数预设为1000次。
2.2 正则化前后的处理结果
在前文理论的基础上,本节给出有无正则化两种情况下的模型训练结果以及回归的结果。(更具体的流程和实现细节说明,读者可以参考博文[2])。这里直接给出结果:
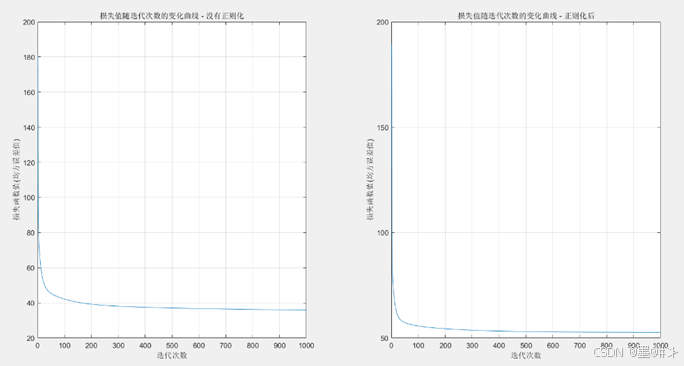
图2.1 有无正则化两种情况下的损失值随迭代次数的变化曲线
从图中可以看到,这两种情况下迭代的收敛速度相差不是很大,不过正则化后的最终的损失值要大于没有正则化的情况。两者参数的学习结果和最后的损失值分别为:

图2.2 有无正则化两种情况下得到的模型参数值&最终的损失值
第一章的理论分析告诉我们:过拟合时模型对训练集的拟合效果很好,加正则化项后应该会导致对训练集的拟合效果轻微恶化。所以上述实践的结果:正则化后其最后的损失值大于没有正则化下的损失值,这是符合理论预期的。
得到模型参数后,基于模型分别对训练集和测试集进行预测处理【这里有几张可视化的结果,类似博文[2]中的图片那样,但是意义不大,我就不贴出来了,读者可以用后文提供的代码自己跑跑看】,直接给出计算得到的预测均方误差和:

图2.3 模型对训练数据集和测试数据集预测(回归)的均方误差值
从上述结果来看, 1、没有正则化时,对训练数据集的预测(回归)效果优于对测试数据集的预测效果(均方误差更小),这是符合过拟合的现象的。 2、正则化后,模型对训练数据集的预测效果变差,这也是符合预期的(也和图2.1的结果相对应)。 3、正则化后对测试数据集的预测效果反而更差了!这是不符合理论的!本章对线性回归的正则化实践是有问题的…
讨论原因: 1、模型不够复杂,在本章设定的模型下(只是在线性模型的基础上增加了两个特征),并没有比较明显的过拟合现象:虽然前述两点都符合预期,但是整体上数值都比较大,而且我们还取了平方,所以其实对训练集和测试集预测的损失值、均方误差值都相差不大! 【而且这也可能是我特意选用了更少数量(1/3)的训练集造成的】 2、理论有误?代码编写有误? 应该没有问题的…
模型设计不够复杂、或者数据集本身并不适合用来做过拟合现象的实践等是导致本章实践效果欠佳的原因。 不过我不打算继续深究了,本文的目的是对过拟合的相关概念和理论进行说明,并进行实践,本章已经把实践的流程跑通。
三、逻辑回归(分类)中的正则化实践
3.1 数据集简介
数据在二维平面内生成(我在之前的博文[3]中也用的类似的生成方法):
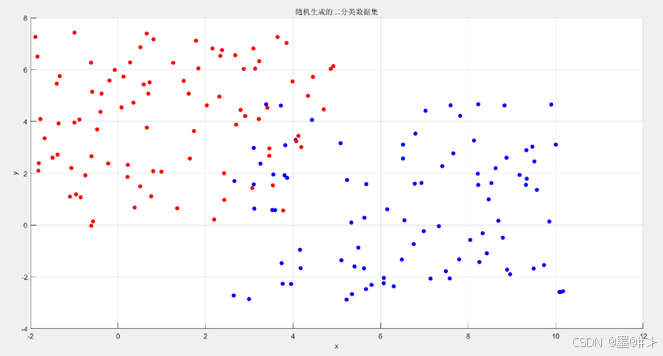
图3.1 所生成的数据集
本次实践中,一共生成了180组数据,所属两种类别(图中我用不同的颜色表示了),随后从这180组数据中随机选择2/3的数据作为训练集,剩余1/3的数据作为测试集。挑选的结果如下图所示:

图3.2 对数据集的挑选
图中,实心圆为训练集,空心圆为测试集。
3.2 正则化前后的处理结果
我们所生成的数据集只有两个特征:横坐标值和纵坐标值,为增加模型的复杂度(使其过拟合),我人为增加了两组特征: 横坐标值的平方、纵坐标值的平方,构造了一个四元线性模型(类似我在博文[2]中为拟合一元四次函数所做的操作)。随后,在前文的理论指导下,分别实践有无正则化两种情况的模型训练。
处理的整个流程我在之前的博文[3]中已经很详细说明了,这里直接给结果。预设学习率为1.2,有无正则化两种情况下权值的初始化是在(0 1)区间内随机生成,预设迭代次数为1000,预设惩罚系数为1。得到的结果如下:
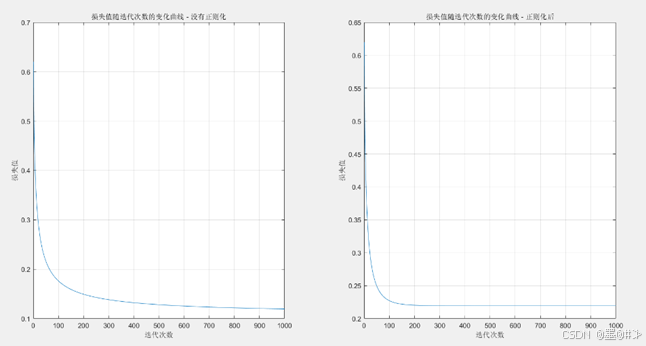
图3.3 有无正则化两种情况下的损失值随迭代次数的变化曲线
从图中可以看到:正则化下,损失值更快收敛,不过其收敛到的最小值要大于没有正则化的情况。其参数的学习结果和最后的损失值分别为:

图3.4 没有进行正则化时得到的权值结果以及最后的损失值

图3.5正则化后得到的权值结果以及最后的损失值
第一章的理论分析告诉我们:过拟合时模型对训练集的拟合效果很好,加正则化项后应该会导致对训练集的拟合效果轻微恶化。所以上述实践的结果:正则化后其最后的损失值大于没有正则化下的损失值,这是符合理论预期的。
得到模型参数后,基于模型分别对训练集和测试集进行分类处理【这里有几张可视化的结果,类似博文[3]中的图片那样,但是意义不大,我就不贴出来了,读者可以用后文提供的代码自己跑跑看】,直接给出计算得到的分类正确率:


图3.6 有无正则化下所得模型对训练集和测试集的分类正确率
从上图可以看到,正则化后对训练数据集的分类准确率几乎没有变化(有一点点降低),不过对测试数据集的分类准确率确实变高了:从86.7%到91.7%。【为杜绝结论的偶然性,按理说应该进行蒙特卡洛试验,多生成几次数据集并计算分类准确率的均值,不过本文只负责把道理讲通,更多的探讨读者可以基于本文提供的代码再自行研究。】
不过提高的效果不是很显著。考虑原因是:即便没有正则化,原有模型其实并没有严重的过拟合现象(模型对测试集的分类准确率并没有远远小于对训练集的分类准确率,或者说我们构建的模型还不够复杂..)。
四、Softmax回归(分类)中的正则化实践
不再给出,读者可以基于前面两种模型提供的代码,以及我在博文[4]中提供的关于Softmax多分类实践的代码自行编写代码实践。
五、总结
本文对回归(线性回归)和分类(逻辑回归、Softmax回归)中的过拟合问题进行了探讨和实践。首先对欠拟合、过拟合现象及其背后的原因做了解释;随后引入了正则化的概念,对正则化的原理进行了说明,并分别给出了:线性回归、逻辑回归以及Softmax回归三类模型下的正则化方法和权值更新公式;最后在前述理论的基础上,实践了线性回归和逻辑回归的正则化。
需要说明的是:本文给出的线性回归正则化的效果并不显著(或者说没啥效果,逻辑回归中其实效果也不是很显著),可能的原因是所用的数据集不够典型?或者是所选用的模型还不够复杂?(我在这方面还没有太多的实践经验),但这绝不表示正则化在线性回归中没有用!
正则化是一个很有用的工具,对其更深入的理解还是需要多实践才能感受到。本文的工作进一步丰富了专栏:机器学习_墨@#≯的博客-CSDN博客的工具箱!为后续更复杂的深度学习等内容的理解和实践打下了基础。
六、参考资料
[2] 回归问题探讨与实践-CSDN博客
[3] Logistic回归(分类)问题探讨与实践-CSDN博客
[5] Real Estate Valuation - UCI Machine Learning Repository