一、柯里化
概念:将原来接受两个参数的函数变成新的接受一个参数的函数过程,新的函数返回一个以原有第二个参数为参数的函数
例如:
例一
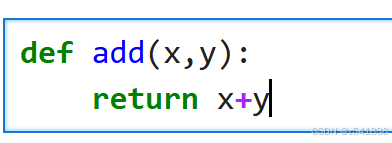
原函数是add(x,y),柯里化的目标是add(x)(y),如何实现呢?

相当于嵌套函数,有闭包,内层函数inner调用量外层函数变量x,形成了闭包。
再来看:
例二
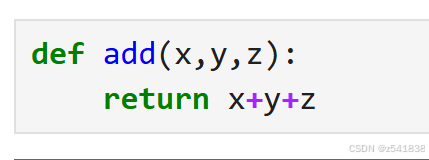
柯里化的目标是
1 def(x)(y,z)

2 add(x,y)(z)
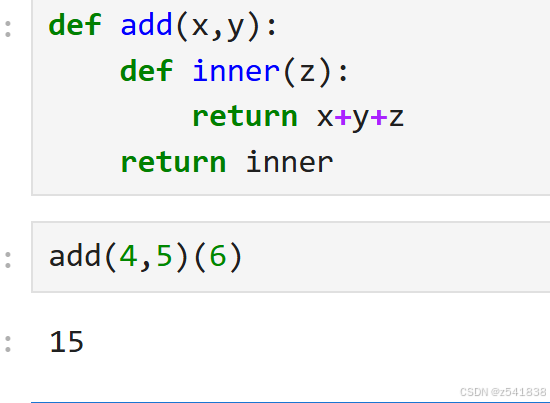
3 add(x)(y)(z)

了解了柯里化以后,下面就开始进入装饰器的讲解
二、无参装饰器
装饰器:用来装饰函数或类
由来需求为加法函数增加记录实参的功能
可以写成这样:

但是存在一个问题,add是业务功能代码,增加记录实参功能的代码属于非业务功能代码,不好,
也就是侵入式代码,剥离不易,假设换一种思维,A函数需要记录,B函数也需要记录,记录功能也不属于A和B的业务功能,而且它不是A和B的业务功能,而且它是A和B的公用功能,如果有c函数也需要此功能怎么办?
这里可以创建一个函数:logger来实现这个功能
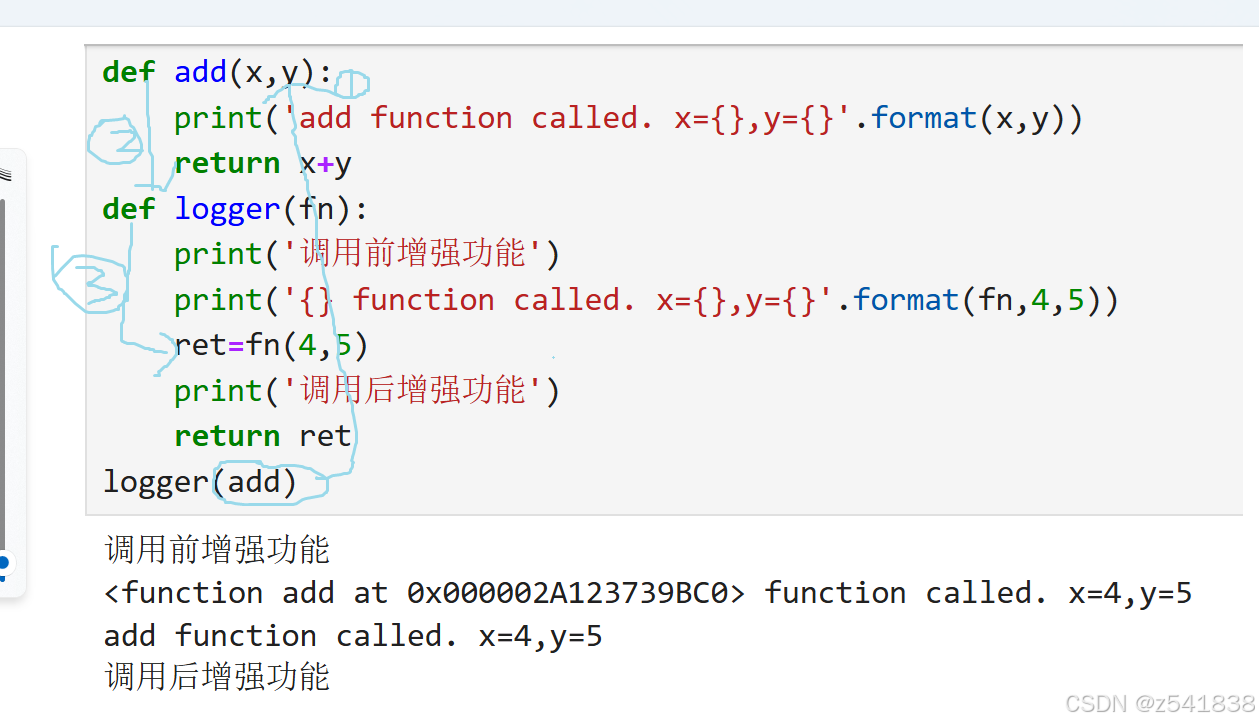
改变传参的方式,关键字传参和位置传参
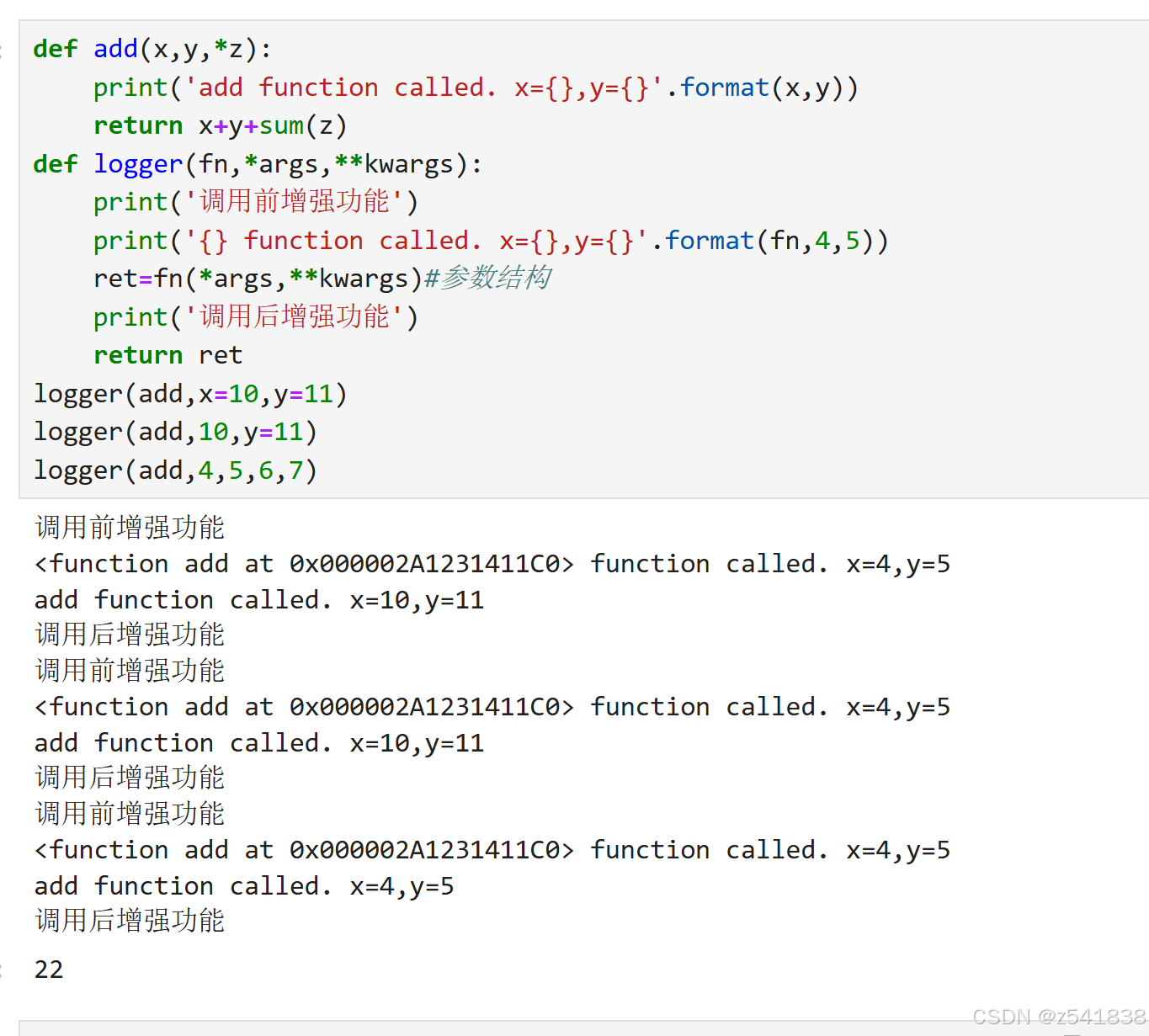
函数的每次调用都是相互独立的,互不干扰,别看add的内存地址一样,就认为他是覆盖调用。
下面调整一下代码:
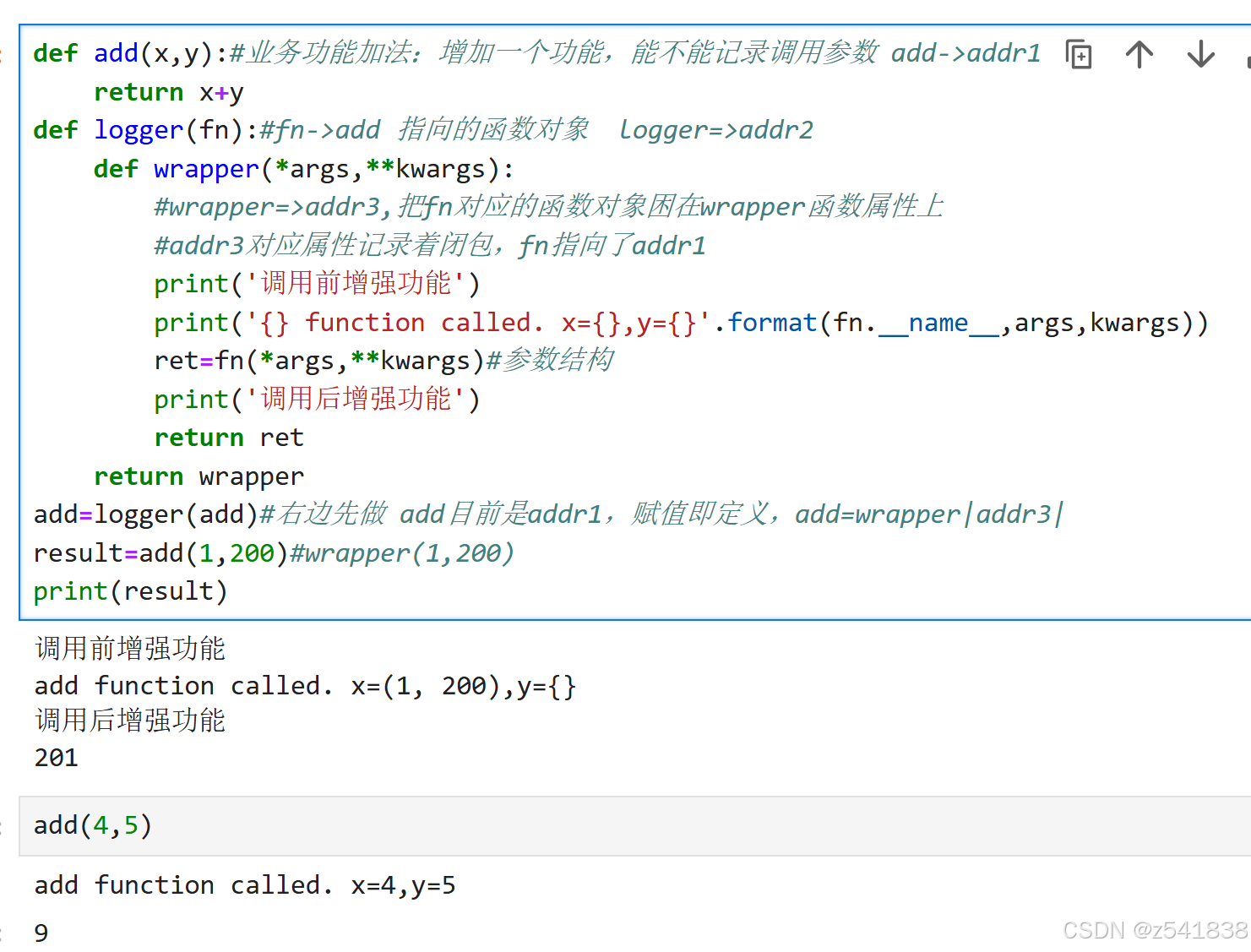
理解了这个以后装饰器对你来说就不是个问题
装饰器语法很简单:
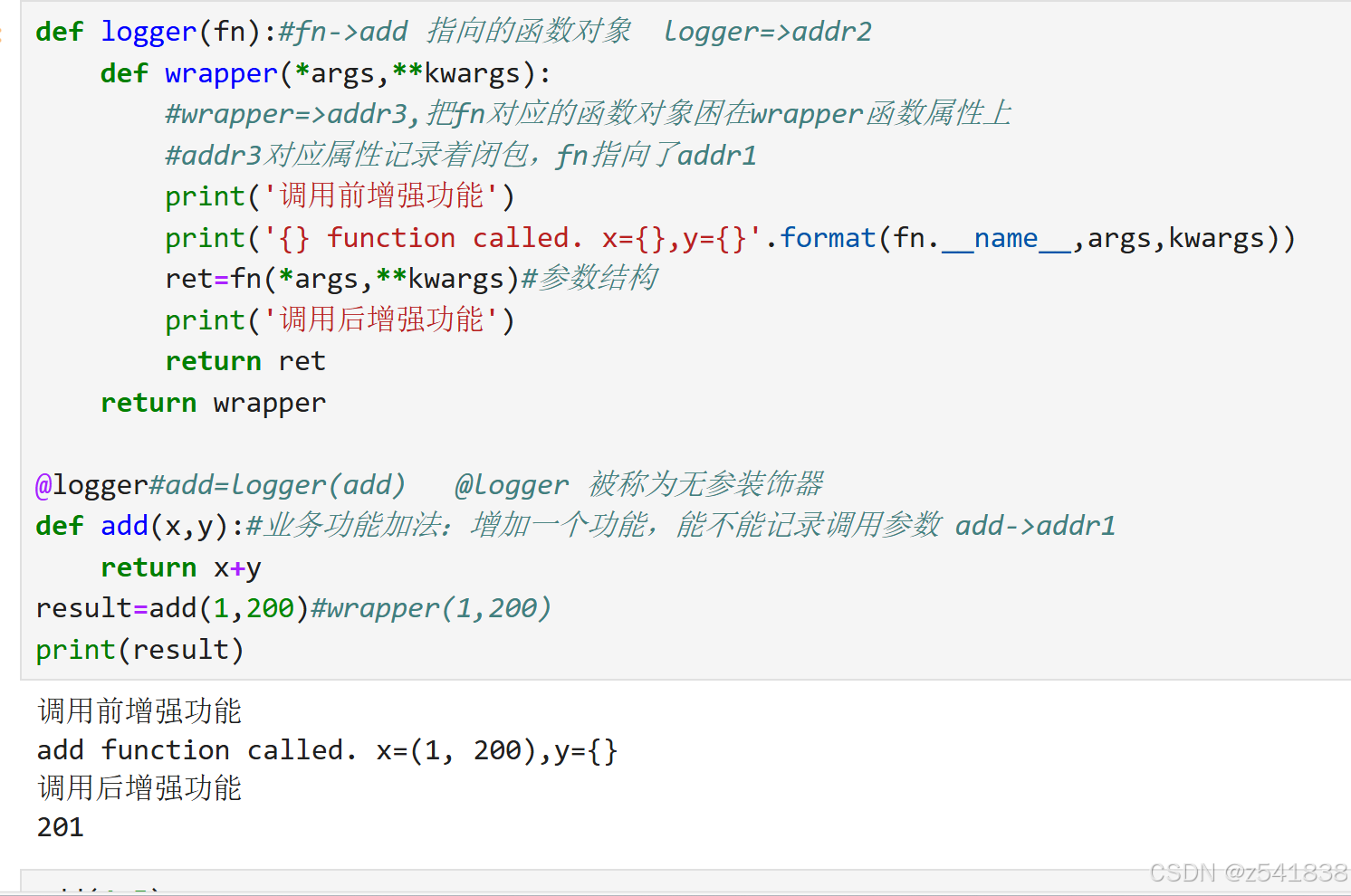
@标识符
标识符指向的是一个函数用一个函数来装饰他下面的函数logger函数称为装饰器add被称为被装饰器或被包装函数
logger习惯上称为wrapper
add习惯上称为wrapperd
本质上 无参装饰器logger实际上等效为一个参数的函数
无参装饰器logger
@logger会把他下面紧挨着的函数标识符提上来作为他的实参xyz=logger(xyz)
def xyz():
pass
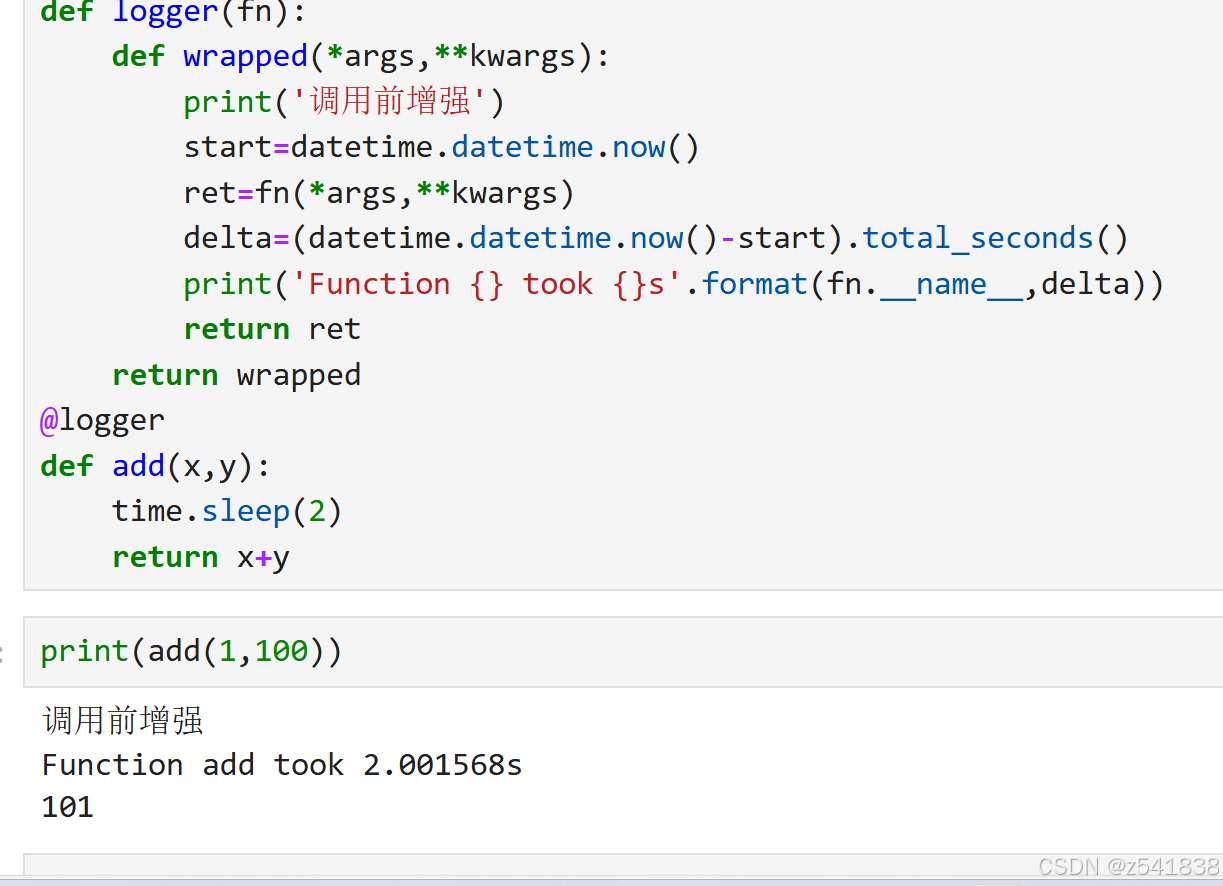
三、日志记录装饰器实现
四、文档字符串
在函数(类和模块)语句块的第一行,且习惯是多行的文本,所以多使用三引号
文档字符串也是一条合法语句,惯例是首字符大写,第一行写概述,空一行,第三行写详细概述
可以使用特殊属性__doc__访问这个文档
如:
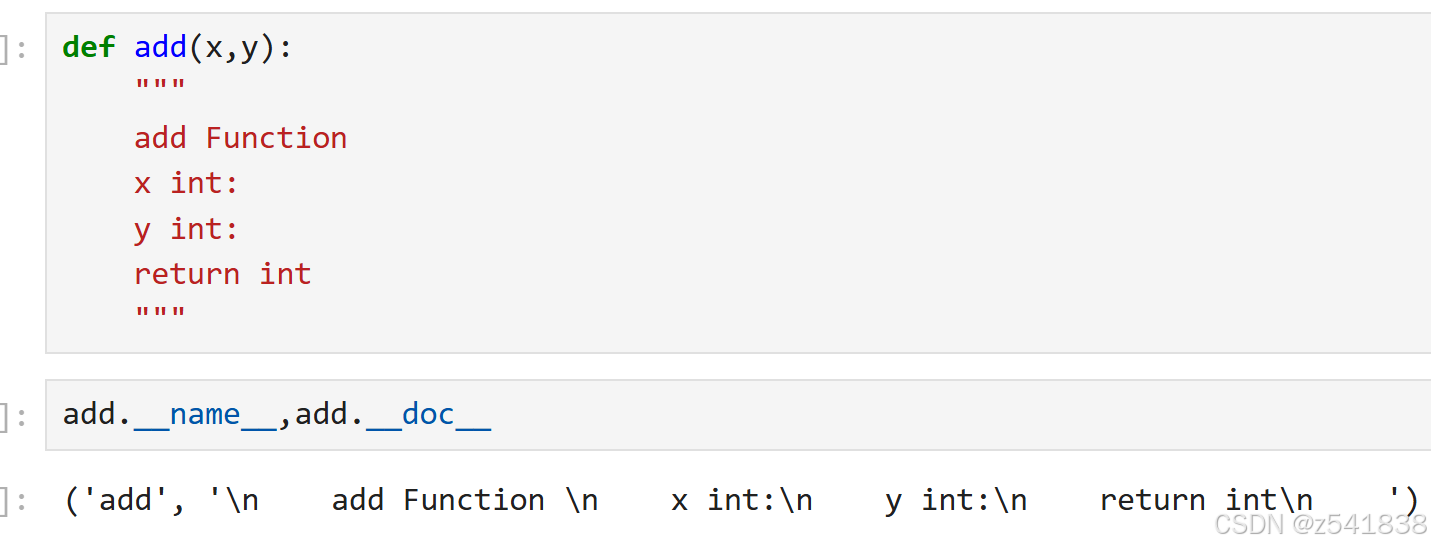
五、装饰器文档问题
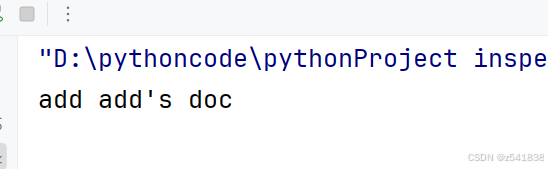
结果:
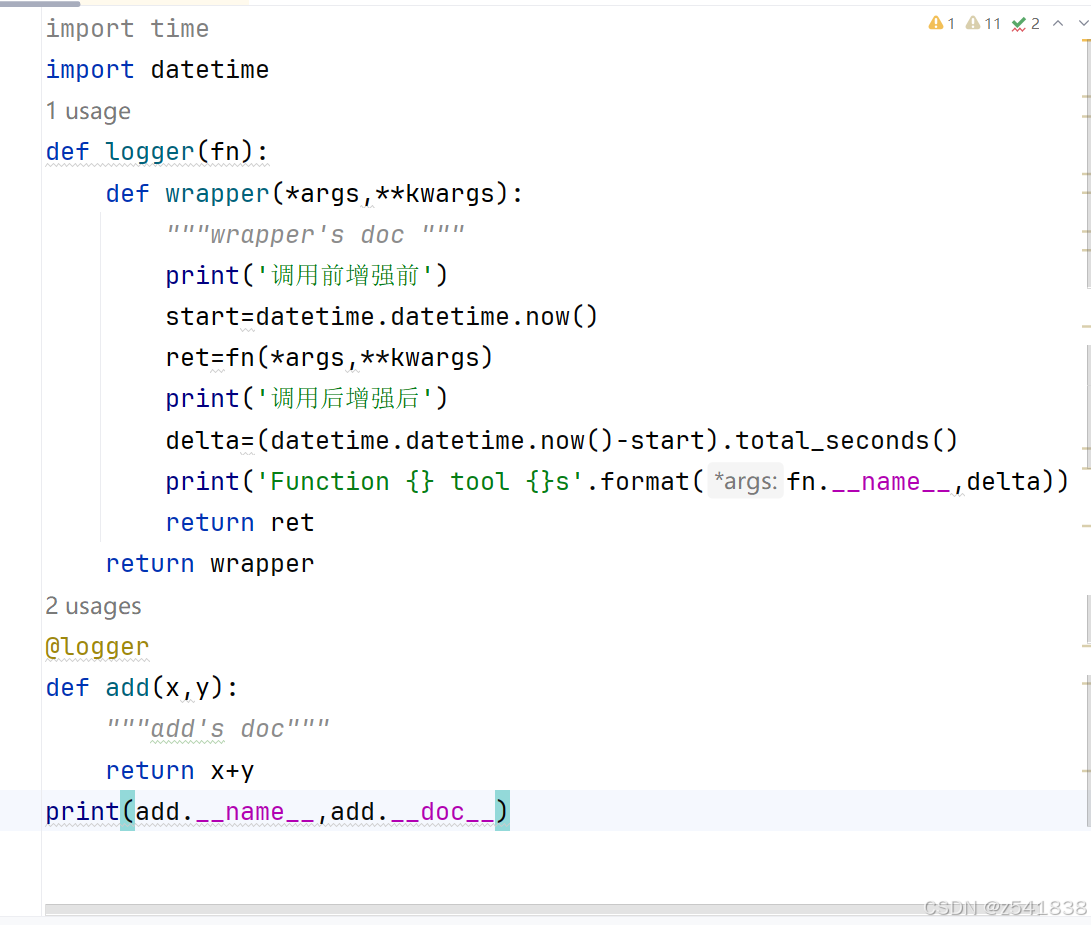
被装饰后,你会发现add的函数名和文档都变了?如何解决呢?
函数也是对象,特殊属性也是属性,也可以被覆盖,现在访问访问的add实际上是wrapper函数,所以使用原来定义的add函数和doc文档属性覆盖wrapper对应的属性就可以了
这叫用到带参装饰器了
六、带参装饰器
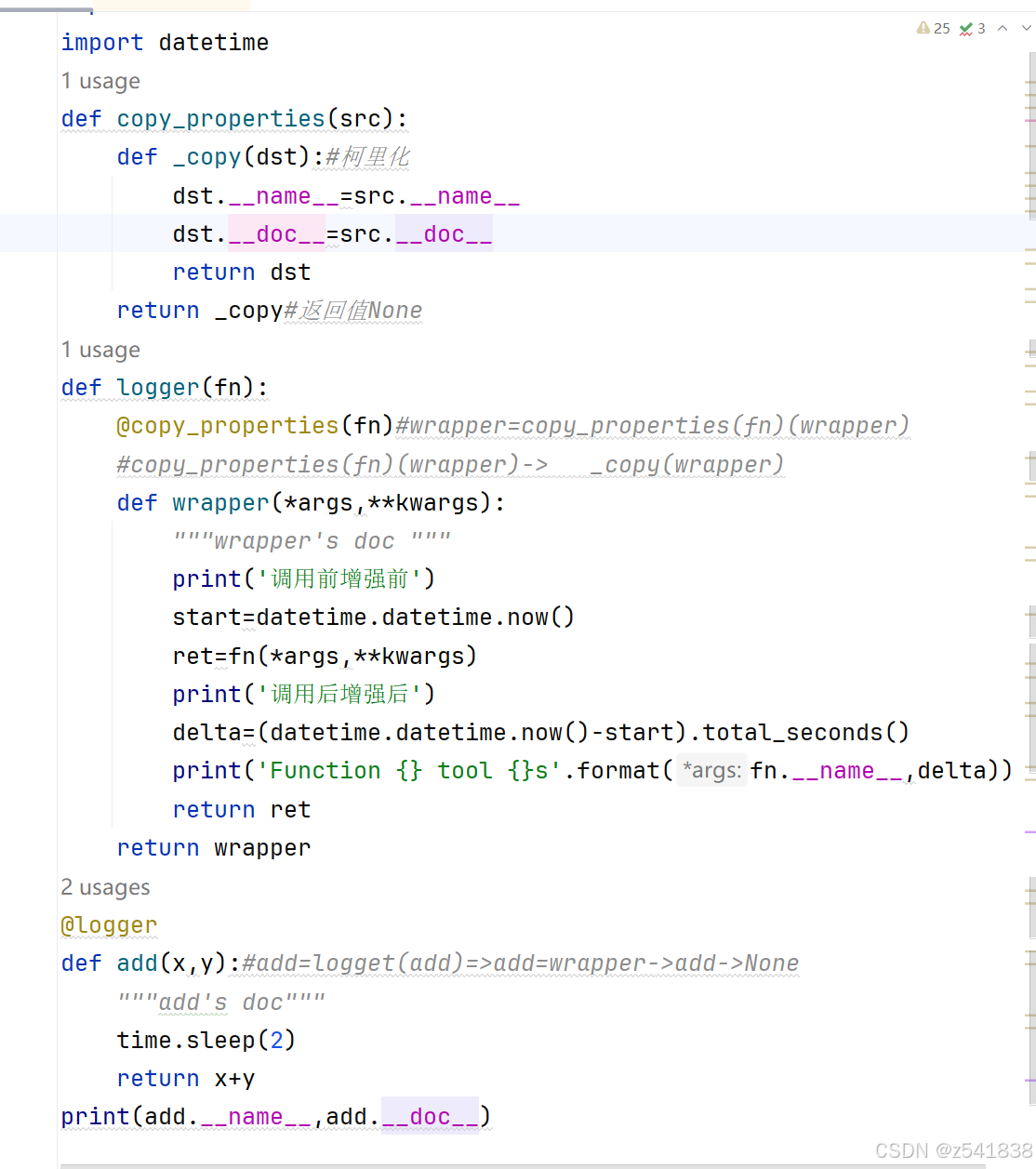
能否把copy_properties改成装饰器呢?这个装饰器就是带参装饰器
结果:
像copy_properties(fn)这种装饰器后面跟着一个函数的装饰器称为带参装饰器
先执行add=logger(add),在函数logger内部遇到copy_properties装饰器,
执行copy_properties(fn)(wrapper)这里的fn就是原函数add
也就是执行copy_properties(add)(wrapper)
下一步执行_copy函数
wrapper.__name__=add.__name__
wrapper.__doc__=add.__doc__
_copy返回None,因为修改add的名称和属性,所以_copy返回dst
替换完成以后,就继续执行logger内部函数wrapper
进行函数的打印和函数的调用传参,@logger装饰器语句执行完后,打印add的名称和doc
那么能不能给logger设置一个阀值,执行时长超过阀值记录一下?

七、annotation注解
由于python是动态语言,太灵活,越灵活越难掌握
不到运行时,无法判断类型是否正确;
难发现:由于不做检查,往往到运行时问题才显现出来,或到了线上运行才暴露出来
难使用:函数使用者看到函数时,并不知道设计者的意图,如果没有详尽的文档,使用者只能猜测数据类型。也不知道返回类型是什么。
如何解决这个问题呢?
解决方法一:函数注解:
声明函数类型,这是非强制性约束

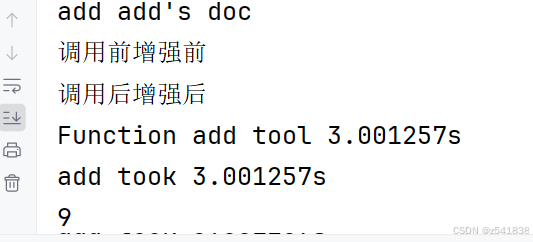
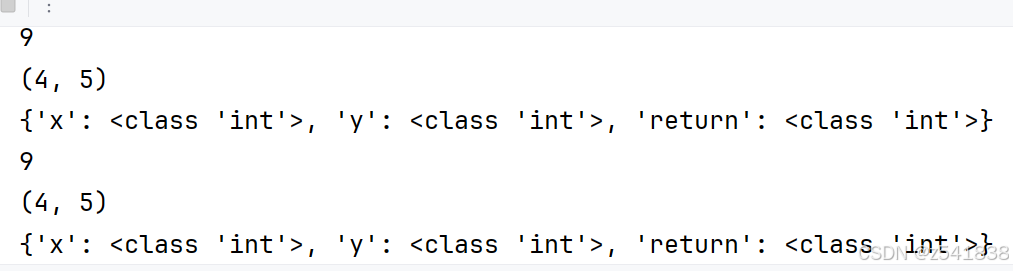
结果
也会出现函数传参的错误:如
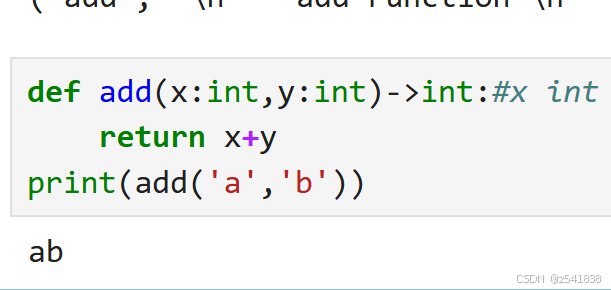
可以在函数内部写isinstance来判断参数类型是否正确,但是检查可以看做不是业务代码,写在里面就是侵入式代码。如
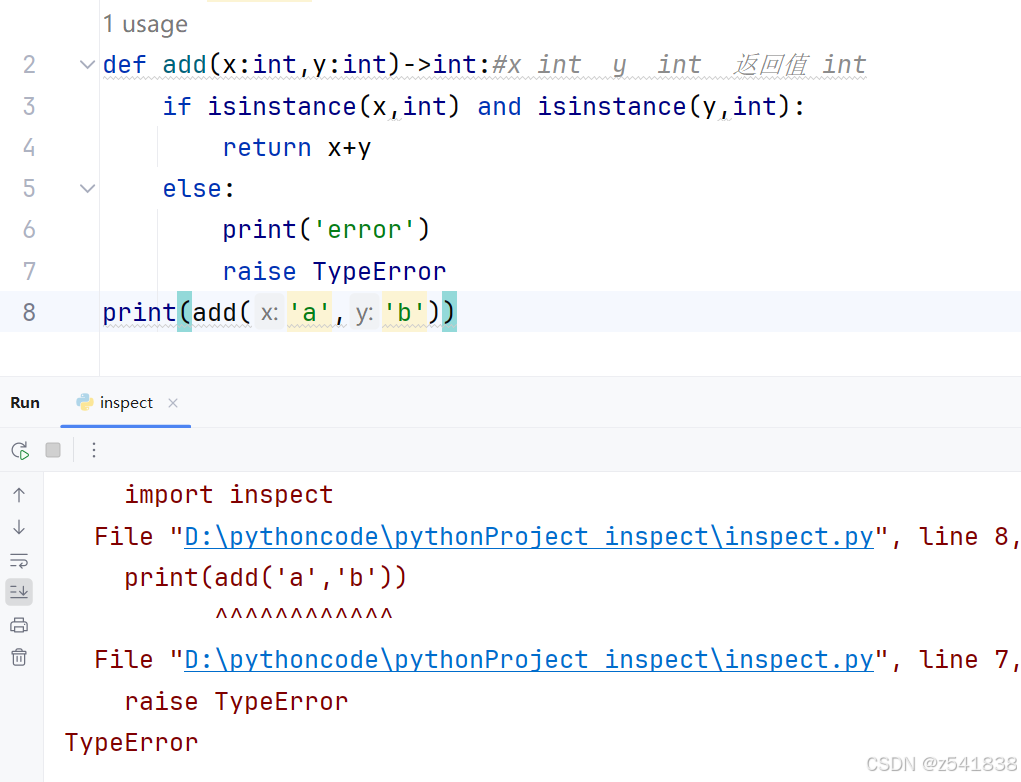
可以用装饰器来 解决首先先来了解一下inspect模块
七.1、inspect模块
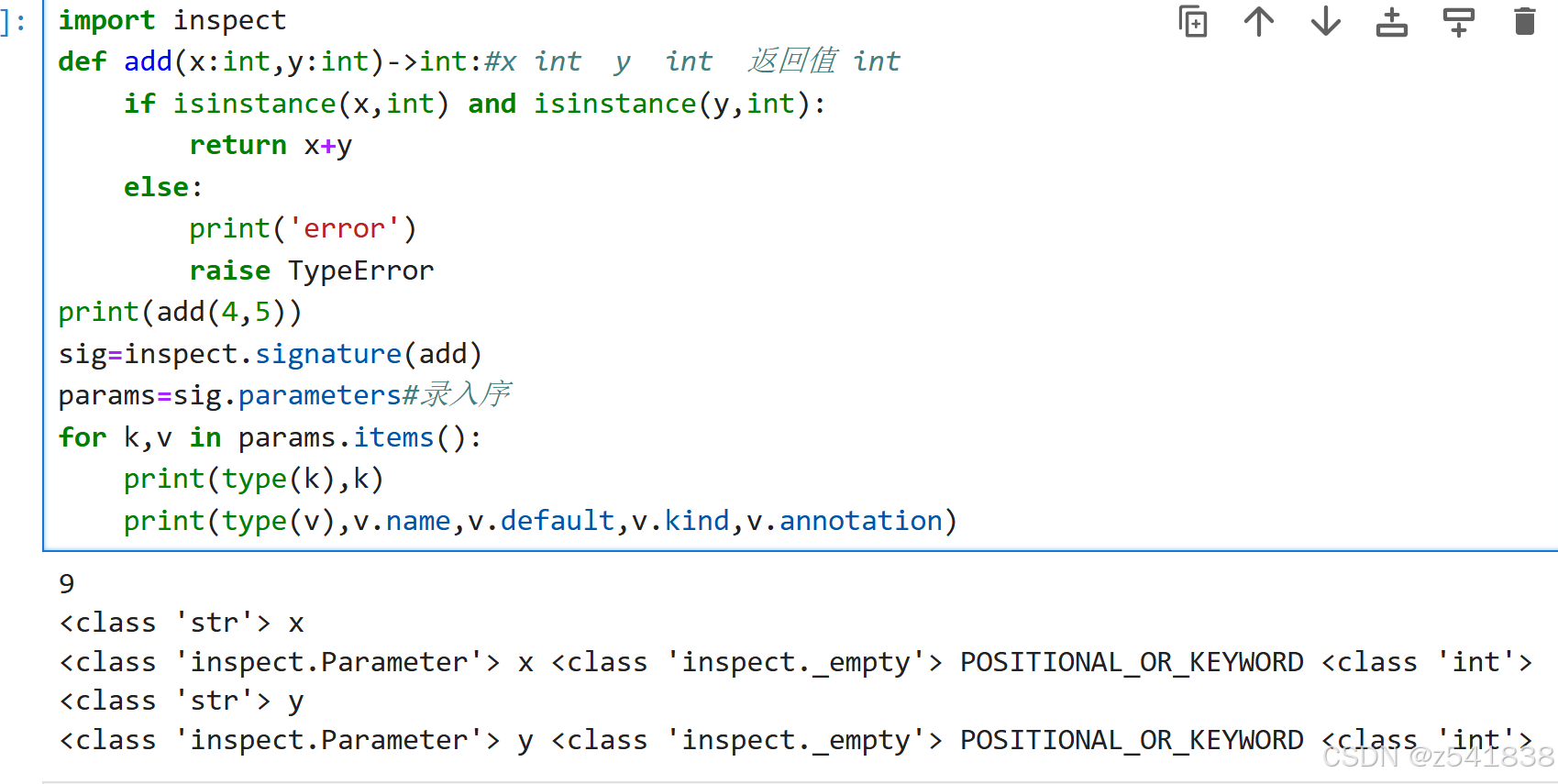
inspect模块是 Python 标准库中的一个强大工具,主要用于获取有关活动对象(如模块、类、方法、函数等)的信息。它提供了许多函数来检查对象的源代码、签名、模块路径等诸多细节。signature函数- 用于获取可调用对象(如函数、方法)的参数签名信息。它返回一个
Signature对象,其中包含了参数的名称、默认值、是否可变等信息。 - 首先,
inspect.signature获取了add的签名信息,打印sig会显示函数签名的整体情况,如(arg1, arg2 = 2)。而sig.parameters则是一个有序字典,包含了参数的详细信息,如参数名称、默认值等。可以通过遍历这个字典来获取每个参数的具体细节。
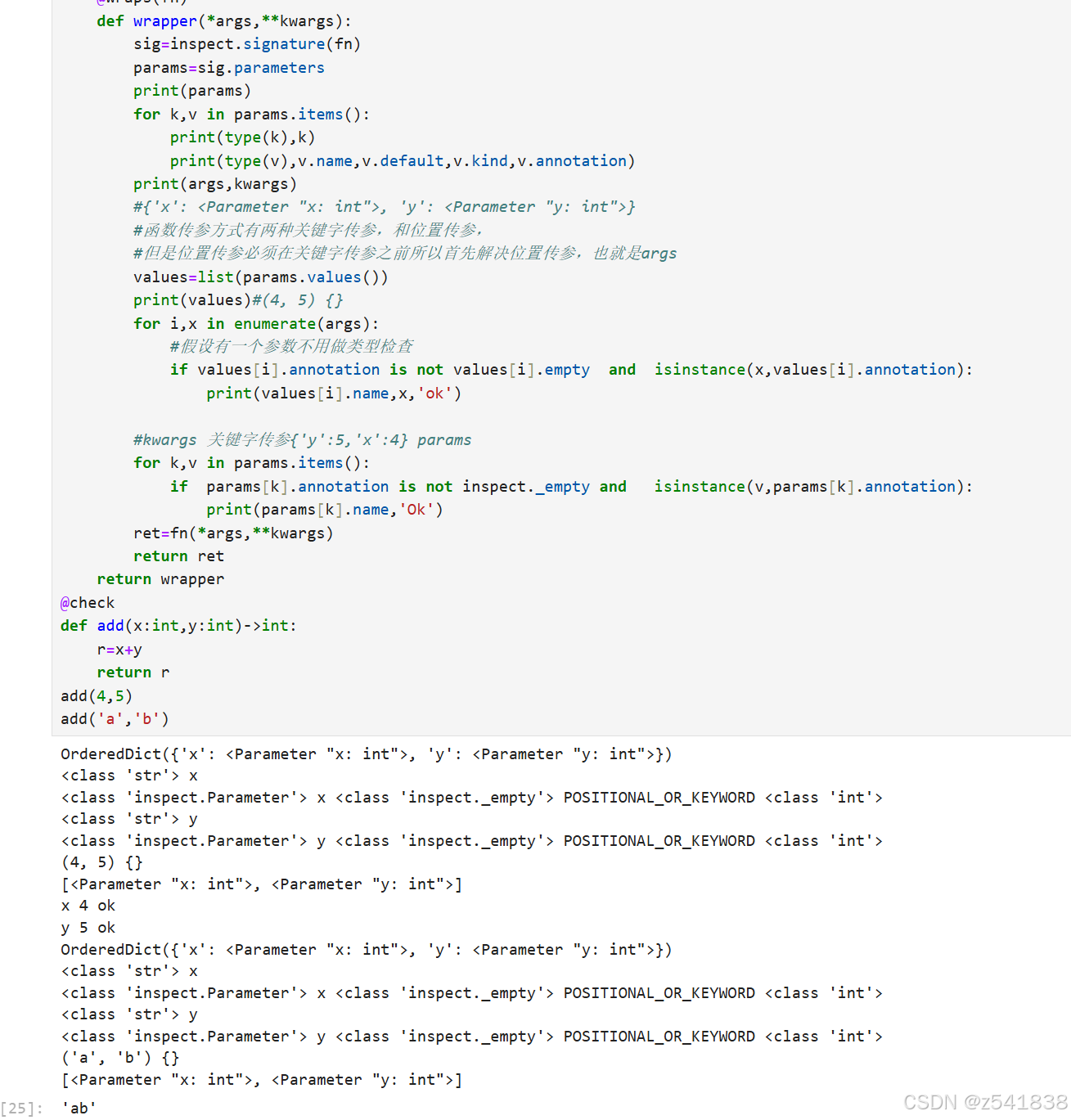
解决函数传参类型错误的问题
使用装饰器
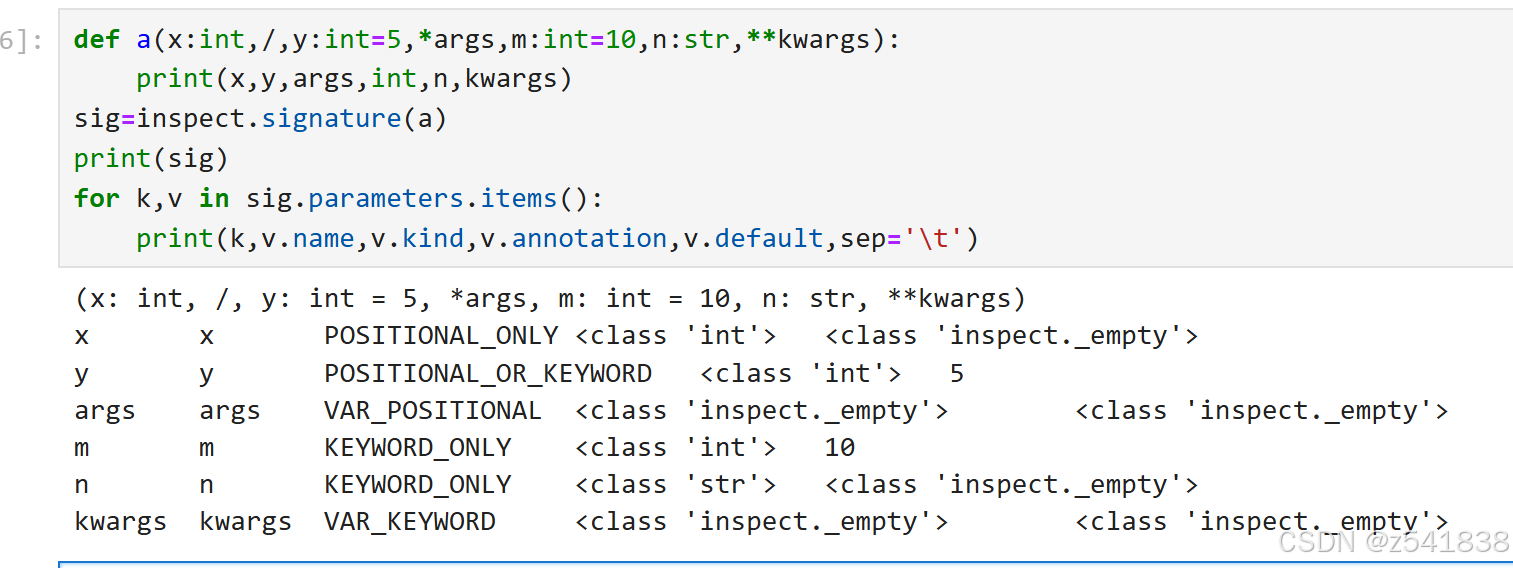
下面了解一下各个形参之间的属性
八、functools模块
8.1、reduce
functools.reduce(function,iterable[,initial])
就是减少的意思,如果初始值没有提供,就在可迭代对象中取一个
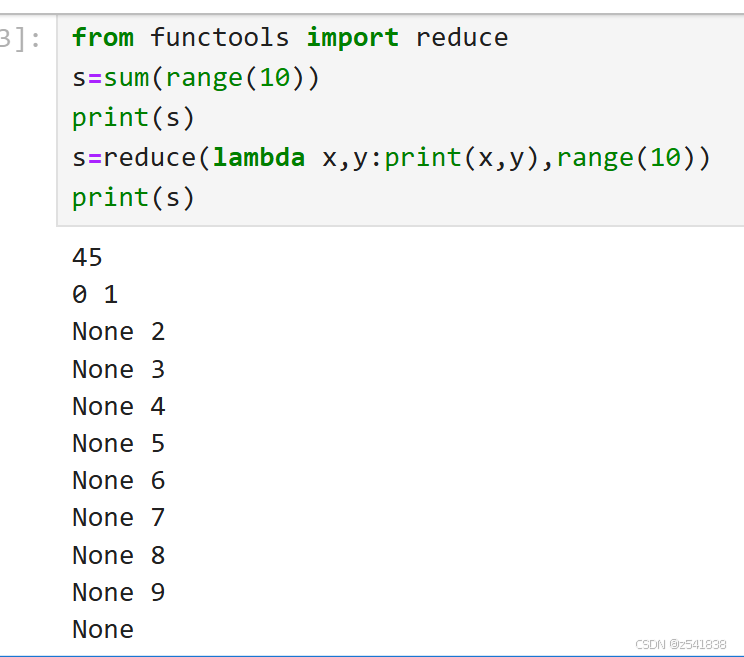
从上面可以看出reduce是迭代计算的,所以要让reduce实现sum去和功能,可以这样改
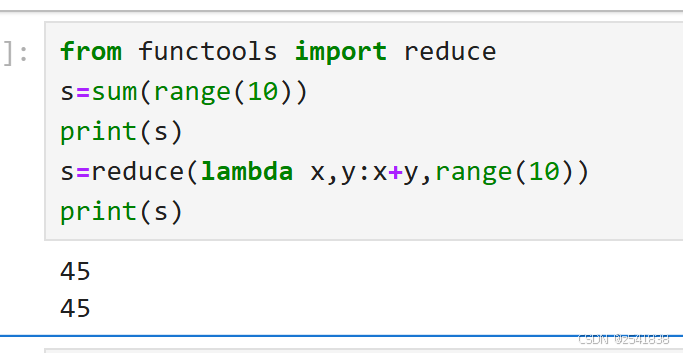
8.2、partial偏函数
把函数参数部分固定下来,相当于为部分参数添加固定默认值,想成一个新函数,并返回这个新函数。这个新函数是对原函数的封装。
如
例1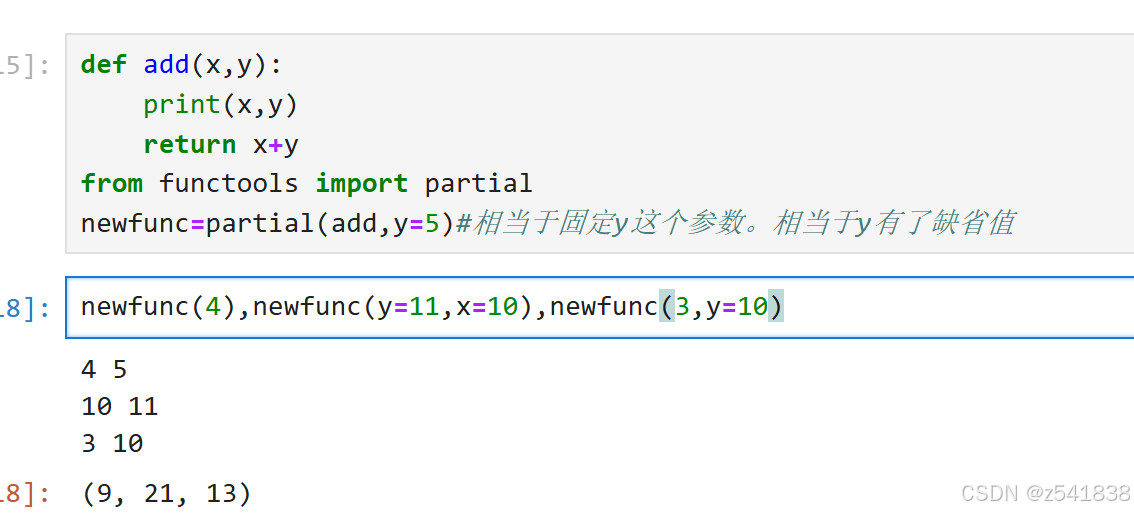
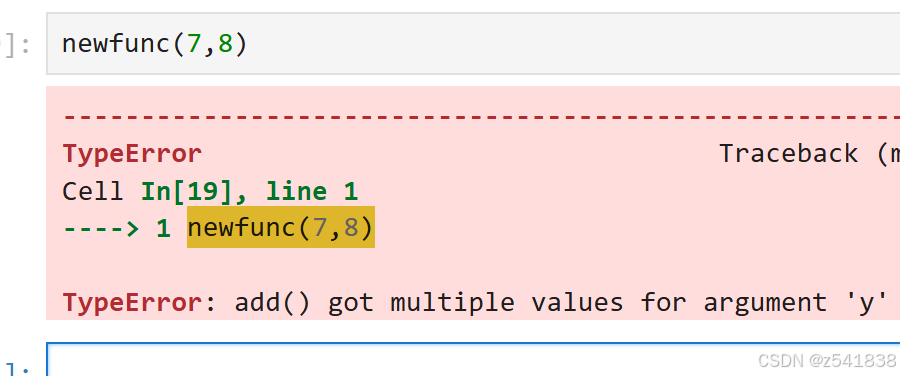
为什么newfunc(7,8)这种函数传参方式是错误的呢?很简单按位置传参的话就是newfunc(x=7,y=8,y=5)。形参y重复定义
如果你不知道如何传参,可以用函数签名来查看
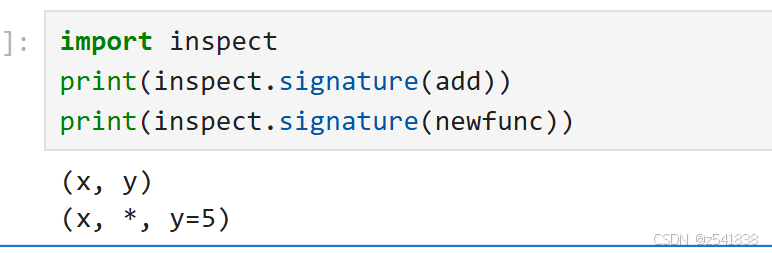
再来看一种
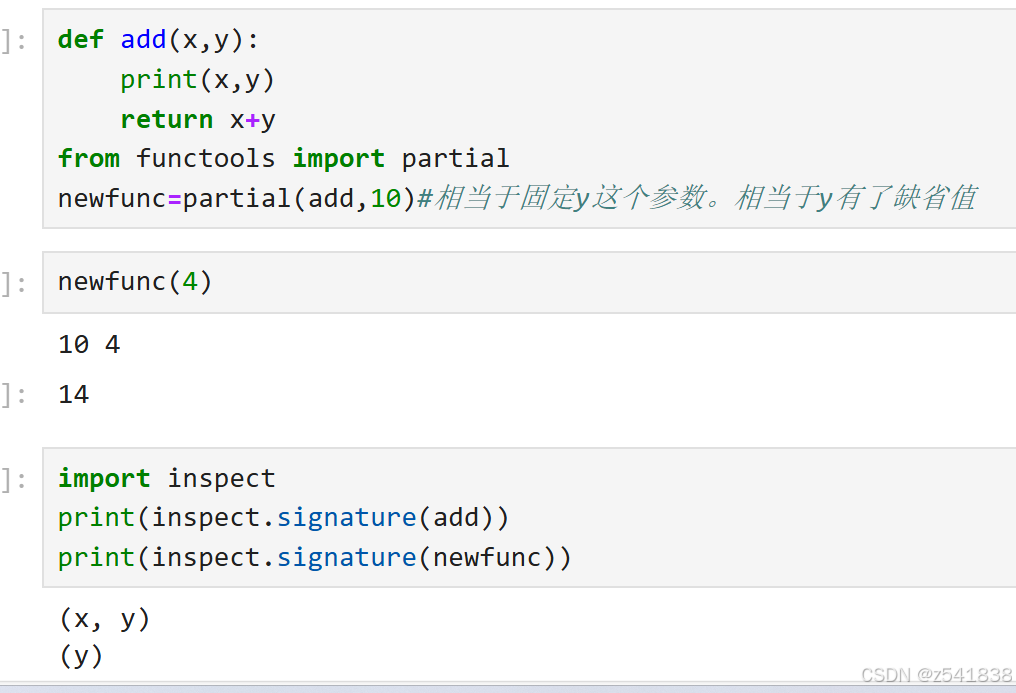
例2

第二种固定
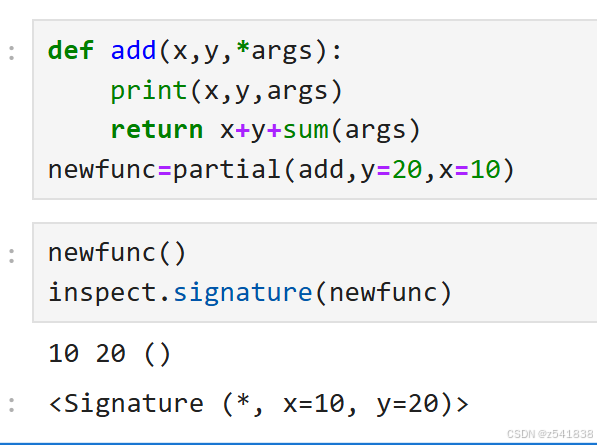
有标签可知,x和y是关键字传参,*是位置传参
newfunc(1,2)#重复定义 newfunc(y=1,x=2,*args,y=20,x=10)
如果你实现不了解partial如何传参,可以了解函数是如何实现的
这里参考的是python document

8.3 、lru-cache(最少使用,cache缓存)带参装饰器
functools.lru_cache(maxsize=128,typed=False)
- maxsize:这是
lru_cache最重要的参数,用于指定缓存的最大大小。- 如果
maxsize设置为None,缓存可以无限制地增长。这在某些情况下可能会导致内存占用过多,但对于一些计算成本非常高且输入参数组合有限的函数来说是很有用的。 - 如果
maxsize是一个整数,例如maxsize = 128,那么缓存最多存储 128 个函数调用的结果。当缓存已满,需要存储新的结果时,会根据 LRU 策略清除最久未被使用的缓存项。
- 如果
- typed:这是一个可选的布尔值参数。
- 如果
typed=True,lru_cache会分别缓存不同类型参数的结果。例如,fibonacci(1)和fibonacci(1.0)会被视为不同的调用,分别缓存它们的结果。 - 如果
typed=False(默认值),不会区分参数的类型
- 如果
应用斐波那契数列
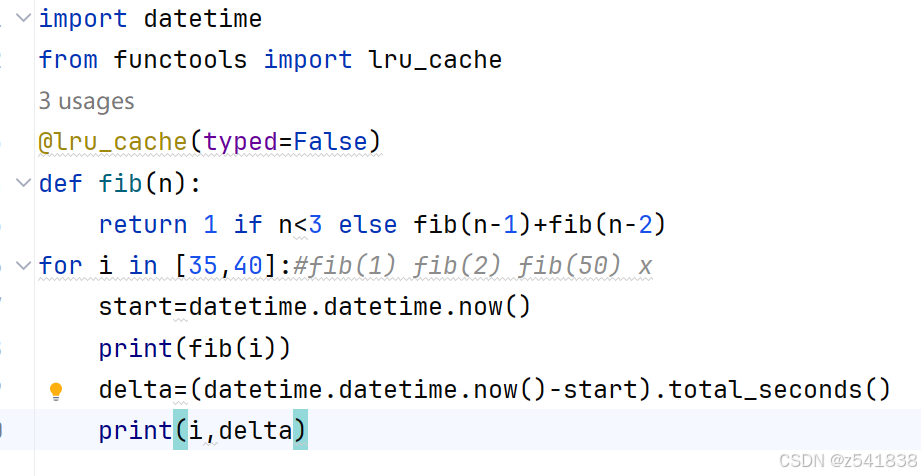
当调用fib函数时,例如fib(5),lru_cache会首先检查缓存中是否已经存在fib(5)的结果。如果存在,就直接返回缓存中的结果;如果不存在,就计算。也就是缓存命中,用空间换时间。