目录
4.3 AutoDL 部署Stable Diffusion过程
一、前言
随着开源大模型的兴盛,AI绘图大模型火热程度也越来越高,并且在众多的领域开始逐步商用,市面上也陆续出现了很多功能强大的AI绘图大模型,本文以开源大模型Stable Diffusion为例进行说明。
二、AI绘图大模型概述
2.1 AI绘图大模型介绍
AI绘图大模型是指利用人工智能技术,特别是深度学习算法来生成图像的模型。这些模型通常能够根据文本描述或其他形式的输入生成相应的图像,具有较高的艺术价值和技术含量。
2.2 AI绘图大模型特点
以下是一些典型的AI绘图大模型的特点
-
大规模数据训练
-
这些模型通常是在大规模的图像数据集上进行训练,以便学习到丰富的视觉特征和模式。
-
-
多模态能力
-
一些绘图大模型具备多模态的能力,即可以从多种类型的数据(如文本、音频、视频等)中生成图像。
-
-
复杂的神经网络架构
-
这些模型往往采用复杂的神经网络架构,如Transformer、ResNet等,来捕捉图像中的高级抽象特征。
-
-
预训练与微调
-
许多绘图大模型会经历预训练和微调两个阶段。预训练阶段通常使用大量未标注数据来学习通用特征表示,而在微调阶段则会在特定任务上进一步优化模型。
-
-
高计算需求
-
训练和运行这些模型通常需要大量的计算资源,如GPU或TPU等高性能计算硬件。
-
2.3 AI绘图大模型优势
AI绘图大模型具有如下显著优势
-
强大的生成能力
-
AI绘图大模型可以生成高质量、高分辨率的图像,并且可以根据输入文本或其他形式的提示生成对应的图像。
-
-
多样化的风格
-
这些模型可以模仿多种艺术风格,从写实到抽象,从传统绘画到现代数字艺术。
-
-
创新的设计辅助
-
在设计领域,AI绘图模型可以作为设计师的辅助工具,帮助他们快速产生概念草图或者完整的艺术作品。
-
-
高效的图像编辑
-
除了生成图像,一些模型还提供了图像编辑功能,如局部修改、风格转换等。
-
-
跨领域应用
-
AI绘图模型的应用范围非常广泛,包括但不限于游戏开发、动画制作、广告设计、建筑设计等多个行业。
-
-
易于集成
-
许多AI绘图模型都提供了API接口或者可以直接在云端服务中使用,使得它们很容易被集成到现有的工作流程中。
-
-
实时反馈
-
用户可以即时看到模型生成的结果,并根据需要进行调整,提高了创作效率。
-
这些特点和优势使得AI绘图大模型成为了当前创意产业中的重要工具,不仅能够加速创作过程,还能激发新的创意方式。然而,值得注意的是,随着技术的发展,也应该关注到AI绘图可能带来的版权问题、隐私保护以及伦理道德等方面的影响。
三、主流的AI绘图大模型介绍
近几年,随着AI大模型技术的成熟,以及算力的逐步提升,市面上涌现出一批优秀的开源AI绘图大模型工具,下面选取几种主流的AI绘图大模型加以说明。
3.1 Midjourney
3.1.1 Midjourney介绍
Midjourney 是一家位于美国加州旧金山的人工智能公司,成立于2021年,以开发基于AI的图像生成工具而知名。Midjourney 的主要产品是一款基于人工智能的图像生成工具,允许用户通过输入文本描述来自动生成相应的图像。这一工具的特点包括高质量图像生成、简单易用、个性化风格支持、无需专业技能即可使用、灵活的授权选项以及强大的开放API。中文网站:MJ中文站 - 专业AI绘图网站
3.1.2 Midjourney功能特点
Midjourney的主要功能和特点总结如下:
-
高质量图像生成
-
Midjourney 可以根据用户提供的描述,生成具有高度真实感和艺术性的图像。
-
-
简单易用
-
用户只需输入描述性的文本,Midjourney 即可自动完成图像生成,操作简单快捷。
-
-
个性化风格
-
用户可以选择不同的艺术风格,比如模仿著名艺术家的作品风格,如安迪·沃霍尔、达芬奇、达利和毕加索等。
-
-
无需专业技能
-
Midjourney 对用户的专业技能要求不高,任何人都可以轻松使用,不需要具备专业的设计或编程知识。
-
-
灵活的授权选项
-
用户可以根据自身需求选择合适的授权方案,适用于个人项目或是商业用途。
-
-
强大的开放API
-
开发者可以利用Midjourney提供的API将图像生成功能集成到自己的应用程序中,扩展其功能。
-
3.1.3 Midjourney使用场景
Midjourney使用场景众多,下面列举了一些常用的应用场景
-
内容创作:作家、博客作者、社交媒体经理等可以用它来创建配图。
-
UI/UX设计:设计师可以用它来快速生成设计原型中的图像元素。
-
书籍插画:为出版物提供快速且低成本的插图解决方案。
-
广告设计:广告制作人可以用来快速创建广告素材。
-
游戏资源:游戏开发者可以利用它来生成游戏中的图像资源。
Midjourney 作为一个新兴的AI绘图工具,在短时间内获得了广泛的使用,并且随着技术的不断进步,它正逐渐拓展其业务范围,不仅限于软件层面,也开始涉足硬件开发。
3.2 Stable Diffusion
3.2.1 Stable Diffusion介绍
Stable Diffusion 是一个开源的人工智能模型,用于生成图像。它是由 Stability AI 团队开发的,该模型基于扩散模型(Diffusion Model)原理,该原理是一种能够生成高质量图像的概率模型。Stable Diffusion 的一大特点是它的开源性质,这意味着任何人都可以自由地使用、修改和分发这个模型,这对于促进研究和创新是非常有利的。
3.2.2 Stable Diffusion特点
Stable Diffusion具备如下特点:
-
开源
-
Stable Diffusion 是完全开源的,这使得研究人员和开发者可以查看和修改其源代码,促进了技术的透明度和社区合作。
-
-
高性能
-
尽管是开源的,Stable Diffusion 仍然能够生成高质量的图像,其性能与许多专有的图像生成模型相当甚至更好。
-
-
用途广泛
-
该模型不仅可以用于图像生成,还可以用于图像修复、超分辨率、风格迁移等多种图像处理任务。
-
-
使用门槛低
-
相比于其他图像生成模型,Stable Diffusion 在计算资源上的需求相对较低,可以在普通的GPU上运行,这降低了使用门槛。
-
-
可定制性好
-
用户可以根据自己的需求对模型进行微调,以适应特定的任务或风格。
-
-
社区活跃
-
由于其开源特性,Stable Diffusion 拥有一个活跃的开发者社区,这有助于模型的持续改进和支持。
-
3.2.3 Stable Diffusion应用场景
Stable Diffusion具备丰富的使用场景,如下
-
艺术创作:艺术家可以利用Stable Diffusion来创造独特的视觉效果。
-
设计辅助:设计师可以快速生成设计概念图或原型。
-
科学研究:研究人员可以使用该模型来生成模拟数据或进行数据增强。
-
教育:教育工作者可以使用它来生成教学材料或可视化工具。
Stable Diffusion 是一款功能强大且灵活的图像生成工具,它的开源特性和高性能使其成为学术界和工业界广泛应用的选择。随着社区的不断贡献和技术的进步,Stable Diffusion 有望在未来继续发展和完善。
3.3 Adobe Firefly
Adobe Firefly 是由Adobe公司开发的一款创意生成式人工智能工具。这款工具最初发布于2023年3月22日,旨在帮助设计师和创意专业人士更高效地创作图像、文本效果和其他多媒体内容。
3.3.1 Adobe Firefly功能特点介绍
Adobe Firefly具备如下功能
-
图像生成
-
用户可以通过简单的文本描述来生成图像内容。例如,输入一段描述性的文字,Firefly 就能生成相应的图像。
-
-
文本效果生成
-
Firefly 支持生成文本效果,包括字体样式、布局和视觉风格等,这为设计师提供了更加丰富的文本设计选择。
-
-
创意辅助
-
Firefly 提供了构思、创作和沟通的新方式,帮助创意人员快速将想法转化为实际作品。
-
-
工作流程改进
-
通过自动化某些创意任务,Firefly 显著改善了创意工作流程,提高了创作效率。
-
-
多平台支持
-
Firefly 可以通过网页端使用,无需下载额外的软件,使得创作过程更加便捷。
-
-
风格多样化
-
用户可以调整图像的风格、颜色、光照等属性,创造出符合具体需求的独特视觉效果。
-
3.3.2 Adobe Firefly使用场景
总结来说,Adobe Firefly具备如下使用场景
-
图像设计:包括广告、海报、宣传册等平面设计需求。
-
文本设计:为PPT、报告、杂志等文档提供富有创意的文本效果。
-
视频编辑:Firefly 还支持自动剪辑工具,可以依据输入的文字和指令自动生成视频内容,包括背景音乐、音效匹配、视频调色等。
-
3D图像生成:虽然初始版本主要集中在图像和文本效果生成上,但后续计划扩展至3D模型生成等功能。
-
未来发展:集成Adobe生态系统:Firefly 计划与Adobe其他产品(如Photoshop、Illustrator、Premiere Pro等)深度整合,形成更加紧密的工作流。
Adobe Firefly 代表了Adobe对于未来创意工作的愿景——通过AI技术赋能创意人士,让他们能够更加专注于创意本身,而不是繁琐的技术细节。随着技术的进步和功能的不断完善,Adobe Firefly 预计将成为创意行业中的重要工具之一。
3.4 DALL·E
3.4.1 DALL·E 介绍
DALL·E 是由 OpenAI 开发的一种人工智能系统,专门用于根据文本描述生成图像。这个名字结合了迪士尼电影中的机器人WALL·E和西班牙超现实主义画家Salvador Dalí的名字,暗示了其生成图像的能力既有创造性的元素也有超现实主义的风格。
3.4.2 DALL·E 特点
DALL·E主要有如下特点
-
文本到图像的转换
-
DALL·E 可以接受自然语言描述的文本输入,并据此生成相应的图像。例如,它可以生成像“穿着燕尾服抽雪茄的臭鼬”这样的复杂图像。
-
-
高质量图像生成
-
生成的图像通常具有较高的分辨率和质量,能够展现复杂的细节和色彩。
-
-
多样性
-
DALL·E 可以根据相同的文本描述生成不同风格和视角的图像,提供了多样化的选择。
-
-
多模态能力
-
除了文本到图像的转换,DALL·E 2(第二代模型)还能够进行图像到图像的转换,即对现有图像进行修改或合成新图像。
-
-
无痕编辑
-
DALL·E 2 具备无痕编辑能力,可以无缝地在现有图像中添加、删除或替换对象,使编辑后的图像看起来自然。
-
3.4.3 DALL·E 技术背景
-
神经网络架构:DALL·E 使用了Transformer架构,这是一种在自然语言处理(NLP)中表现优秀的神经网络模型。
-
训练数据:DALL·E 是在大量的文本-图像对数据集上进行训练的,从而学习到了文本描述与图像之间的映射关系。
-
生成过程:DALL·E 在生成图像时,会先生成一个较小的预览图像,然后通过一系列步骤放大并细化这个图像,直到达到所需的分辨率和细节水平。
3.4.4 DALL·E 应用场景
DALL·E 在下面的场景中得到了广泛的使用
-
创意设计:设计师可以利用DALL·E 来快速生成概念图或进行头脑风暴。
-
插图制作:书籍、文章、网站等需要插图的地方可以使用DALL·E 自动生成图像。
-
教育与科普:用于制作教育材料中的插图,特别是科学或技术领域的复杂概念。
-
娱乐与媒体:可用于生成电影、游戏、动画等媒体内容中的视觉元素。
DALL·E 和 DALL·E 2 的推出标志着人工智能在图像生成领域的重大进步,同时也引发了关于版权、隐私以及伦理等方面的讨论。随着技术的不断发展,这类AI系统在未来的应用将会越来越广泛。
四、基于AutoDL部署Stable Diffusion
4.1 部署Stable Diffusion环境说明
部署 Stable Diffusion 需要一定的环境配置,下面是基本的环境要求
-
操作系统
-
Linux 或 macOS 是最常见的选择,Windows 也可以使用,但通常不是首选。
-
-
Python环境:
-
Python 3.7+ 是必须的,建议使用 Python 3.8 或更高版本。
-
-
CUDA/GPU支持:
-
对于高性能的图像生成任务,建议使用带有 NVIDIA CUDA 支持的 GPU。至少需要支持 CUDA 10.1 或更高版本。
-
-
内存和存储空间:
-
至少需要 16GB 的 RAM。
-
至少需要 20GB 的可用磁盘空间用于安装依赖库和模型文件。
-
4.2 AutoDL 介绍
AutoDL(Automated Deep Learning)是一个旨在简化深度学习模型构建、训练和优化过程的研究领域和工具集合。AutoDL 的目标是通过自动化机器学习(AutoML)技术,让非专家也能利用深度学习解决各种问题,同时让专家能够更专注于高级别的设计和创新工作。
4.2.1 AutoDL 特点
AutoDL(Automated Deep Learning)是指自动化深度学习,它涵盖了自动化的模型设计、训练、优化等多个方面,旨在简化和加速深度学习模型的开发和部署过程。以下是AutoDL的一些主要特点:
-
自动化架构搜索(NAS)
-
自动设计模型:AutoDL 使用算法自动探索潜在的神经网络架构,从而找到最适合特定任务的模型结构。
-
减少人工干预:通过自动化架构搜索,可以减少人工设计模型所需的时间和精力,使得模型设计过程更加高效。
-
-
超参数优化(HPO)
-
优化模型性能:自动调整模型训练过程中的超参数,如学习率、批大小、优化器类型等,以找到最优的设置组合。
-
提高效率:通过自动化超参数优化,可以避免手动调参带来的试错周期,从而提高开发效率。
-
-
自动特征工程(AFE)
-
简化数据预处理:自动从原始数据中提取有用的特征,简化数据预处理阶段,提高模型训练的效率。
-
增强模型表现:自动特征工程可以发现数据中的隐藏模式,有助于提高模型的表现。
-
-
模型压缩与加速
-
降低部署成本:通过量化、剪枝等技术减少模型大小,优化模型以适合边缘设备或移动设备的部署需求。
-
加速推理过程:模型压缩可以提高推理速度,使得模型在实际应用中更加高效。
-
-
自动模型融合
-
提高预测准确性:结合多个模型的优势,通过集成学习的方式提高预测准确性。
-
增强鲁棒性:模型融合可以减少单一模型的过拟合风险,提高系统的鲁棒性。
-
-
使用简单
-
降低门槛:通过提供用户友好的界面和工具,AutoDL 使得即使是没有深厚机器学习背景的用户也能使用深度学习技术。
-
标准化流程:标准化的流程和工具可以促进团队成员之间的协作,提高整体工作效率。
-
-
支持多种应用场景
-
广泛适用性:AutoDL 可以应用于图像识别、自然语言处理、语音识别、推荐系统等多个领域,具有广泛的应用前景。
-
适应性:AutoDL 能够根据不同应用场景的特点,自动调整模型设计和训练策略,以适应不同的任务需求。
-
-
持续优化
-
动态调整:AutoDL 系统可以随着时间的推移,根据反馈和新的数据动态调整模型和参数,保持模型的竞争力。
-
迭代改进:通过持续的数据收集和模型评估,AutoDL 能够不断迭代改进模型,确保其始终处于最佳状态。
-
通过这些特点,AutoDL不仅简化了深度学习模型的开发和部署过程,而且提高了模型的质量和应用效果,使得深度学习技术更加普及和实用。随着技术的发展,AutoDL将继续演进,为更多用户提供便利和价值。
4.3 AutoDL 部署Stable Diffusion过程
参考下面的操作步骤,基于AutoDL 部署Stable Diffusion的完整过程
4.3.1 注册账号
官网:AutoDL算力云 | 弹性、好用、省钱。租GPU就上AutoDL
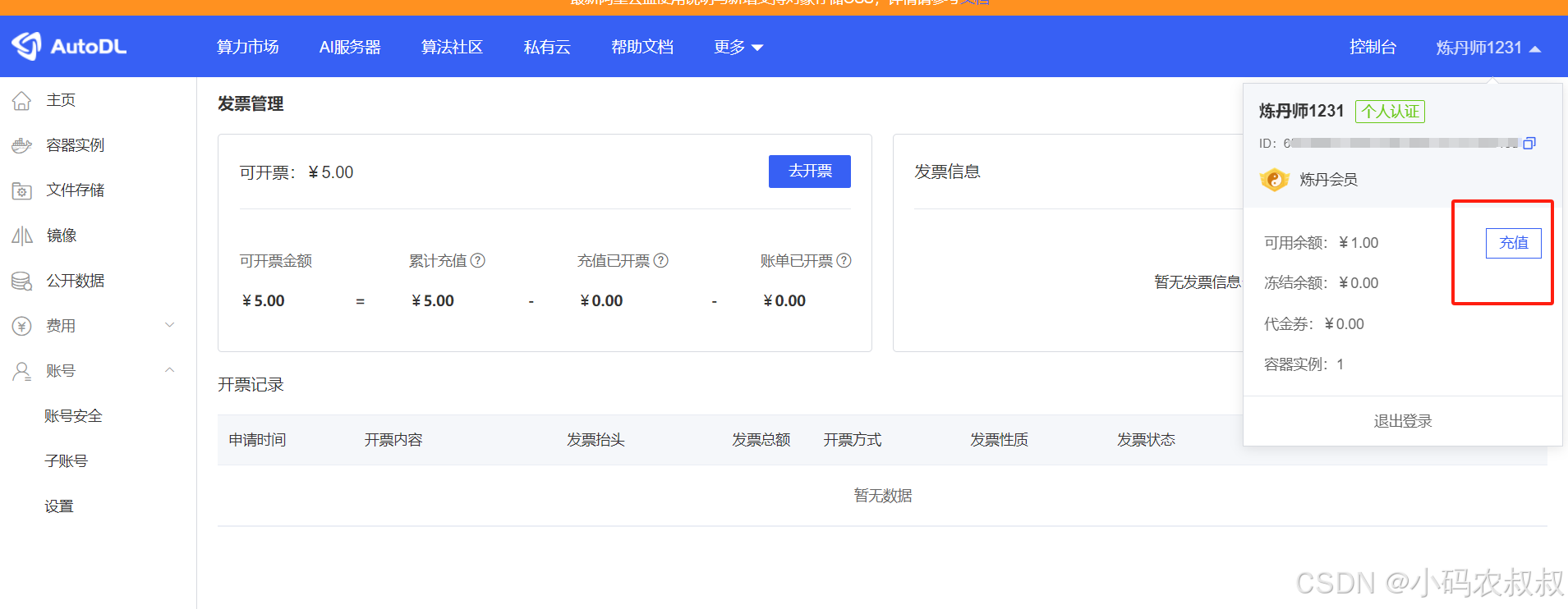
4.3.2 实名认证与充值
在控制台中充值费用,确保在使用过程中费用充足
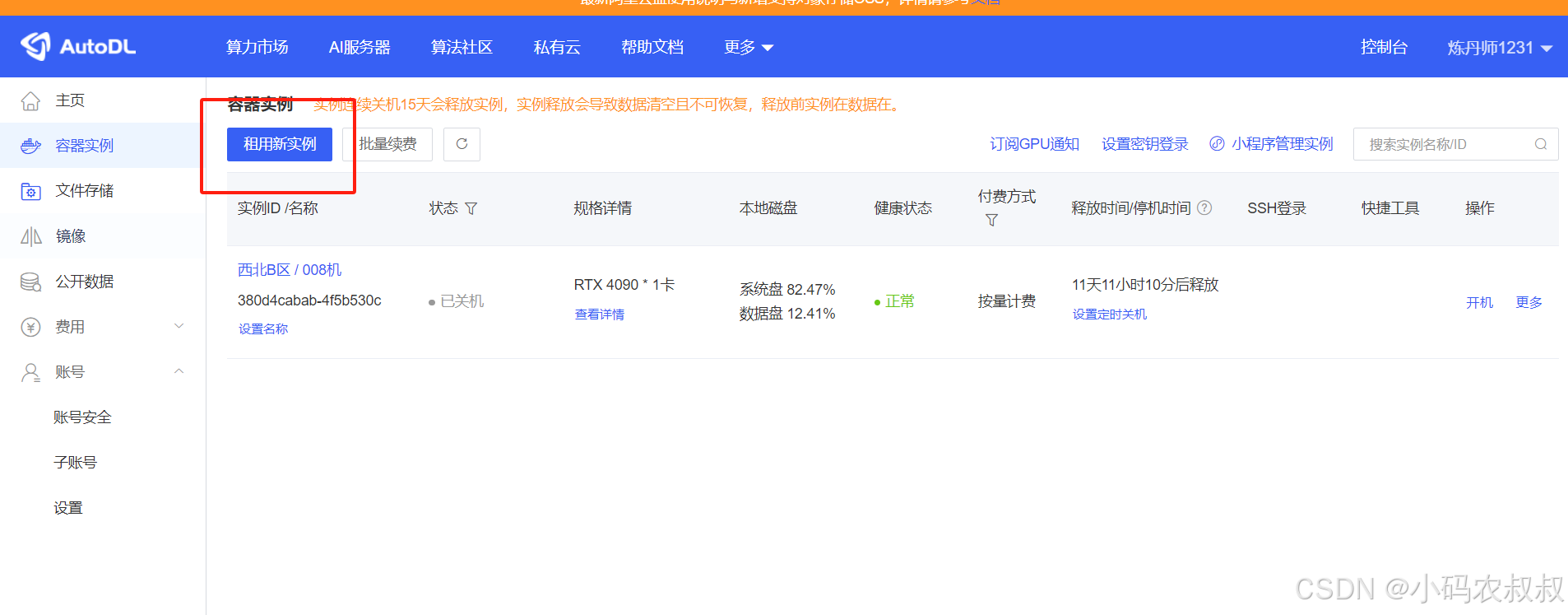
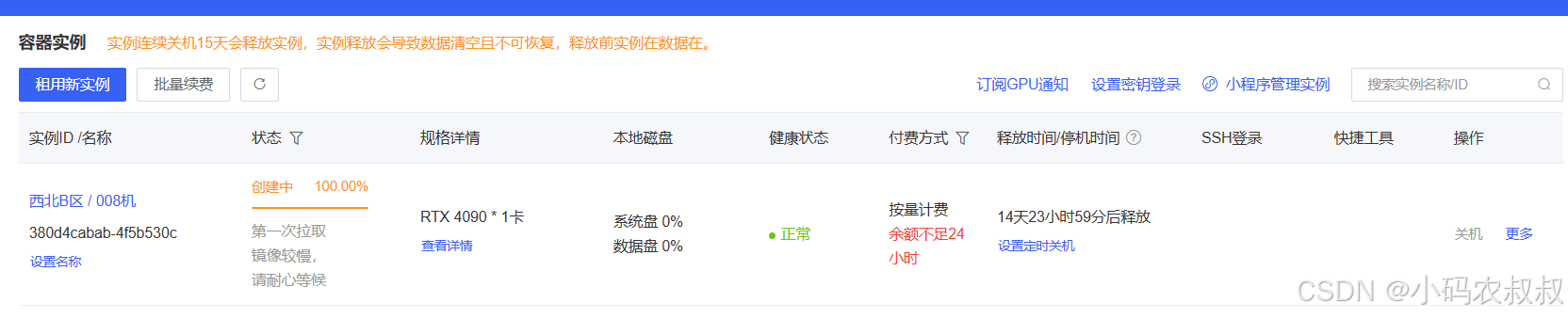
4.3.3 创建实例
账户充值之后,进入控制台,在容器实例那一栏,点击租用新实例
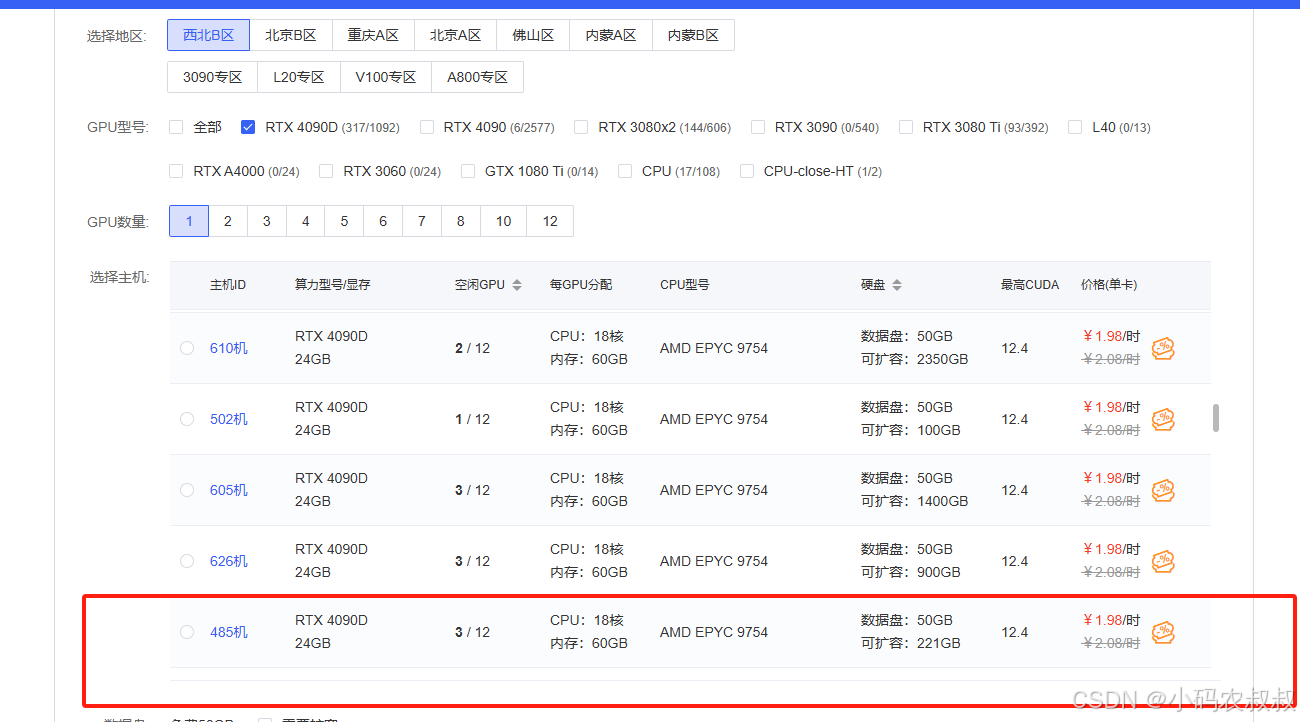
根据自身的情况选择配置,一般来说,只要满足Stable Diffusion运行的最低要求即可,下面是我选择的配置
4.3.4 选择合适版本的镜像
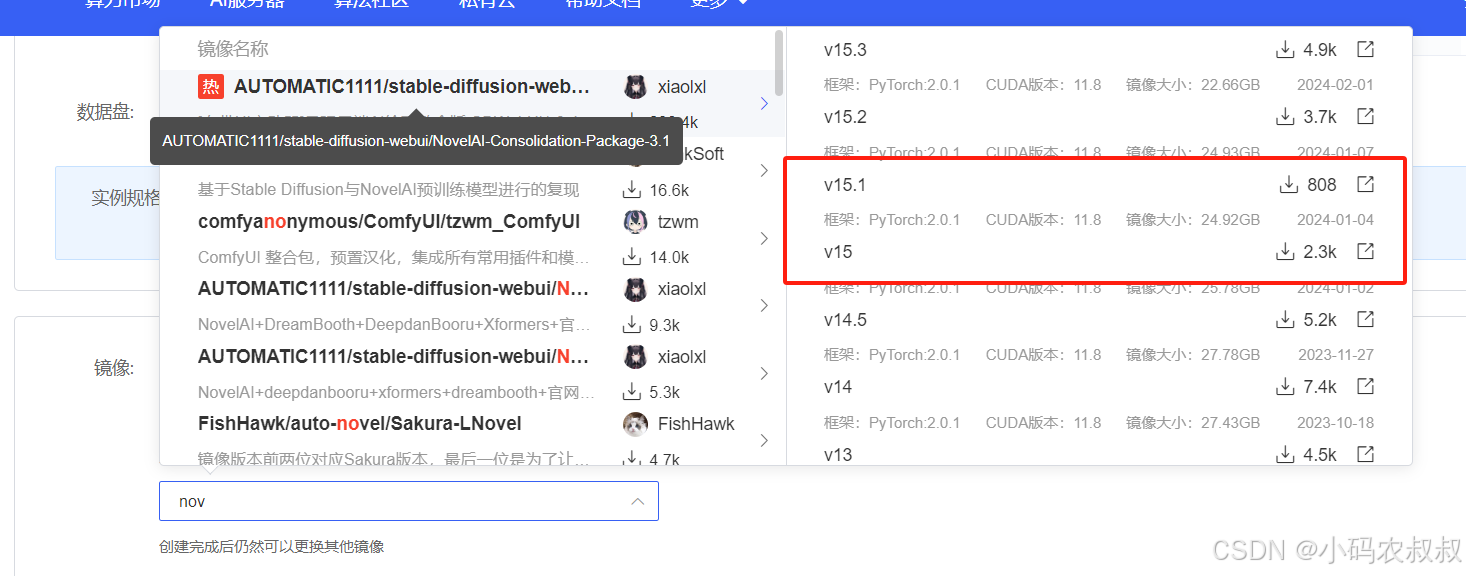
在社区镜像中搜索:nov ,选择右侧这两个版本都可以,我这里选择的是V15的版本,不同的版本,需要的服务器配置和算力要求不同,这个需要注意
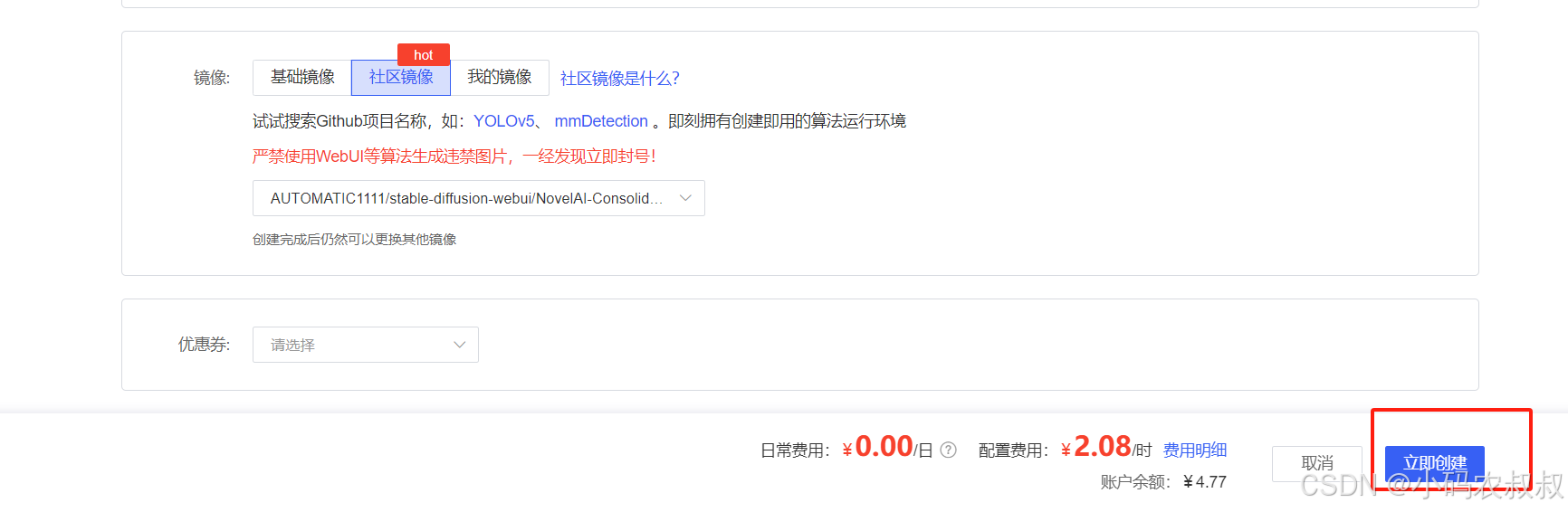
选择完成,点击立即创建

4.3.5 前置环境配置
从上一步的控制台中,点击下图的 Jupy那个链接
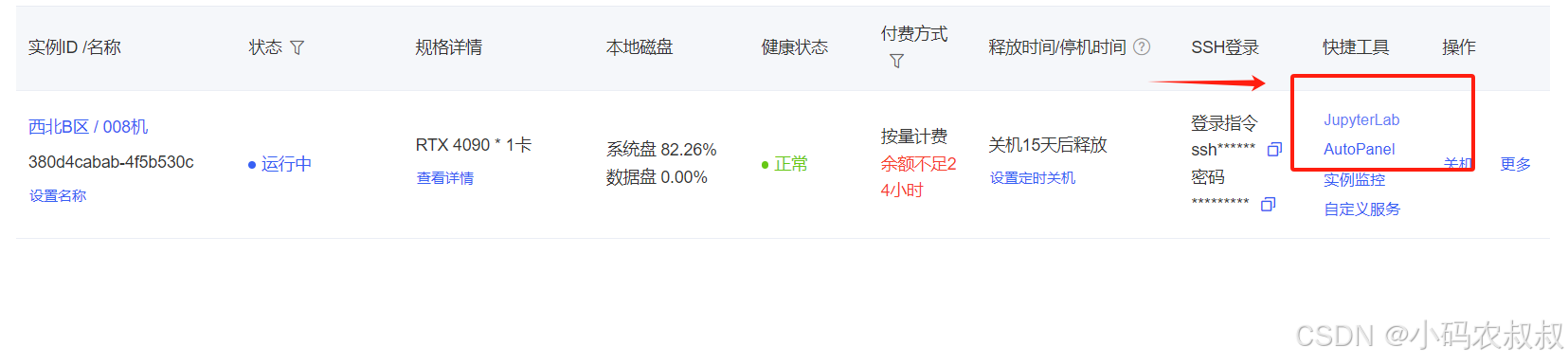
跳转到如下界面
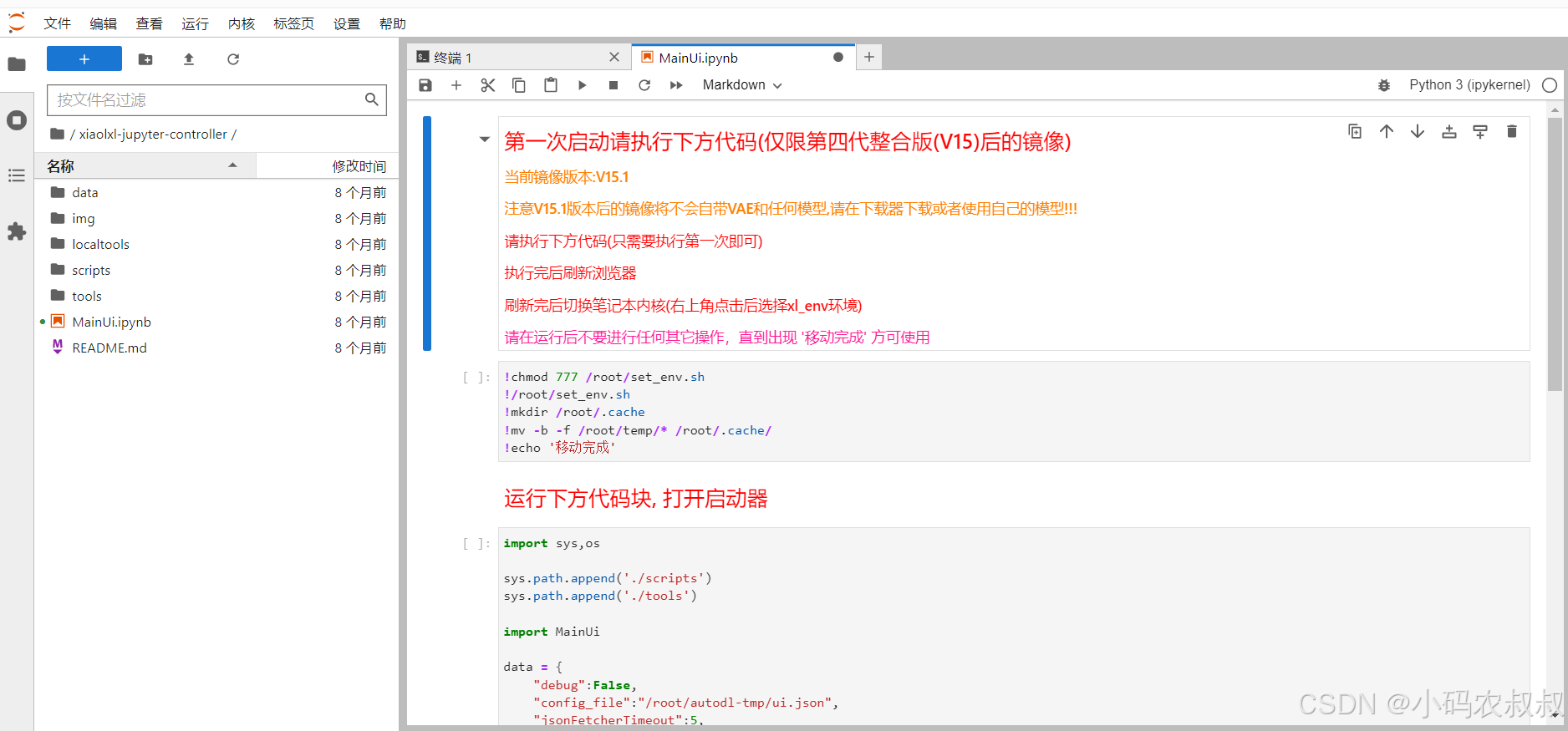
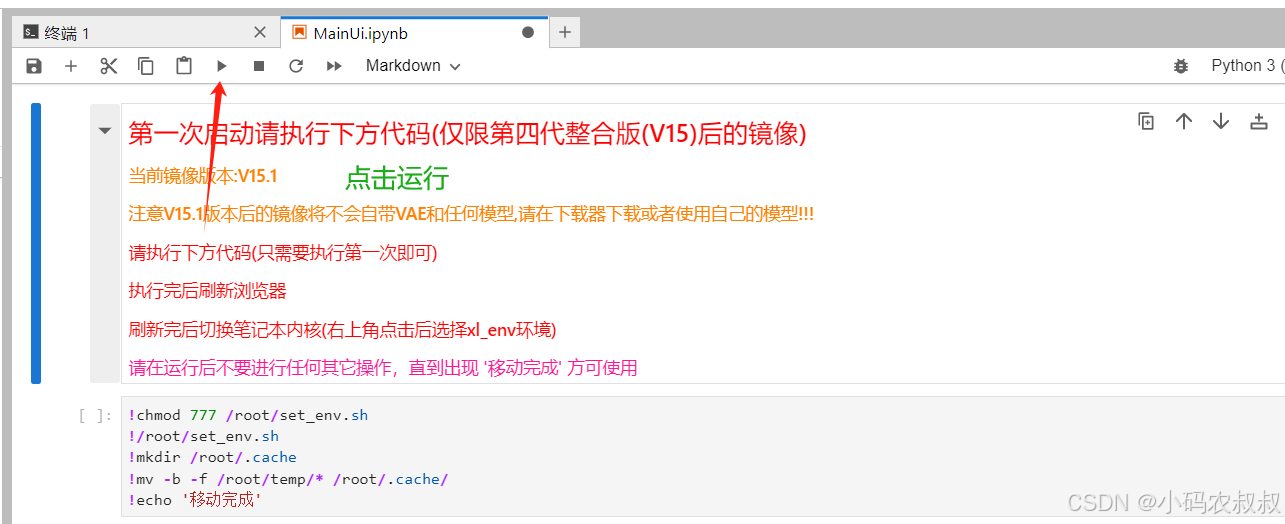
4.3.6 运行启动器
第一次点击运行
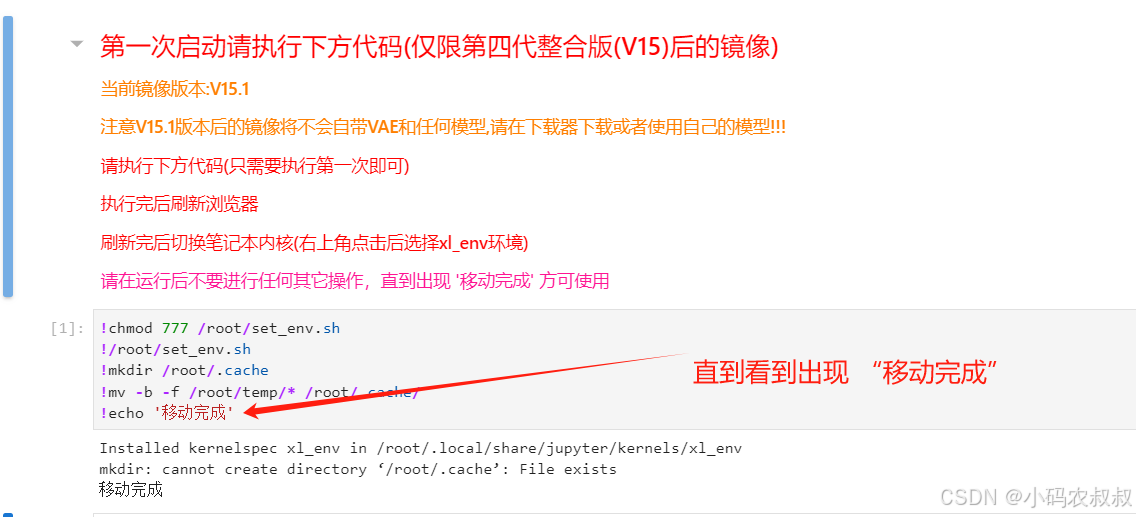
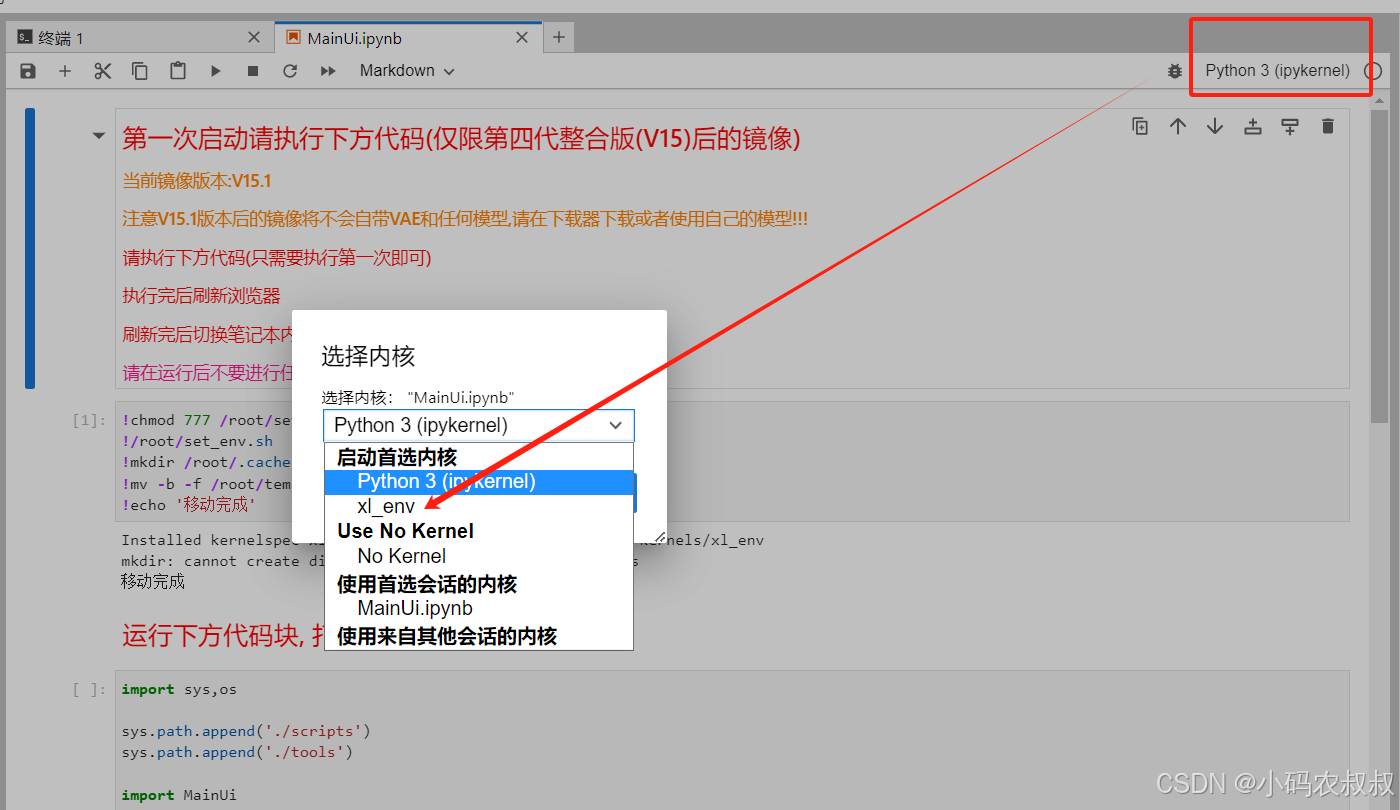
运行完成后刷新当前网页,点击右上角的按钮,选择下面这一项
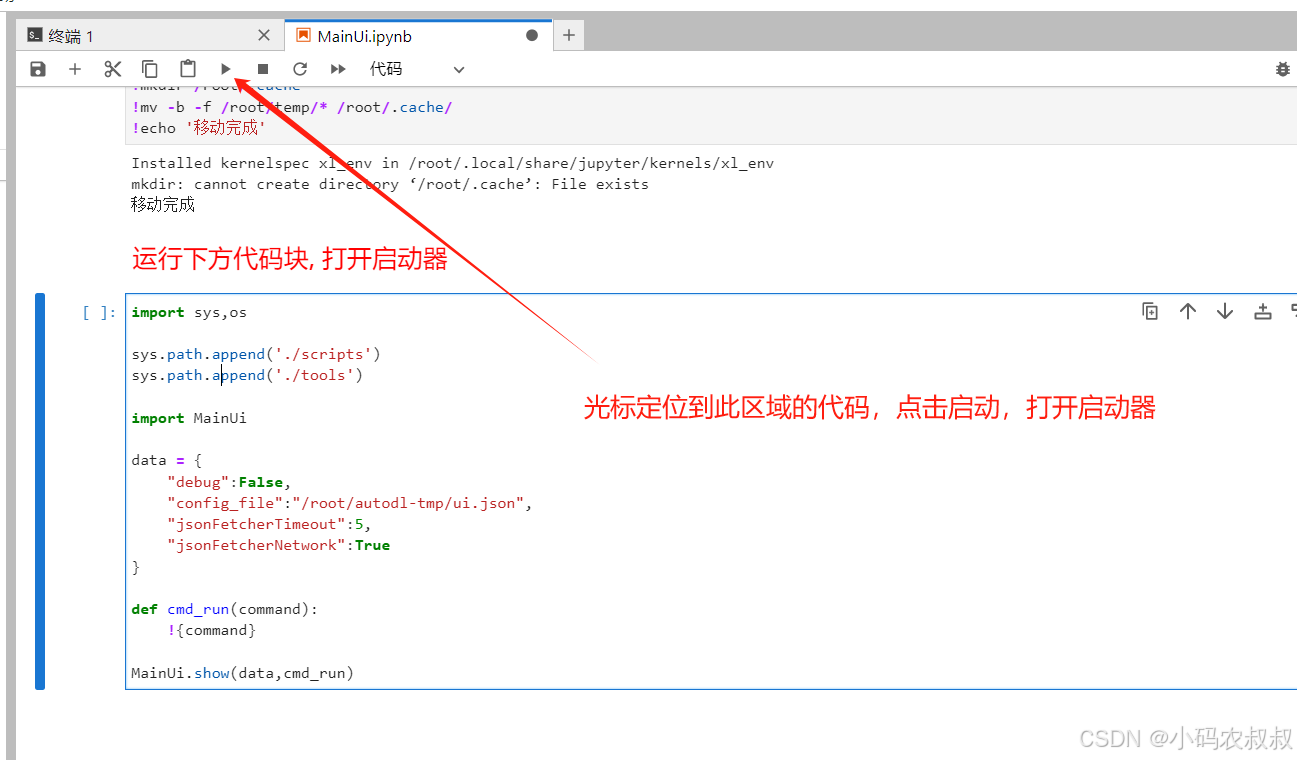
打开启动器
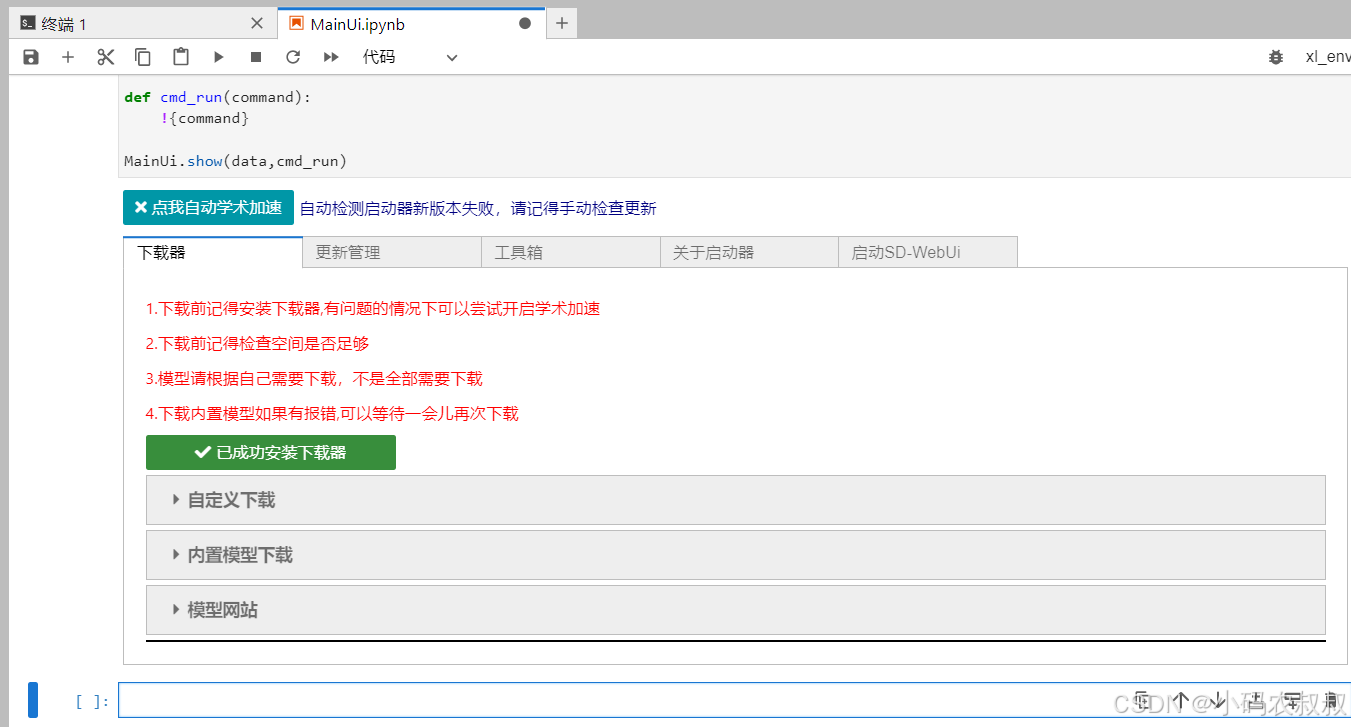
点击之后出现下面的界面
点击更新
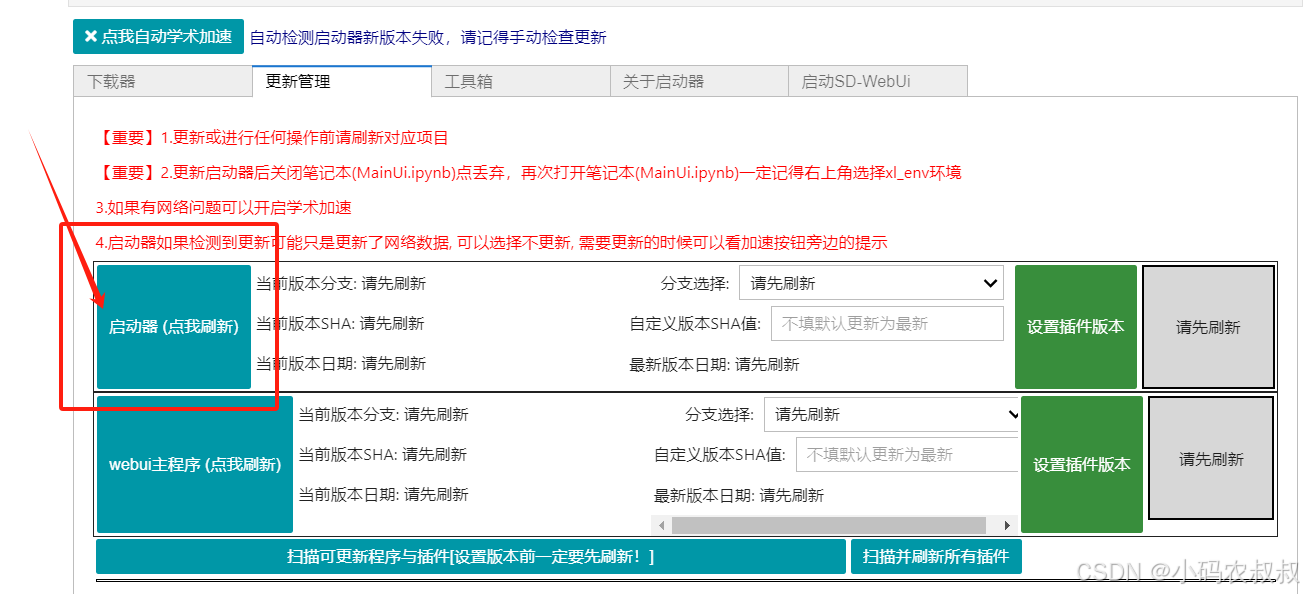
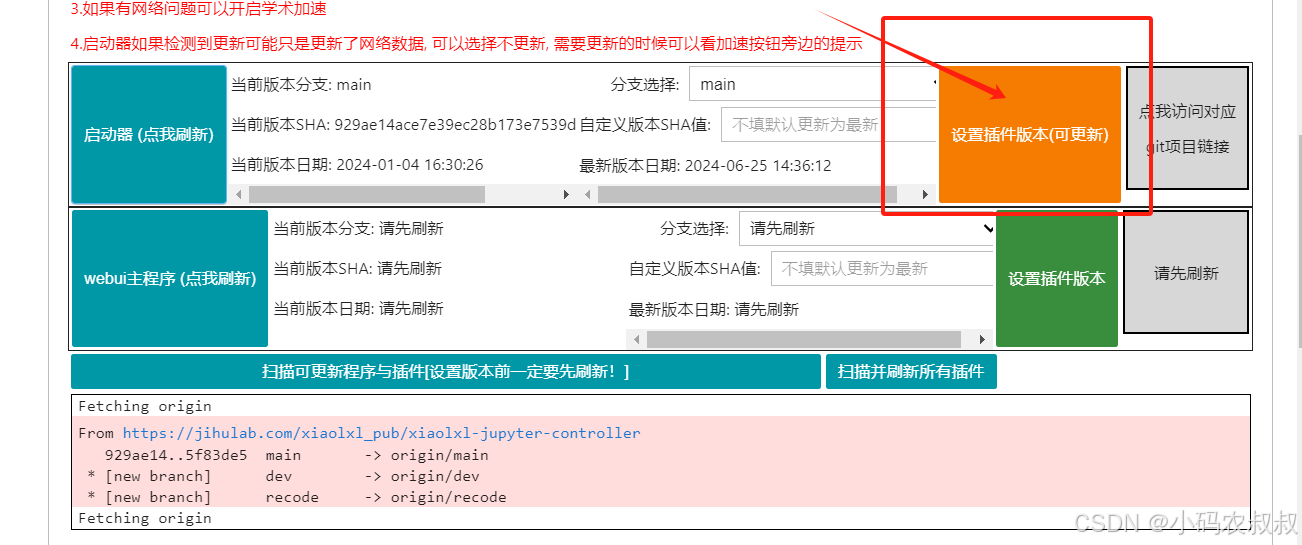
点击设置插件版本
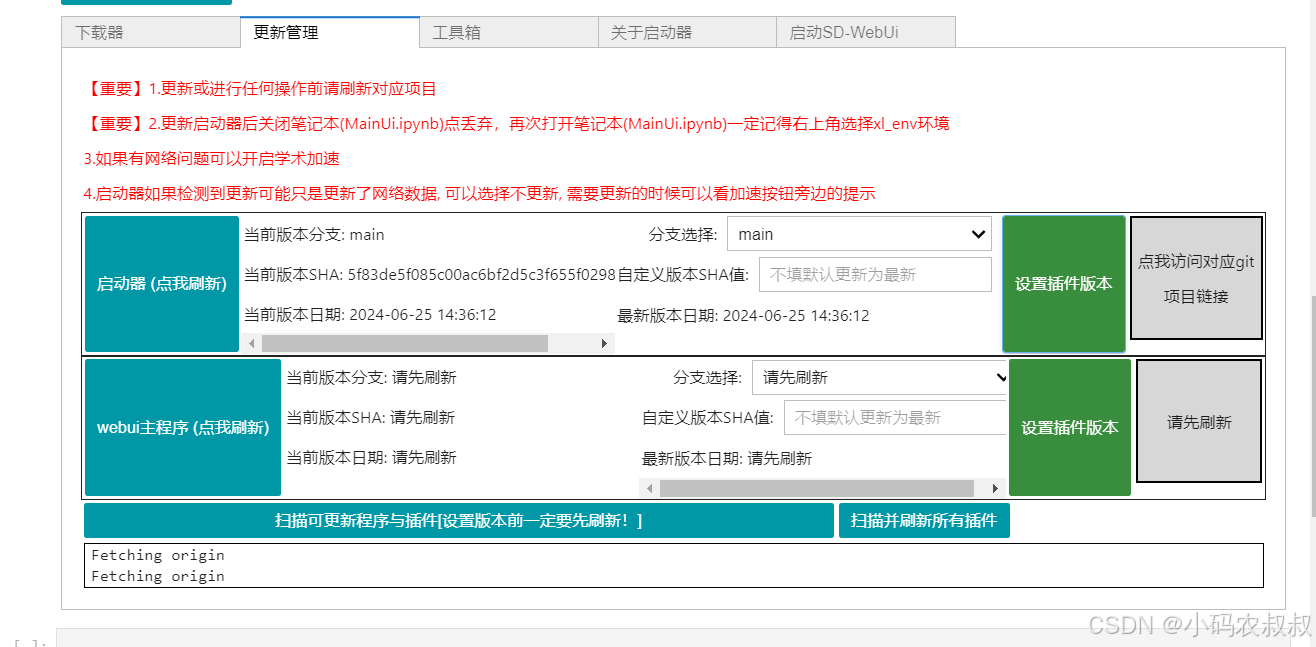
关闭工作区
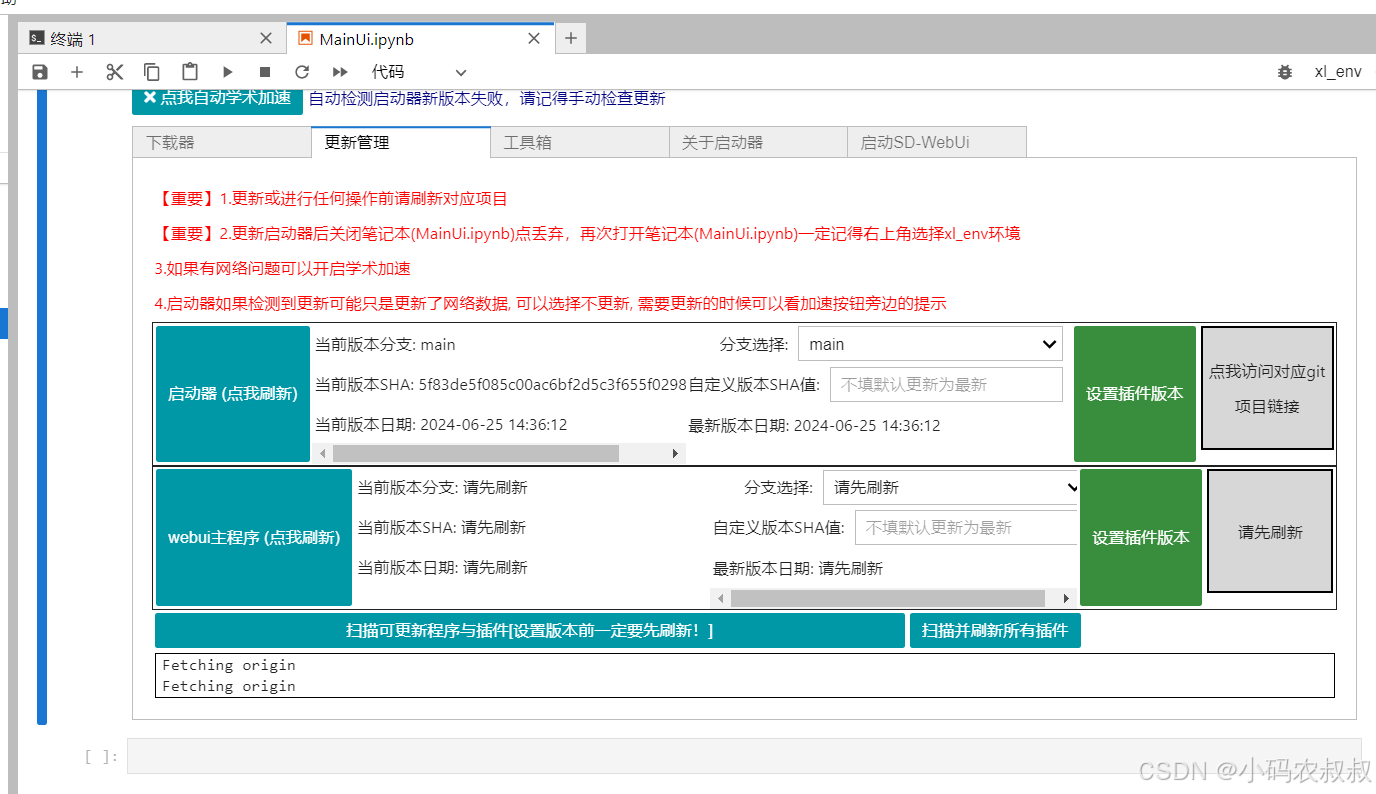
双击重新打开
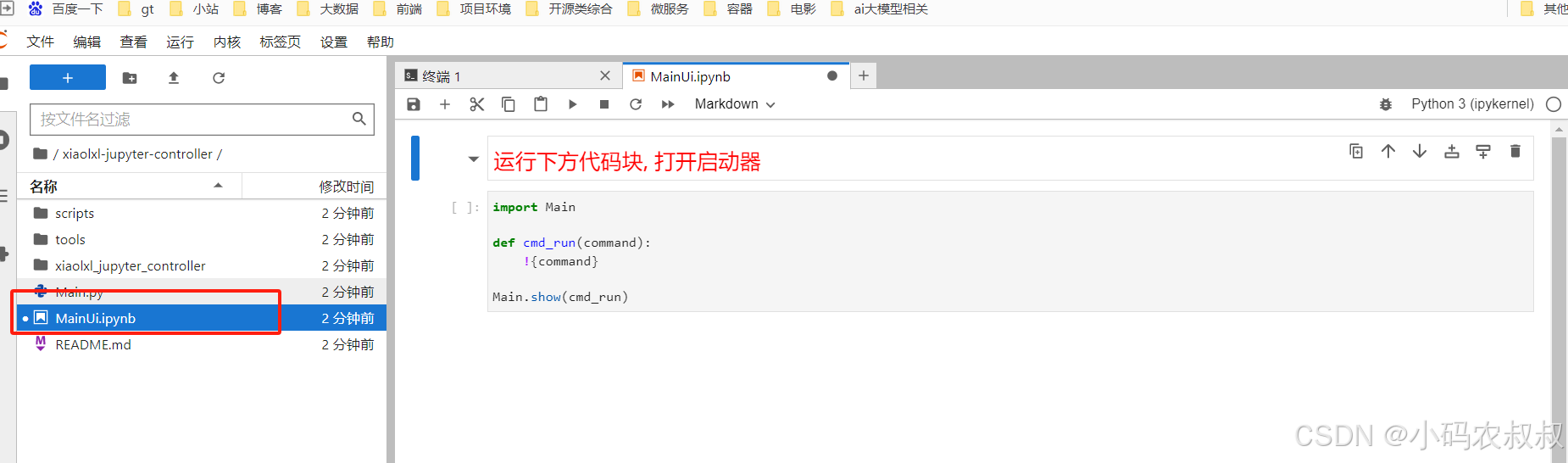
选择环境
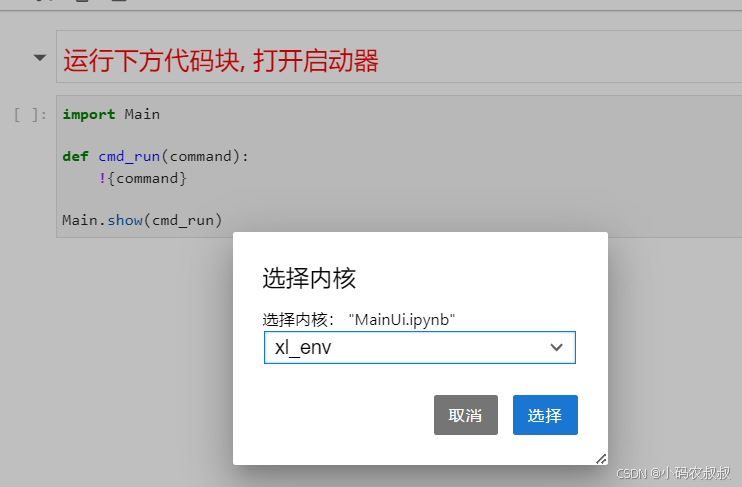
运行代码打开启动器
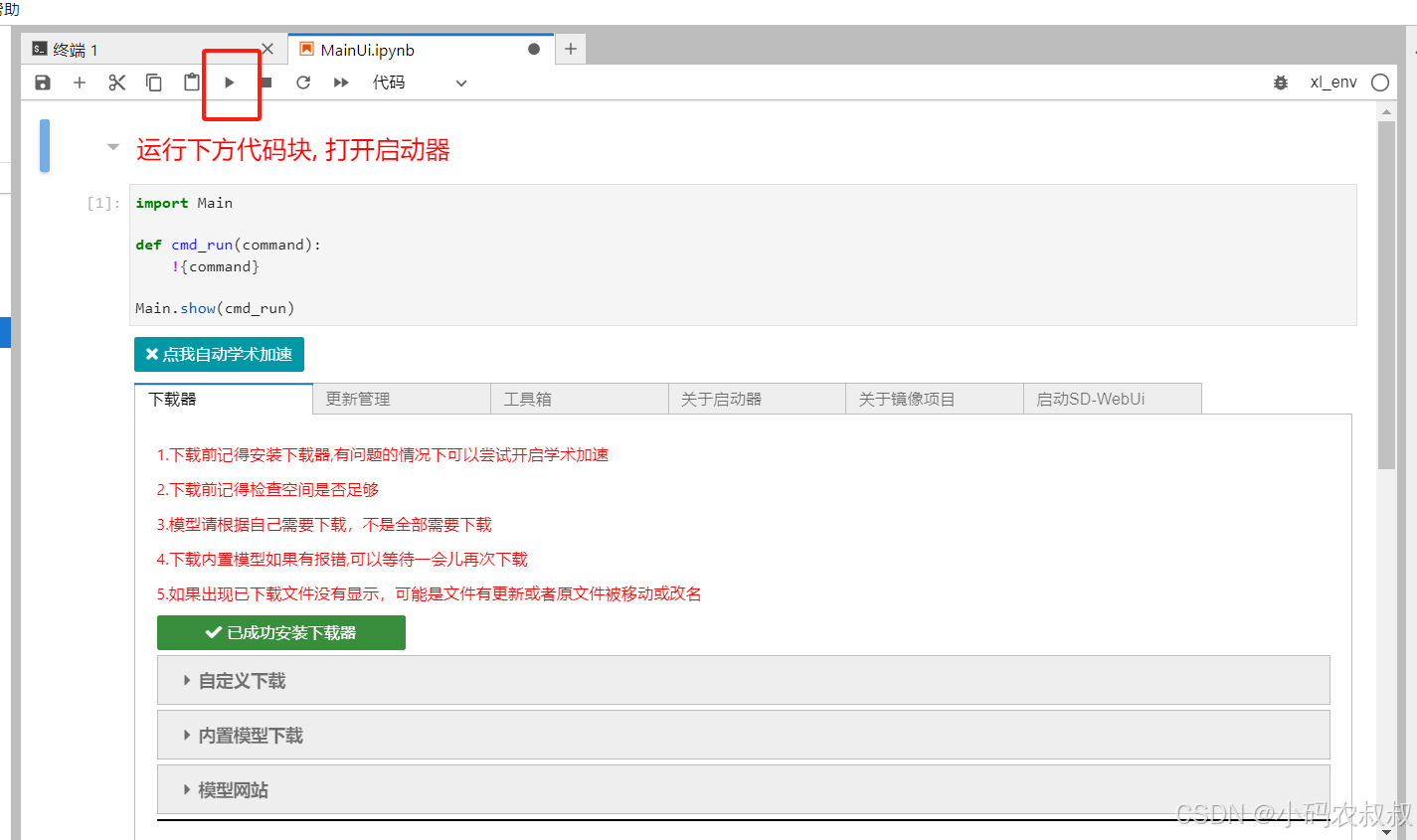
点击启动

当看到控制台中出现了那一串 : http://127.0.0.1:6006 的时候,服务启动完成
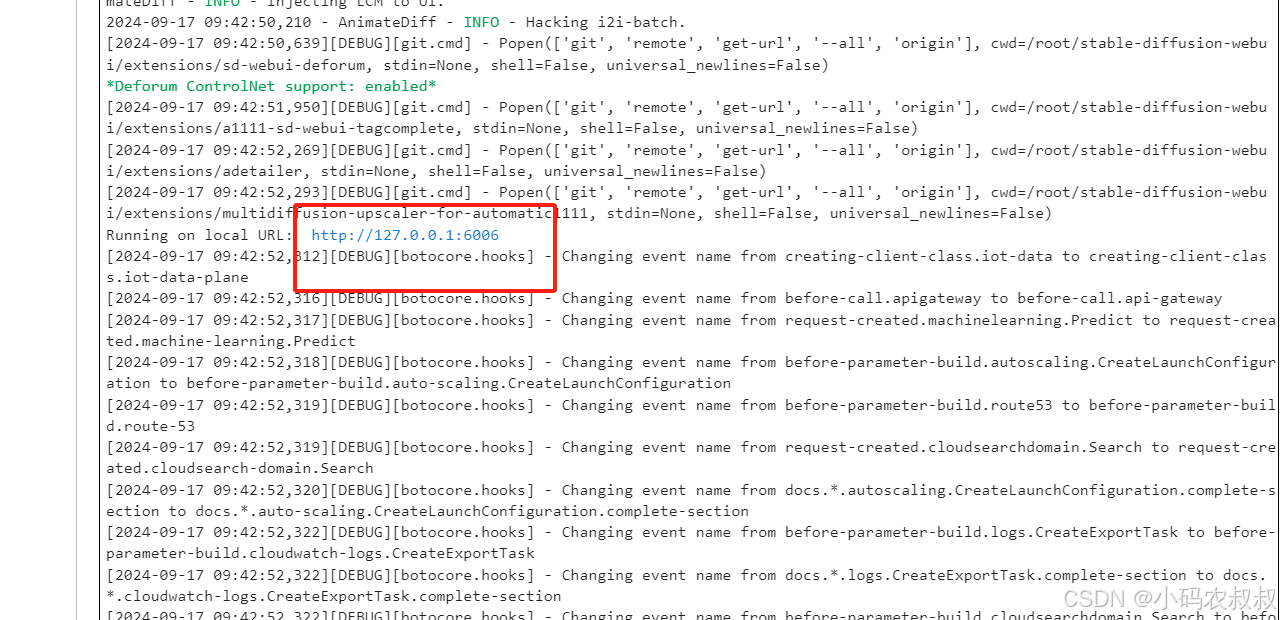
4.3.7 打开Stable Diffusion使用控制台
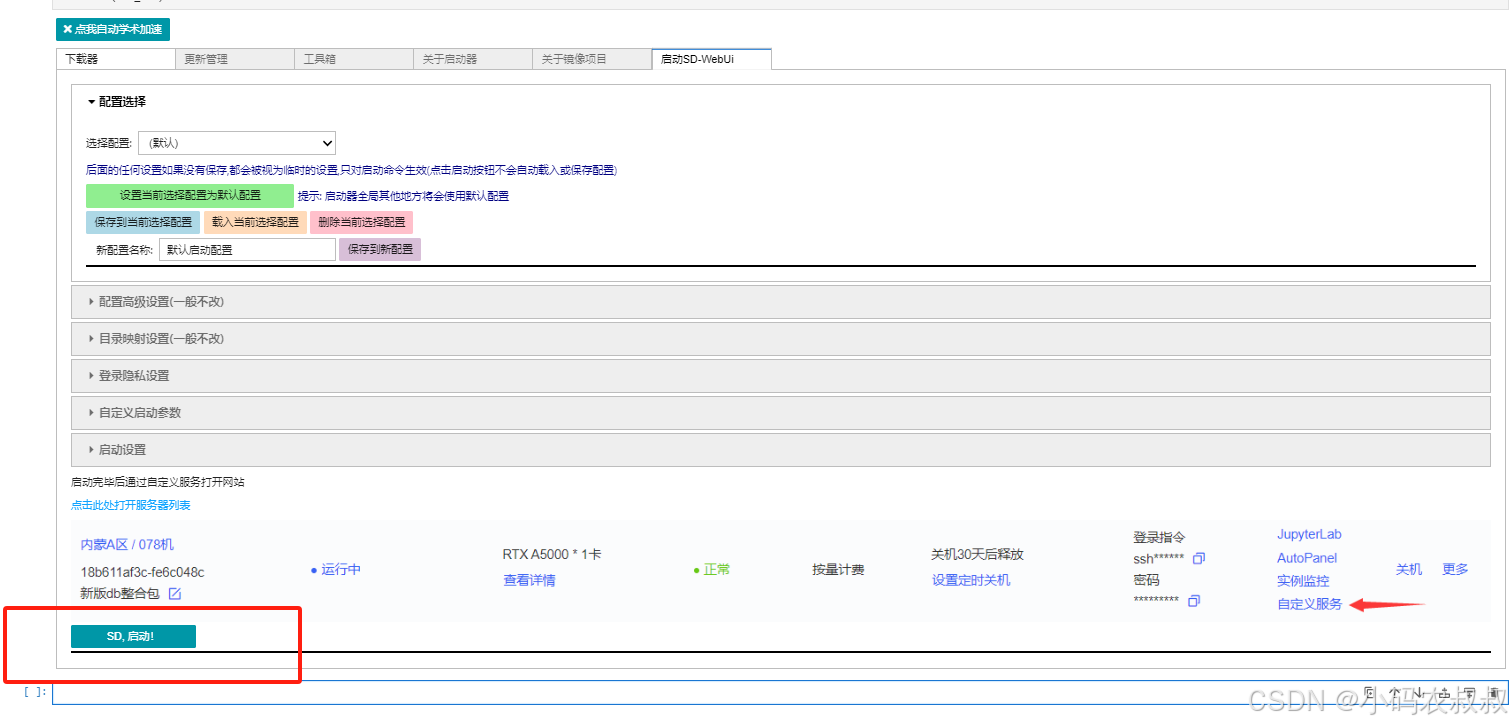
基于上面启动成功后,打开服务器列表
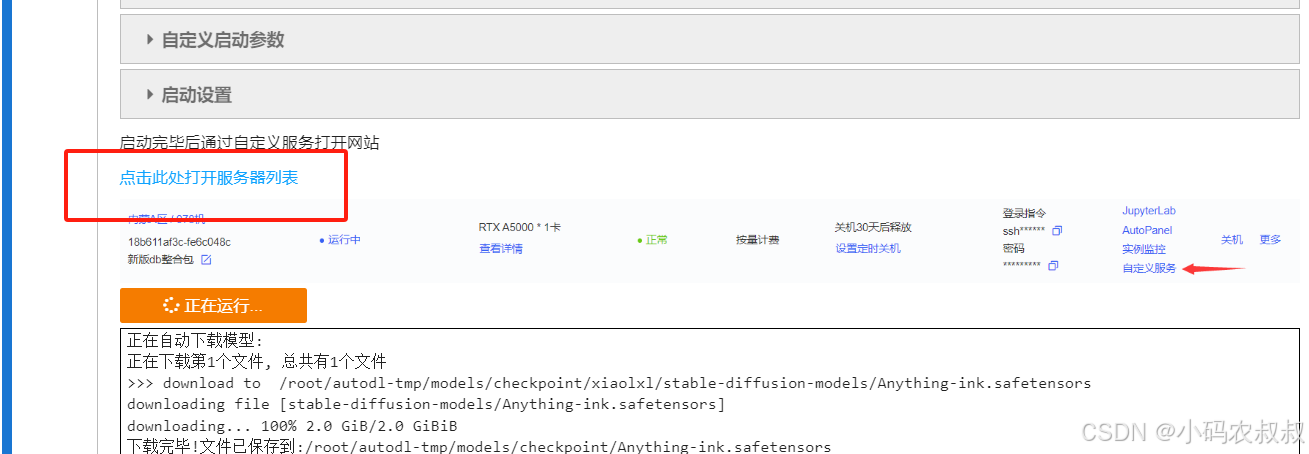
点击自定义服务
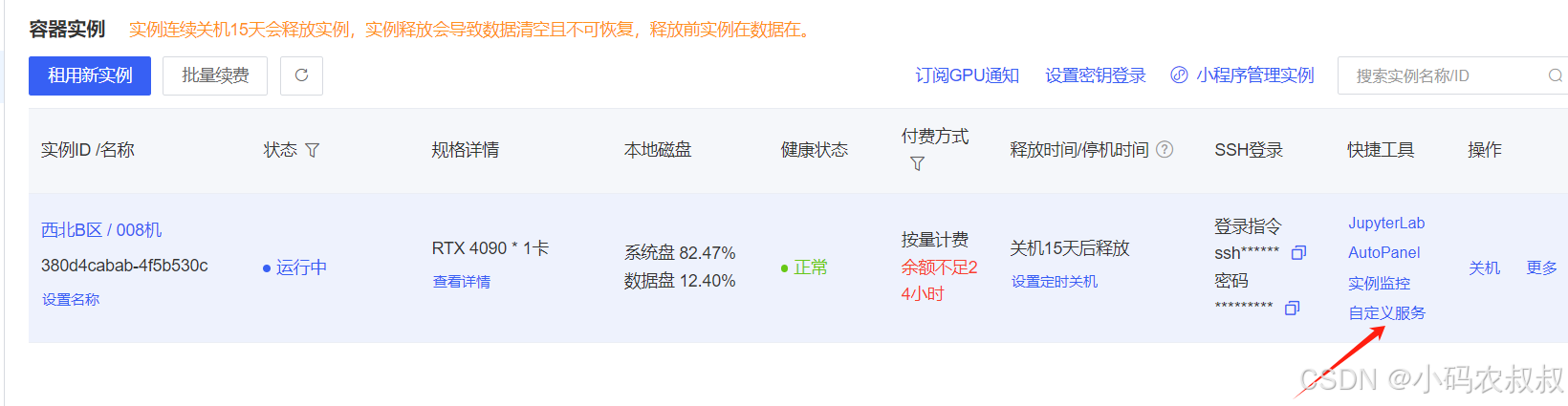
首次可能需要认证
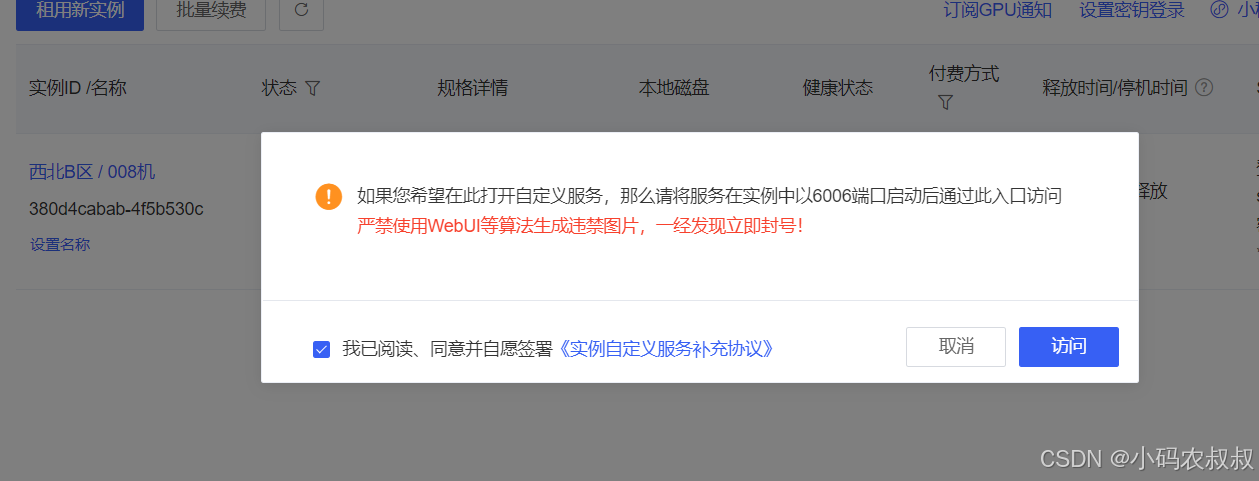
第一次载入可能有点慢,载入成功后来到下面的页面
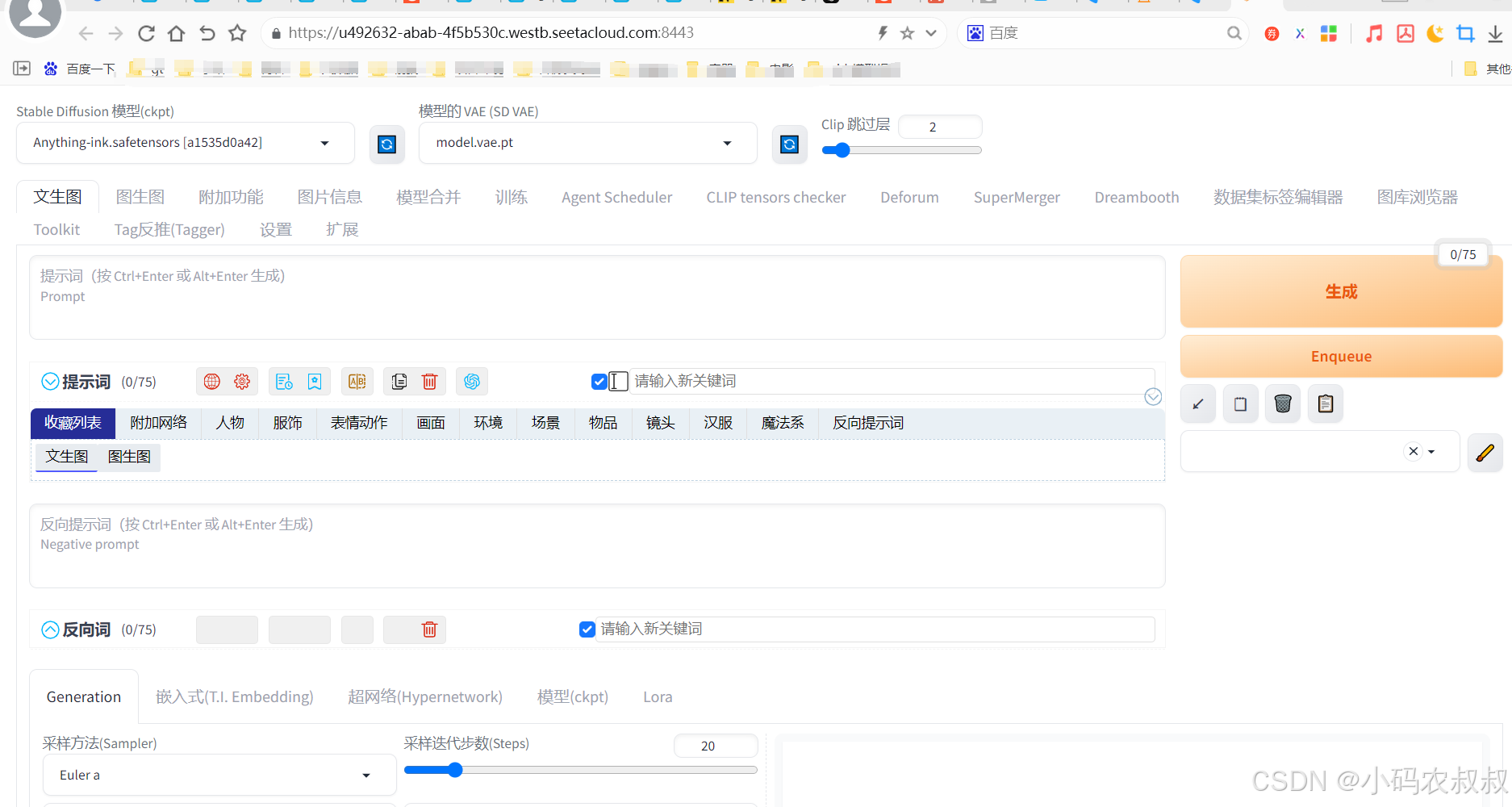
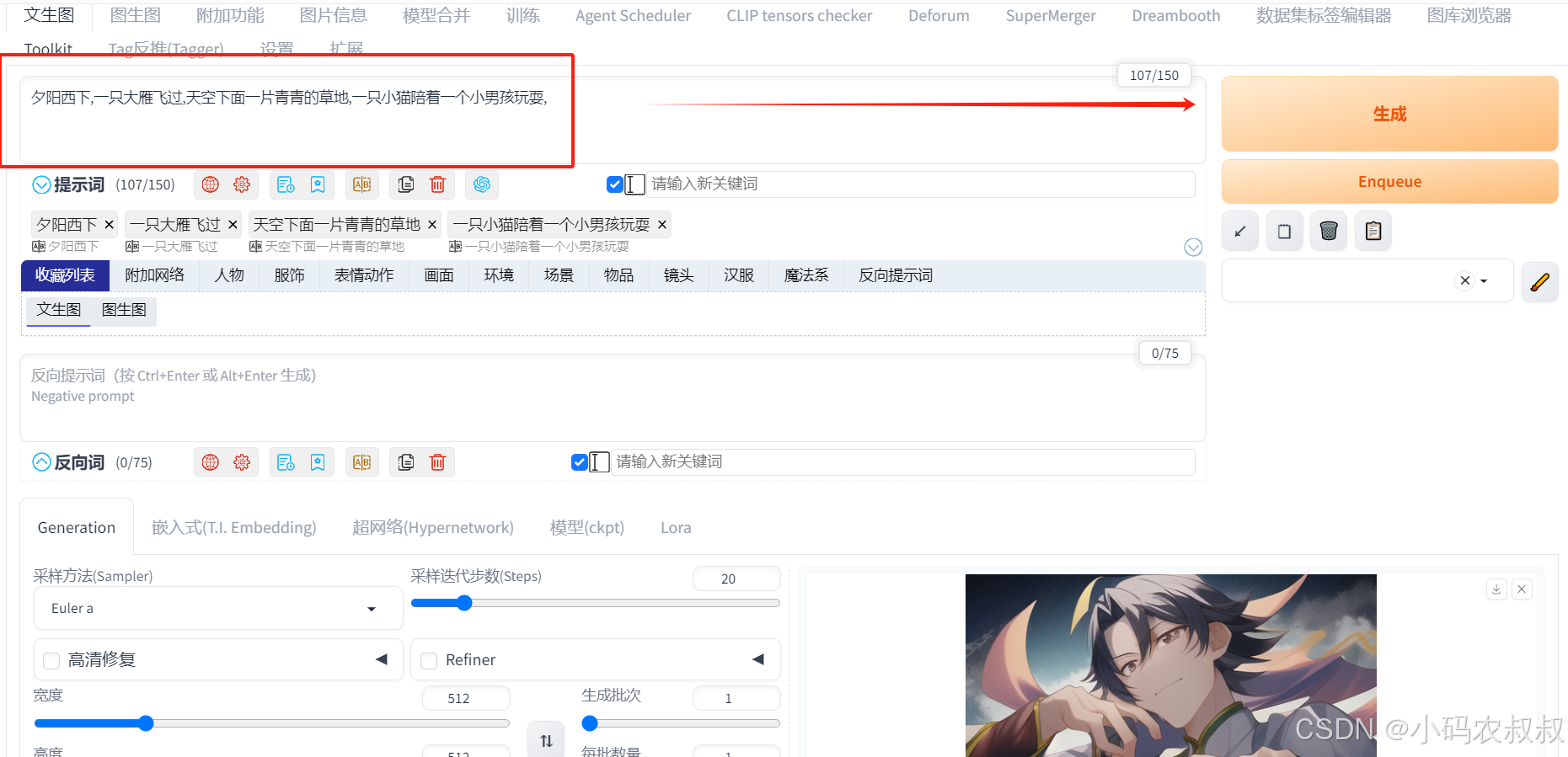
使用一下文生图功能
4.4 实用工具
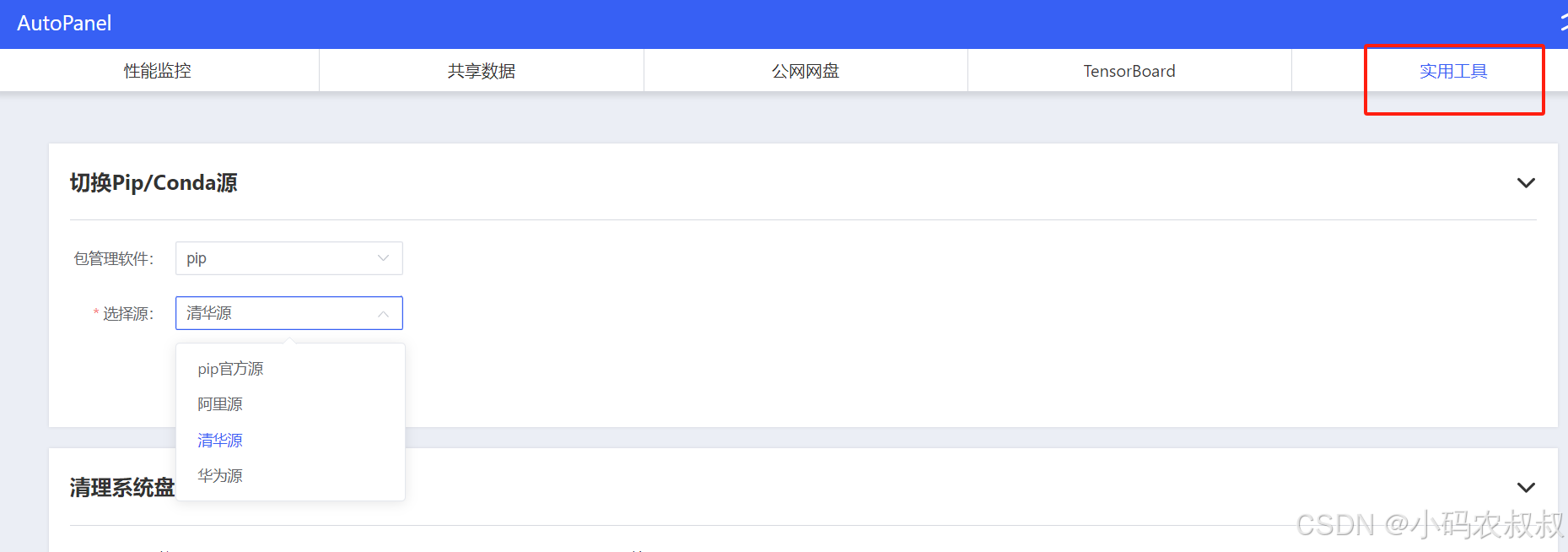
下载python依赖包的时候可能用得上
点击 AutoPanel ,在实用工具那一栏中可以选择合适的镜像源
五、写在文末
本文通过实操演示详细介绍了基于AutoDL部署Stable Diffusion的详细过程,希望对看到的同学有用,本篇到此结束,感谢观看。