1.C++11简介
C++11 的小故事:
1998年是C++标准委员会成立的第一年,本来计划以后每5年视实际需要更新一次标准,C++国际标准委员会在研究C++ 03的下一个版本的时候,一开始计划是2007年发布,所以最初这个标准叫C++ 07。但是到06年的时候,官方觉得2007年肯定完不成C++ 07,而且官方觉得2008年可能也完不成。最后干脆叫C++ 0x。x的意思是不知道到底能在07还是08还是09年完成。结果2010年的时候也没完成,最后在2011年终于完成了C++标准。所以最终定名为C++11。
在2003年C++标准委员会曾经提交了一份技术勘误表(简称TC1),使得C++03这个名字已经取代了C++98称为C++11之前的最新C++标准名称。不过由于C++03(TC1)主要是对C++98标准中的漏洞进行修复,语言的核心部分则没有改动,因此人们习惯性的把两个标准合并称为C++98/03标准。从C++0x到C++11,C++标准10年磨一剑,第二个真正意义上的标准珊珊来迟。相比于C++98/03,C++11则带来了数量可观的变化,其中包含了约140个新特性,以及对C++03标准中约600个缺陷的修正,这使得C++11更像是从C++98/03中孕育出的一种新语言。相比较而言, C++11能更好地用于系统开发和库开发、语法更加泛华和简单化、更加稳定和安全,不仅功能更强大,而且能提升程序员的开发效率,公司实际项目开发中也用得比较多
2. 统一的列表初始化
2.1 {}初始化
在C++98中,标准允许使用花括号{}对数组或者结构体元素进行统一的列表初始值设定。比如:
struct Point
{
int _x;
int _y;
};
int main()
{
int arr1[] = { 1, 2, 3, 4, 5 };
int arr2[5] = { 0 };
Point p = { 1, 2 };
return 0;
}C++11扩大了用大括号括起的列表(初始化列表)的使用范围,使其可用于所有的内置类型和用户自定义的类型,使用初始化列表时,可添加等号(=),也可不添加。
int main()
{
int a1 = 1;
int a2{ 2 };
int arr1[]{ 1, 2, 3, 4, 5 };
int arr2[5]{ 0 };
Point p{ 1, 2 };
// C++11中列表初始化也可以适用于new表达式中
int* pa = new int[4]{ 0 };
return 0;
}创建对象时也可以使用列表初始化方式调用构造函数初始化
class Date
{
public:
Date(int year, int month, int day)
:_year(year)
, _month(month)
, _day(day)
{
cout << "Date(int year, int month, int day)" << endl;
}
private:
int _year;
int _month;
int _day;
};
int main()
{
Date d1(2022, 1, 1); //老版本
// C++11支持的列表初始化,这里会调用构造函数初始化
Date d2{ 2022, 1, 2 };
Date d3 = { 2022, 1, 3 };
return 0;
}2.2 std::initializer_list
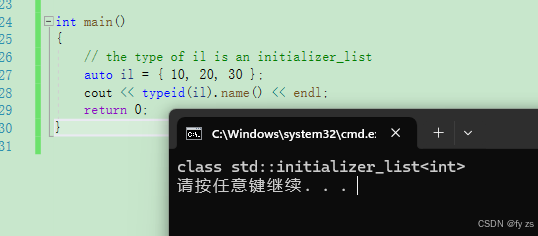
std::initializer_list是什么类型:
int main()
{
// the type of il is an initializer_list
auto il = { 10, 20, 30 };
cout << typeid(il).name() << endl;
return 0;
}
std::initializer_list使用场景:
std::initializer_list一般是作为构造函数的参数,C++11对STL中的不少容器就增加std::initializer_list作为参数的构造函数,这样初始化容器对象就更方便了。也可以作为operator=的参数,这样就可以用大括号赋值。
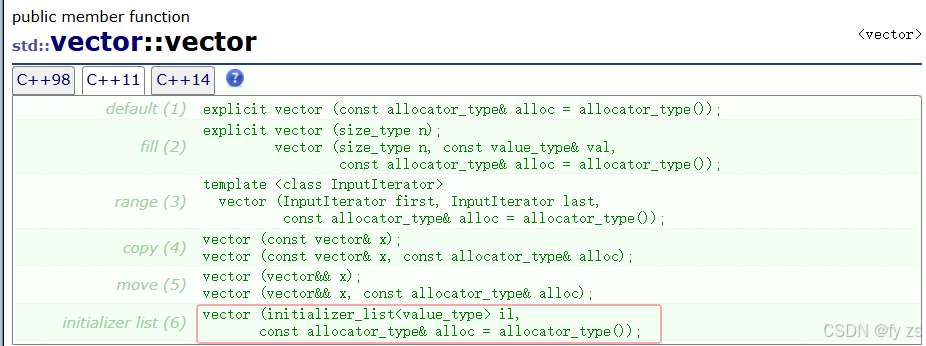

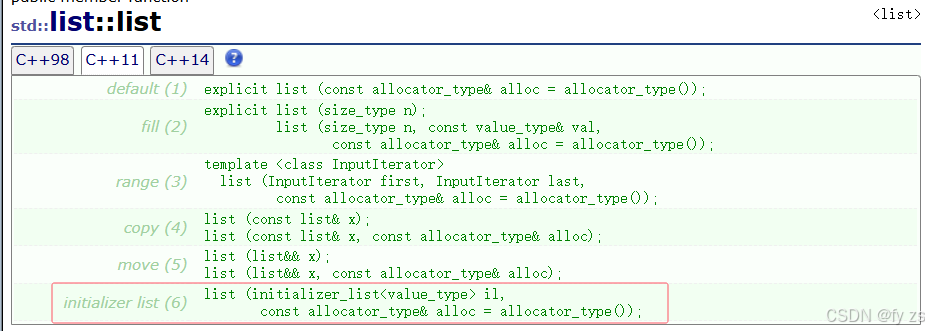
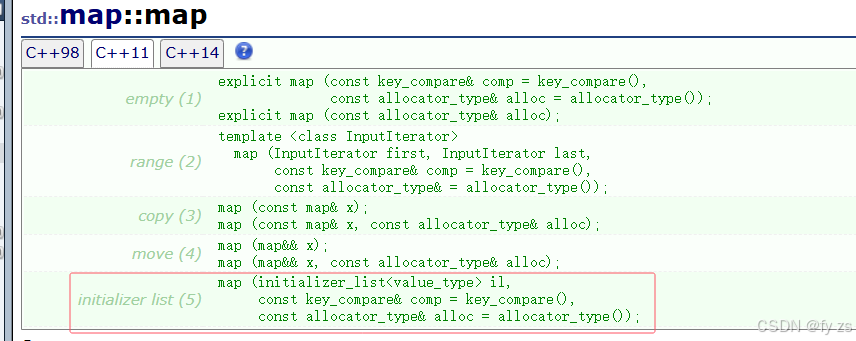
让模拟实现的vector也支持{}初始化和赋值
namespace bit
{
template<class T>
class vector {
public:
typedef T* iterator;
vector(initializer_list<T> l)
{
_start = new T[l.size()];
_finish = _start + l.size();
_endofstorage = _start + l.size();
iterator vit = _start;
typename initializer_list<T>::iterator lit = l.begin();
while (lit != l.end())
{
*vit++ = *lit++;
}
//for (auto e : l)
// *vit++ = e;
}
vector<T>& operator=(initializer_list<T> l) {
vector<T> tmp(l);
std::swap(_start, tmp._start);
std::swap(_finish, tmp._finish);
std::swap(_endofstorage, tmp._endofstorage);
return *this;
}
private:
iterator _start;
iterator _finish;
iterator _endofstorage;
};
}3. 变量类型推导
3.1 auto
在C++98中auto是一个存储类型的说明符,表明变量是局部自动存储类型,但是局部域中定义局部的变量默认就是自动存储类型,所以auto就没什么价值了。C++11中废弃auto原来的用法,将其用于实现自动类型推断。这样要求必须进行显示初始化,让编译器将定义对象的类型设置为初始化值的类型。
int main()
{
int i = 10;
auto p = &i;
auto pf = strcpy;
cout << typeid(p).name() << endl;
cout << typeid(pf).name() << endl;
map<string, string> dict = { {"sort", "排序"}, {"insert", "插入"} };
//map<string, string>::iterator it = dict.begin();
auto it = dict.begin();
return 0;
}
3.2 decltype
关键字decltype将变量的类型声明为表达式指定的类型。
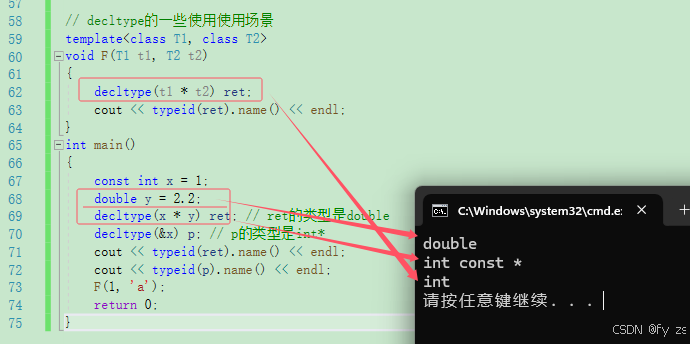
// decltype的一些使用使用场景
template<class T1, class T2>
void F(T1 t1, T2 t2)
{
decltype(t1 * t2) ret;
cout << typeid(ret).name() << endl;
}
int main()
{
const int x = 1;
double y = 2.2;
decltype(x * y) ret; // ret的类型是double
decltype(&x) p; // p的类型是int*
cout << typeid(ret).name() << endl;
cout << typeid(p).name() << endl;
F(1, 'a');
return 0;
}
3.3 nullptr
由于C++中NULL被定义成字面量0,这样就可能回带来一些问题,因为0既能指针常量,又能表示整形常量。所以出于清晰和安全的角度考虑,C++11中新增了nullptr,用于表示空指针。
在c语言中 NULL的问题不明显,但是在C++中因为支持了重载所以有非常大的问题如下:
它会匹配到参数 int
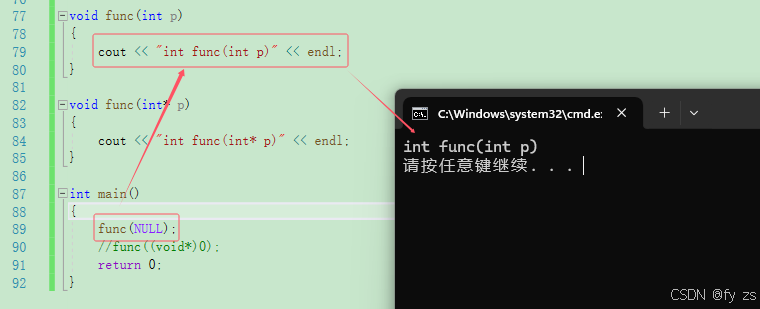
而用c语言的方式会报错,如下:
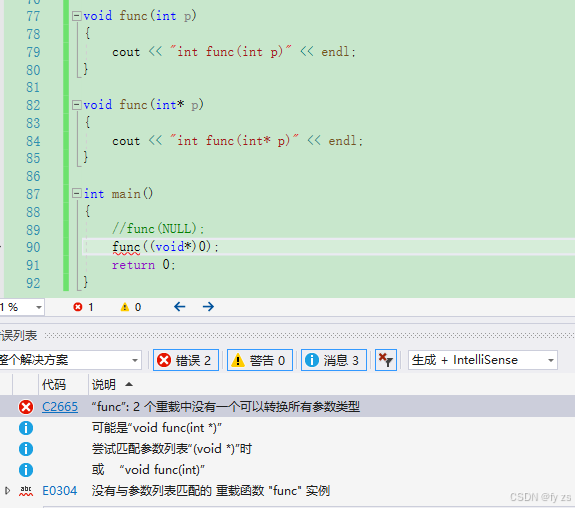
c语言是没有这个问题的因为void* 指针会隐式类型转换为其它类型的指针,如下:
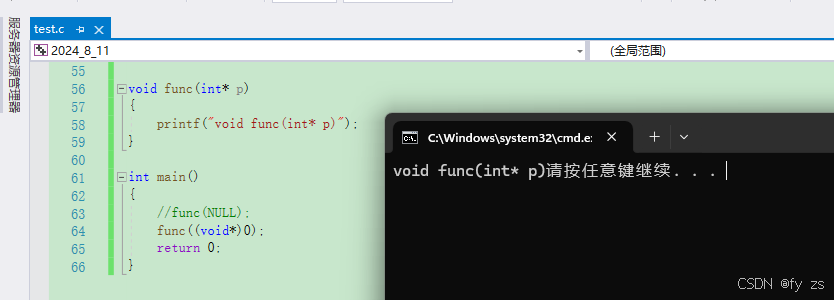
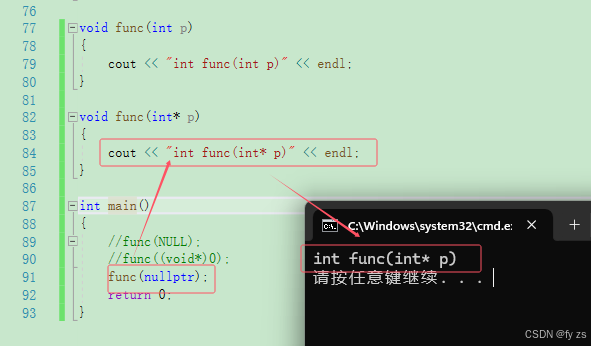
程序本意是想通过f(NULL)调用指针版本的f(int*)函数,但是由于NULL被定义成0,因此与程序的
初衷相悖。在C++98中,字面常量0既可以是一个整形数字,也可以是无类型的指针(void*)常量,但是编译器默认情况下将其看成是一个整形常量,如果要将其按照指针方式来使用,必须对其进行强转(void*)0。
需要注意的是以下几点:
1. 在使用nullptr表示指针空值时,不需要包含头文件,因为nullptr是C++11作为新关键字引入的。
2. 在C++11中,sizeof(nullptr) 与 sizeof((void*)0)所占的字节数相同。
3. 为了提高代码的健壮性,在后续表示指针空值时建议最好使用nullptr。
4. 范围for循环
在C++98中如果要遍历一个数组,可以按照以下方式进行:
void Test()
{
int array[] = { 1, 2, 3, 4, 5 };
for (int i = 0; i < sizeof(array) / sizeof(array[0]); ++i)
array[i] *= 2;
for (int* p = array; p < array + sizeof(array)/ sizeof(array[0]); ++p)
cout << *p << endl;
}对于一个有范围的集合而言,由程序员来说明循环的范围是多余的,有时候还会容易犯错误。因
此C++11中引入了基于范围的for循环。for循环后的括号由冒号“ :”分为两部分:第一部分是范
围内用于迭代的变量,第二部分则表示被迭代的范围.
void TestFor()
{
int array[] = { 1, 2, 3, 4, 5 };
for(auto& e : array)
e *= 2;
for(auto e : array)
cout << e << " ";
return 0;
}需要注意的是:
与普通循环类似,可以用continue来结束本次循环,也可以用break来跳出整个循环。
for循环迭代的范围必须是确定的对于数组而言,就是数组中第一个元素和最后一个元素的范围;对于类而言,应该提供begin和end的方法,begin和end就是for循环迭代的范围。
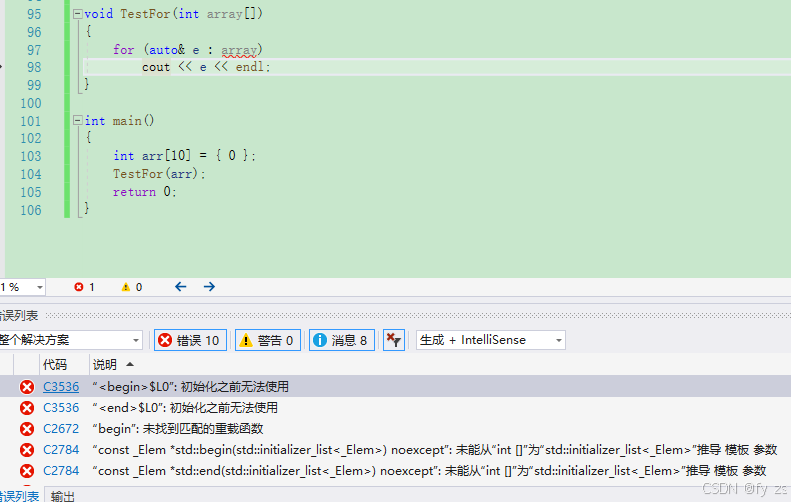
注意:以下代码就有问题,因为for的范围不确定。
void TestFor(int array[])
{
for(auto& e : array)
cout<< e <<endl;
}
6 STL中一些变化
新容器
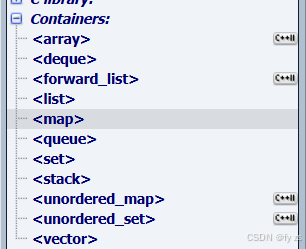
用橘色圈起来是C++11中的一些几个新容器,但是实际最有用的是unordered_map和unordered_set。
新接口
如果我们再细细去看会发现基本每个容器中都增加了一些C++11的方法,但是其实很多都是用得比较少的。比如提供了cbegin和cend方法返回const迭代器等等,但是实际意义不大,因为begin和end也是可以返回const迭代器的,这些都是属于锦上添花的操作。实际上C++11更新后,容器中增加的新方法最后用的插入接口函数的右值引用版本:
7 右值引用和移动语义
7.1 左值引用和右值引用
传统的C++语法中就有引用的语法,而C++11中新增了的右值引用语法特性,所以从现在开始我们之前学习的引用就叫做左值引用。无论左值引用还是右值引用,都是给对象取别名。
什么是左值?什么是左值引用?
左值是一个表示数据的表达式(如变量名或解引用的指针),我们可以获取它的地址+可以对它赋值,左值可以出现赋值符号的左边,右值不能出现在赋值符号左边。定义时const修饰符后的左值,不能给他赋值,但是可以取它的地址。左值引用就是给左值的引用,给左值取别名。
int main()
{
// 以下的p、b、c、*p都是左值
int* p = new int(0);
int b = 1;
const int c = b;//既可以在它的左边也可以在他的右边
// 以下几个是对上面左值的左值引用
int*& rp = p;
int& rb = b;
const int& rc = c;
int& pvalue = *p;
return 0;
}可以取地址的就是左值。
什么是右值?什么是右值引用?
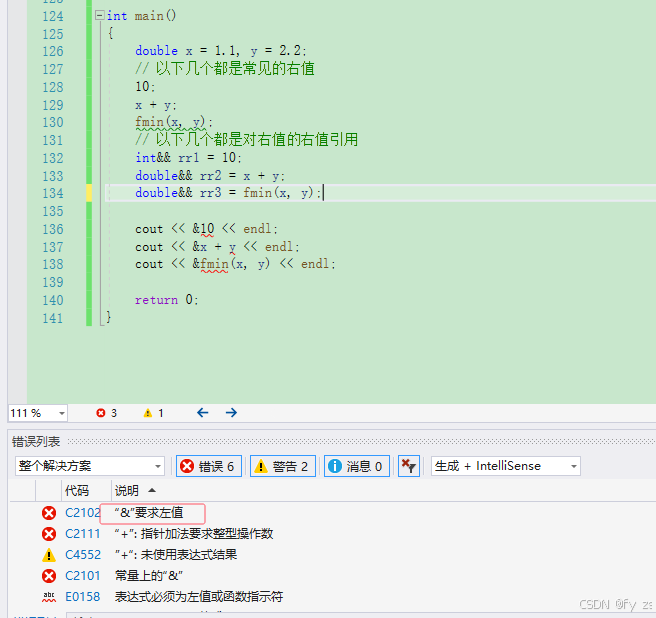
右值也是一个表示数据的表达式,如:字面常量、表达式返回值,函数返回值(这个不能是左值引用返回)等等,右值可以出现在赋值符号的右边,但是不能出现出现在赋值符号的左边,右值不能取地址。右值引用就是对右值的引用,给右值取别名。
int main()
{
double x = 1.1, y = 2.2;
// 以下几个都是常见的右值
10;
x + y;
fmin(x, y);
// 以下几个都是对右值的右值引用
int&& rr1 = 10;
double&& rr2 = x + y;
double&& rr3 = fmin(x, y);
return 0;
}左值:
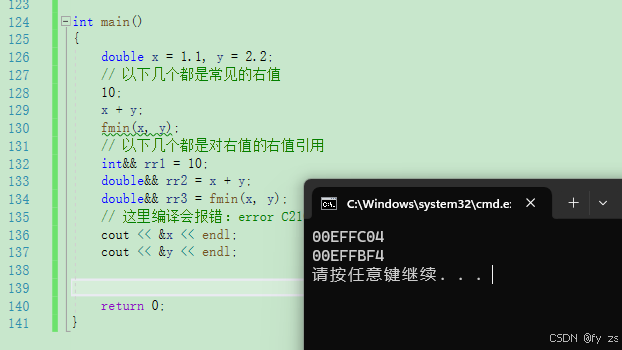
右值:
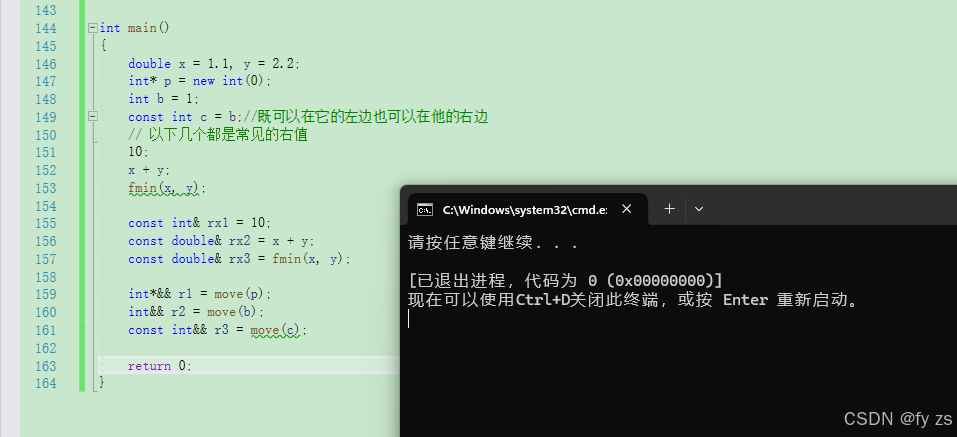
那么左值引用可不可以右值取别名?右值引用可不可以给左值取别名呢?
左值引用引用给右值取别名:不能直接引用,但是const左值引用可以。
右值引用引用给左值取别名:不能直接引用,但是move(左值)以后右值引用可以引用。
如下:
int main()
{
double x = 1.1, y = 2.2;
int* p = new int(0);
int b = 1;
const int c = b;//既可以在它的左边也可以在他的右边
// 以下几个都是常见的右值
10;
x + y;
fmin(x, y);
const int& rx1 = 10;
const double& rx2 = x + y;
const double& rx3 = fmin(x, y);
int*&& r1 = move(p);
int*&& rr1 = (int*&&)p;
int&& r2 = move(b);
int&& rr2 = (int&&)b;
const int&& r3 = move(c);
const int&& rr3 = (const int&&)c;
return 0;
}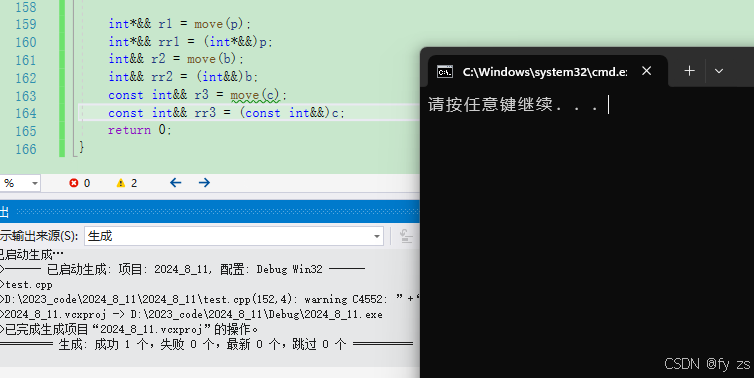
int main()
{
int a = 0;
int& r1 = a;
int&& r2 = a + 10;
return 0;
}从下面反汇编代码可以看到在底层是没有引用这个概念的 。

7.2 右值引用使用场景和意义
前面我们可以看到左值引用既可以引用左值和又可以引用右值,那为什么C++11还要提出右值引用呢?是不是化蛇添足呢?下面我们来看看左值引用的短板,右值引用是如何补齐这个短板的!
引用的意义:减少拷贝
左值引用解决的场景:引用传参/引用传返回值
左值引用没有彻底解决的场景:传返回值
如下:

出了这个函数str则会被销毁,所以这里不能用左值引用解决
那么右值引用能不能解决这个问题呢?
移动构造:
string(string&& s)
{
cout << "string(string&& s) -- 移动构造" << endl;
swap(s);
}如下:倘若没有移动构造,只有拷贝构造
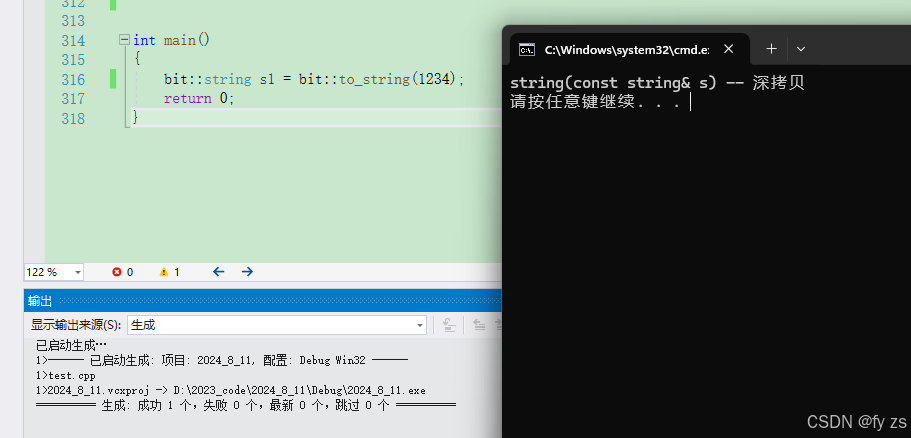
如下:有拷贝构造,也有移动构造。 (由于str 本来也要销毁所以把它move为右值没有问题,还节省了时间)

运行结果如下:
只有深拷贝的类,移动构造才有意义。
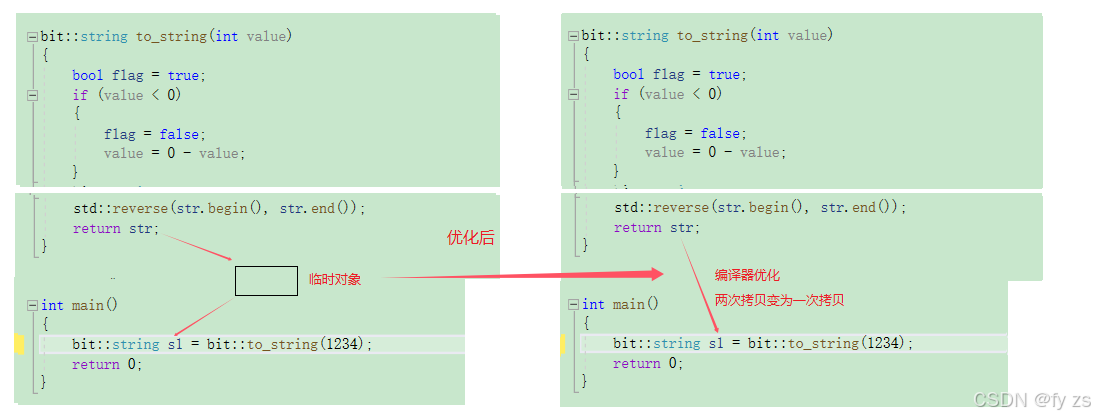
当然有的很先进的编译器会更为激进的优化如下:(他会直接用s1 替代 str)
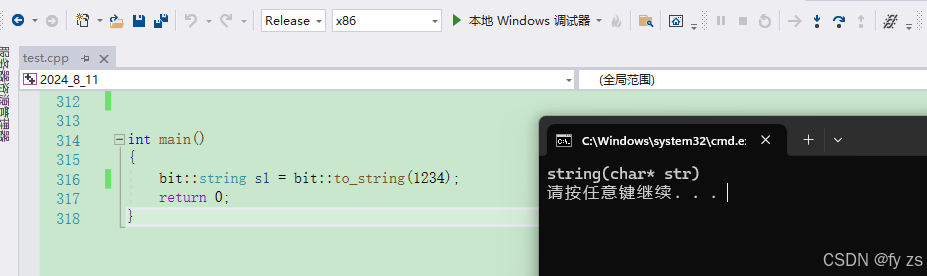
下面这种写法则会将他打回原形。
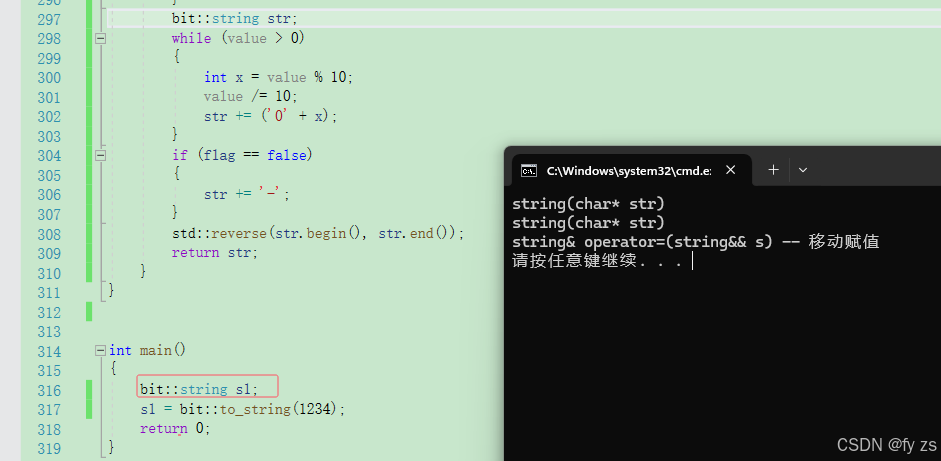
所以类似下面这样传值返回的场景随便用,因为浅拷贝的类没啥代价,深拷贝的类他会走移动构造和移动赋值效率大大提升。


注意: move是这个函数的调用后的返回值为右值 。
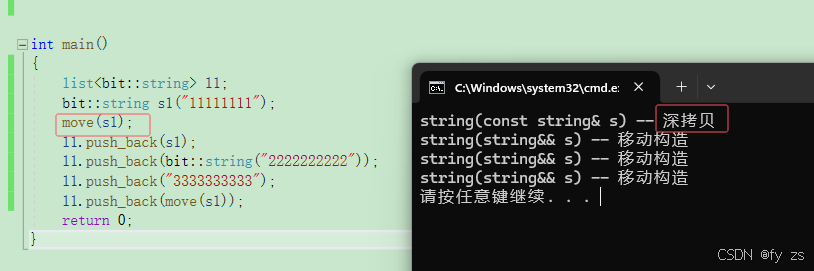
接下来我换成自己写的链表来测试一下:
list.h
namespace bit
{
void push_back(const T& x)
{
insert(end(), x);
}
void push_back(T&& x)
{
insert(end(), x);
}
iterator insert(iterator pos, const T& x)
{
Node* cur = pos._node;
Node* newnode = new Node(x);
Node* prev = cur->_prev;
// prev newnode cur
prev->_next = newnode;
newnode->_prev = prev;
newnode->_next = cur;
cur->_prev = newnode;
return iterator(newnode);
}
iterator insert(iterator pos, T&& x)
{
Node* cur = pos._node;
Node* newnode = new Node(move(x));
Node* prev = cur->_prev;
// prev newnode cur
prev->_next = newnode;
newnode->_prev = prev;
newnode->_next = cur;
cur->_prev = newnode;
return iterator(newnode);
}
}
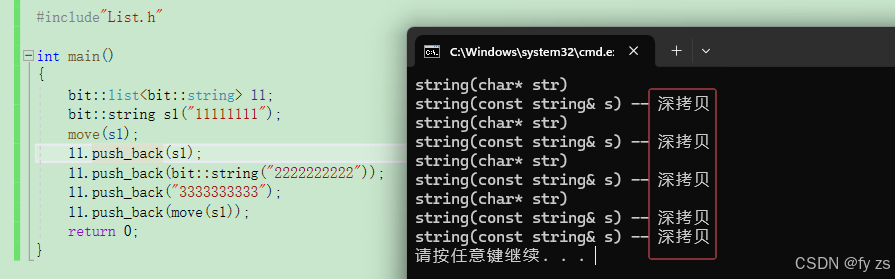
#include"List.h"
int main()
{
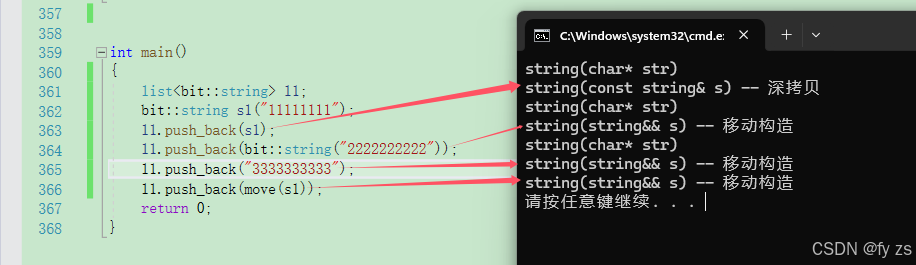
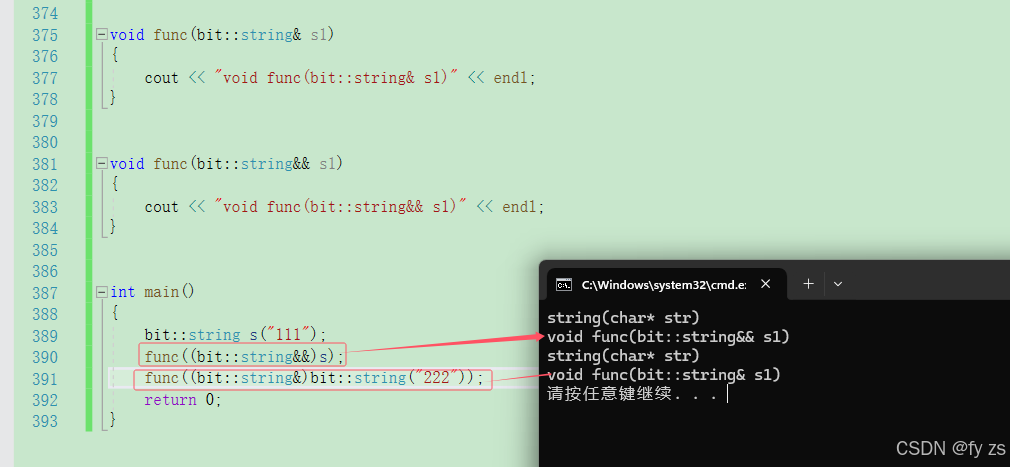
bit::list<bit::string> l1;
bit::string s1("11111111");
move(s1);
l1.push_back(s1);
l1.push_back(bit::string("2222222222"));
l1.push_back("3333333333");
l1.push_back(move(s1));
return 0;
}
右值引用本身的属性是右值还是左值呢? 答案是左值。

为什么呢?因为只有右值引用本身的属性是左值,才能转移自身的资源。
所以我们可以进行以下操作。
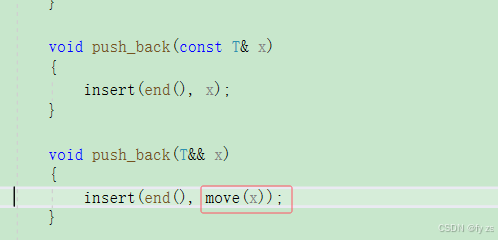
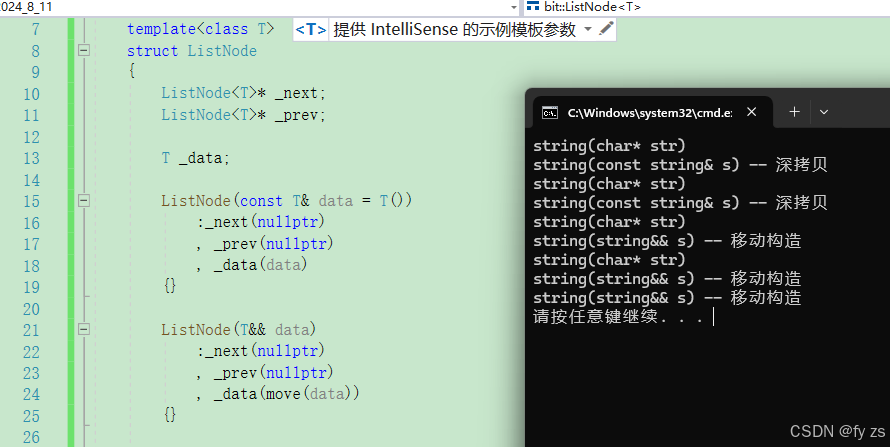
但是到这里还是不行的,因为node 的构造还只有左值版本
template<class T>
struct ListNode
{
ListNode<T>* _next;
ListNode<T>* _prev;
T _data;
ListNode(const T& data = T())
:_next(nullptr)
, _prev(nullptr)
, _data(data)
{}
};再写一个右值版本就可以了。
如下:
template<class T>
struct ListNode
{
ListNode<T>* _next;
ListNode<T>* _prev;
T _data;
ListNode(const T& data = T())
:_next(nullptr)
, _prev(nullptr)
, _data(data)
{}
ListNode(T&& data)
:_next(nullptr)
, _prev(nullptr)
, _data(move(data))
{}
};
左右值是可以互相转换的
感谢大家的观看!