✍个人博客:https://blog.csdn.net/Newin2020?type=blog
📣专栏地址:http://t.csdnimg.cn/fYaBd
📚专栏简介:在这个专栏中,我将会分享 C++ 面试中常见的面试题给大家~
❤️如果有收获的话,欢迎点赞👍收藏📁,您的支持就是我创作的最大动力💪
📝推荐参考地址:https://www.xiaolincoding.com/(这个大佬的专栏非常有用!)
178. 模拟 Proactor 模式
使用同步 I/O 方式模拟出 Proactor 模式。原理是:主线程执行数据读写操作,读写完成之后,主线程向工作线程通知这一 ”完成事件“。那么从工作线程的角度来看,它们就直接获得了数据读写的结果,接下来要做的只是对读写的结果进行逻辑处理。
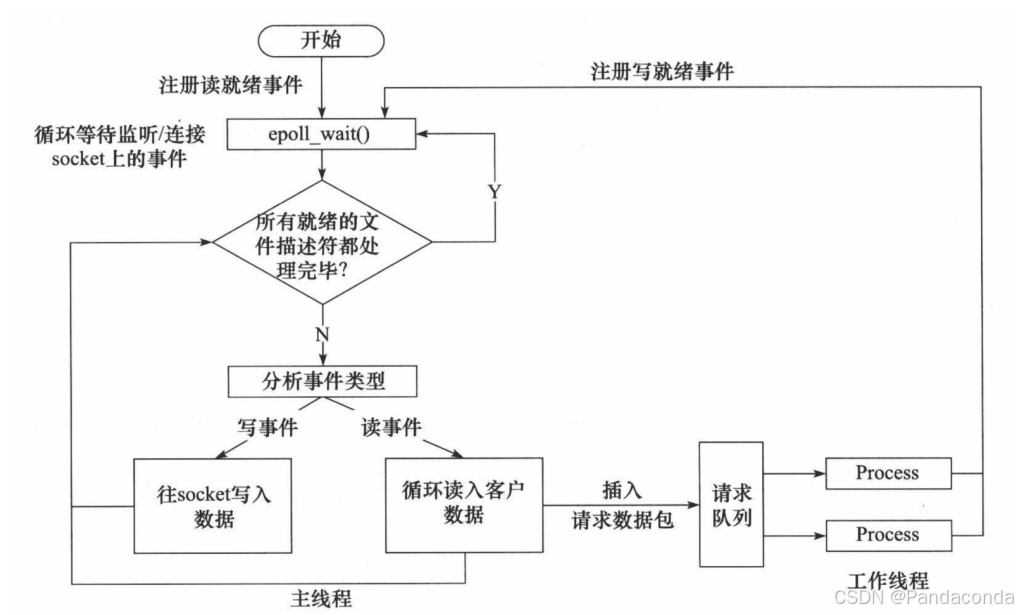
使用同步 I/O 模型(以 epoll_wait 为例)模拟出的 Proactor 模式的工作流程如下:
- 主线程往 epoll 内核事件表中注册 socket 上的读就绪事件。
- 主线程调用 epoll_wait 等待 socket 上有数据可读。
- 当 socket 上有数据可读时,epoll_wait 通知主线程。主线程从 socket 循环读取数据,直到没有更多数据可读,然后将读取到的数据封装成一个请求对象并插入请求队列。
- 睡眠在请求队列上的某个工作线程被唤醒,它获得请求对象并处理客户请求,然后往 epoll 内核事件表中注册 socket 上的写就绪事件。
- 主线程调用 epoll_wait 等待 socket 可写。
- 当 socket 可写时,epoll_wait 通知主线程。主线程往 socket 上写入服务器处理客户请求的结果。
同步 I/O 模拟 Proactor 模式的工作流程:
179. 一致性哈希
不同的负载均衡算法适用的业务场景也不同的。
轮询这类的策略只能适用与每个节点的数据都是相同的场景,访问任意节点都能请求到数据。但是不适用分布式系统,因为分布式系统意味着数据水平切分到了不同的节点上,访问数据的时候,一定要寻址存储该数据的节点。
哈希算法虽然能建立数据和节点的映射关系,但是每次在节点数量发生变化的时候,最坏情况下所有数据都需要迁移,这样太麻烦了,所以不适用节点数量变化的场景。
为了减少迁移的数据量,就出现了一致性哈希算法。
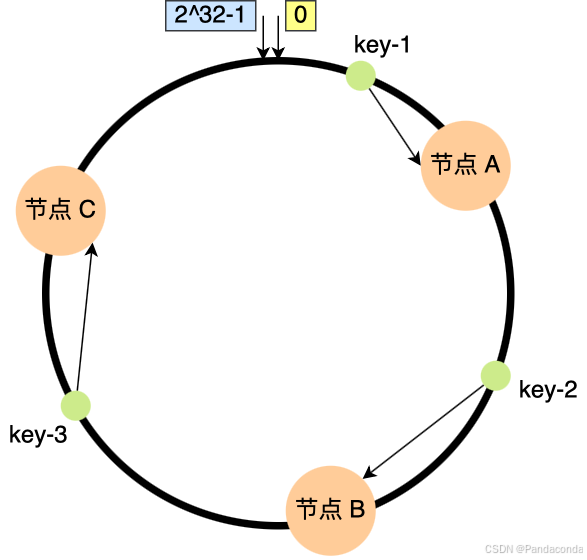
一致性哈希是指将「存储节点」和「数据」都映射到一个首尾相连的哈希环上,如果增加或者移除一个节点,仅影响该节点在哈希环上顺时针相邻的后继节点,其它数据也不会受到影响。
180. 虚拟节点
但是上面的一致性哈希算法不能够均匀的分布节点,会出现大量请求都集中在一个节点的情况,在这种情况下进行容灾与扩容时,容易出现雪崩的连锁反应。
为了解决一致性哈希算法不能够均匀的分布节点的问题,就需要引入虚拟节点,对一个真实节点做多个副本。不再将真实节点映射到哈希环上,而是将虚拟节点映射到哈希环上,并将虚拟节点映射到实际节点,所以这里有「两层」映射关系。
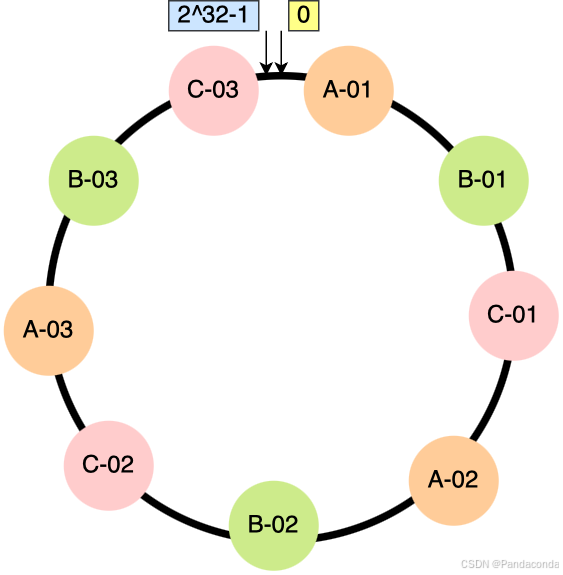
引入虚拟节点后,可以会提高节点的均衡度,还会提高系统的稳定性。所以,带虚拟节点的一致性哈希方法不仅适合硬件配置不同的节点的场景,而且适合节点规模会发生变化的场景。