引言
作为2017年CVPR最佳论文,足以体现其重要性和创新性,清华大学黄高博士第一作者发表的。现其重要性,博主人读完这文章后,自然感叹我们国内也是人才辈出,清华大学确实是国内人工智能的顶尖。废话不多说开始分享算法。
DenseNet论文算法解释
网络上有很多关于这篇论文的解读,博主读了几个,解释的明白清楚的还是下面链接中解释的明白,既有解释又有代码还有论文链接,有想法的可以看看原文,博主在此不再赘述。
算法优点
1、省参数。在 ImageNet 分类数据集上达到同样的准确率,DenseNet 所需的参数量不到 ResNet 的一半。对于工业界而言,小模型可以显著地节省带宽,降低存储开销。
2、省计算。达到与 ResNet 相当的精度,DenseNet 所需的计算量也只有 ResNet 的一半左右。计算效率在深度学习实际应用中的需求非常强烈,从本次 CVPR 会上大家对模型压缩以及 MobileNet 和 ShuffleNet 这些工作的关注就可以看得出来。最近我们也在搭建更高效的 DenseNet,初步结果表明 DenseNet 对于这类应用具有非常大的潜力,即使不用 Depth Separable Convolution 也能达到比现有方法更好的结果,预计在近期我们会公开相应的方法和模型。
3、抗过拟合。DenseNet 具有非常好的抗过拟合性能,尤其适合于训练数据相对匮乏的应用。对于 DenseNet 抗过拟合的原因有一个比较直观的解释:神经网络每一层提取的特征都相当于对输入数据的一个非线性变换,而随着深度的增加,变换的复杂度也逐渐增加(更多非线性函数的复合)。相比于一般神经网络的分类器直接依赖于网络最后一层(复杂度最高)的特征,DenseNet 可以综合利用浅层复杂度低的特征,因而更容易得到一个光滑的具有更好泛化性能的决策函数。实际上,DenseNet 的泛化性能优于其他网络是可以从理论上证明的:去年的一篇几乎与 DenseNet 同期发布在 arXiv 上的论文(AdaNet: Adaptive Structural Learning of Artificial Neural Networks)所证明的结论(见文中 Theorem 1)表明类似于 DenseNet 的网络结构具有更小的泛化误差界。
4、泛化性能更强。如果没有data augmention,CIFAR-100下,ResNet表现下降很多,DenseNet下降不多,说明DenseNet泛化性能更强。
提出算法出发点
目前来看,深度卷积网络挑战主要有:
1.Underfitting(欠拟合)。一般来说,模型越为复杂,表达能力越强,越不容易欠拟合。但是深度网络不一样,模型表达能力够,但是算法不能达到那个全局的最优(resnet基本解决)。
2.Overfiting(过拟合),泛化能力下降。
3.实际系统的部署。如何提升效率和减少内存、能量消耗。
Insight:如何消除上述的冗余性?更紧致的结构?更好的泛化性能?由随机网络深度,我们就得知训练时扔掉大部分层却效果不错,说明冗余性很多,每一层干的事情很少,只学一点东西。
目的:减少不必要的计算,提高泛化性能。
如何对 DenseNet 的模型做改进
-
每层开始的瓶颈层(1x1 卷积)对于减少参数量和计算量非常有用。
-
像 VGG 和 ResNet 那样每做一次下采样(down-sampling)之后都把层宽度(growth rate) 增加一倍,可以提高 DenseNet 的计算效率(FLOPS efficiency)。
-
与其他网络一样,DenseNet 的深度和宽度应该均衡的变化,当然 DenseNet 每层的宽度要远小于其他模型。
-
每一层设计得较窄会降低 DenseNet 在 GPU 上的运算效率,但可能会提高在 CPU 上的运算效率。
原作者面对疑问的解释
1、密集连接不会带来冗余吗?
这是一个很多人都在问的问题,因为「密集连接」这个词给人的第一感觉就是极大的增加了网络的参数量和计算量。但实际上 DenseNet 比其他网络效率更高,其关键就在于网络每层计算量的减少以及特征的重复利用。DenseNet 的每一层只需学习很少的特征,使得参数量和计算量显著减少。比如对于 ImageNet 上的模型,ResNet 在特征图尺寸为 7x7 的阶段,每个基本单元(包含三个卷积层)的参数量为 2048x512x1x1+512x512x3x3+512x2048x1x1=4.5M,而 DenseNet 每个基本单元(包含两个卷积层,其输入特征图的数量一般小于 2000)的参数量约为 2000x4x32x1x1 + 4x32x32x3x3 = 0.26M,大幅低于 ResNet 每层的参数量。这就解释了为什么一个 201 层的 DenseNet 参数量和计算量都只有一个 101 层 ResNet 的一半左右。
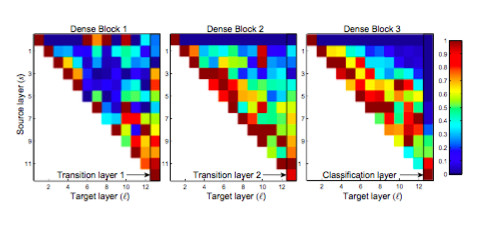
还有一个自然而然的问题就是,这么多的密集连接,是不是全部都是必要的,有没有可能去掉一些也不会影响网络的性能?论文里面有一个热力图(heatmap),直观上刻画了各个连接的强度。从图中可以观察到网络中比较靠后的层确实也会用到非常浅层的特征。
via
我们还做过一些简单的实验,比如每一层都只连接到前面最近的 m 层(例如 m=4),或者奇(偶)数层只与前面的偶(奇)数层相连,但这样简化后的模型并没有比一个相应大小的正常 DenseNet 好。当然这些都只是一些非常初步的尝试,如果采用一些好的剪枝(prune)的方法,我觉得 DenseNet 中一部分连接是可以被去掉而不影响性能的。
2、DenseNet 特别耗费显存?
不少人跟我们反映过 DenseNet 在训练时对内存消耗非常厉害。这个问题其实是算法实现不优带来的。当前的深度学习框架对 DenseNet 的密集连接没有很好的支持,我们只能借助于反复的拼接(Concatenation)操作,将之前层的输出与当前层的输出拼接在一起,然后传给下一层。对于大多数框架(如 Torch 和 TensorFlow),每次拼接操作都会开辟新的内存来保存拼接后的特征。这样就导致一个 L 层的网络,要消耗相当于 L(L+1)/2 层网络的内存(第 l 层的输出在内存里被存了 (L-l+1) 份)。
解决这个问题的思路其实并不难,我们只需要预先分配一块缓存,供网络中所有的拼接层(Concatenation Layer)共享使用,这样 DenseNet 对内存的消耗便从平方级别降到了线性级别。在梯度反传过程中,我们再把相应卷积层的输出复制到该缓存,就可以重构每一层的输入特征,进而计算梯度。当然网络中由于 Batch Normalization 层的存在,实现起来还有一些需要注意的细节。
新的实现极大地减小了 DenseNet 在训练时对显存的消耗,比如论文中 190 层的 DenseNet 原来几乎占满了 4 块 12G 内存的 GPU,而优化过后的代码仅需要 9G 的显存,在单卡上就能训练。
另外就是网络在推理(或测试)的时候对内存的消耗,这个是我们在实际产品中(尤其是在移动设备上)部署深度学习模型时最关心的问题。不同于训练,一般神经网络的推理过程不需要一直保留每一层的输出,因此可以在每计算好一层的特征后便将前面层特征占用的内存释放掉。而 DenseNet 则需要始终保存所有前面层的输出。但考虑到 DenseNet 每一层产生的特征图很少,所以在推理的时候占用内存不会多于其他网络。
3、DenseNet 是受什么启发提出来的?
DenseNet 的想法很大程度上源于我们去年发表在 ECCV 上的一个叫做随机深度网络(Deep networks with stochastic depth)工作。当时我们提出了一种类似于 Dropout 的方法来改进ResNet。我们发现在训练过程中的每一步都随机地「扔掉」(drop)一些层,可以显著的提高 ResNet 的泛化性能。这个方法的成功至少带给我们两点启发:
-
首先,它说明了神经网络其实并不一定要是一个递进层级结构,也就是说网络中的某一层可以不仅仅依赖于紧邻的上一层的特征,而可以依赖于更前面层学习的特征。想像一下在随机深度网络中,当第 l 层被扔掉之后,第 l+1 层就被直接连到了第 l-1 层;当第 2 到了第 l 层都被扔掉之后,第 l+1 层就直接用到了第 1 层的特征。因此,随机深度网络其实可以看成一个具有随机密集连接的 DenseNet。
-
其次,我们在训练的过程中随机扔掉很多层也不会破坏算法的收敛,说明了 ResNet 具有比较明显的冗余性,网络中的每一层都只提取了很少的特征(即所谓的残差)。实际上,我们将训练好的 ResNet 随机的去掉几层,对网络的预测结果也不会产生太大的影响。既然每一层学习的特征这么少,能不能降低它的计算量来减小冗余呢?
DenseNet 的设计正是基于以上两点观察。我们让网络中的每一层都直接与其前面层相连,实现特征的重复利用;同时把网络的每一层设计得特别「窄」,即只学习非常少的特征图(最极端情况就是每一层只学习一个特征图),达到降低冗余性的目的。这两点也是 DenseNet 与其他网络最主要的不同。需要强调的是,第一点是第二点的前提,没有密集连接,我们是不可能把网络设计得太窄的,否则训练会出现欠拟合(under-fitting)现象,即使 ResNet 也是如此。