花指令:在代码中插入的不影响程序运行的垃圾指令(脏字节),让反编译器无法反编译起到混淆代码的作用。
原理:反汇编算法的设计缺陷
反汇编算法主要可以分为两类:递归下降算法和线性扫描算法。
-
线性扫描算法
线性扫描算法p1从程序的入口点开始反汇编,然后整个代码段进行扫描,反汇编扫描过程中所遇到的每条指令。线性扫描算法的缺点在于在冯诺依曼体系下,无法区分数据和代码,从而导致将代码段中嵌入的数据误解释为指令的操作码,一致最后得到错误的反汇编结果。
-
递归下降
递归下降采取另外一种不同的方法来定位指令。递归下降算法强调控制流的概念。控制流根据一条指令是否被另一条指令引用来决定是否对其进行反汇编,遇到非控制转移指令时顺序进行反汇编,而遇到控制转移指令时则从转移地址处开始进行反汇编。通过构造必然条件或者互补条件,使得反汇编出错。
关于花指令的构造
花指令的名言:
构造永恒跳转,插入垃圾数据
我们通过在代码中内嵌汇编指令实现插入花指令。在不同的编译器中我们嵌入汇编的格式也不同。
主要的编译器分别为msvc和gcc,我们每个例子都会写出两种不同编译器的实现方法。
msvc内嵌汇编
#include<stdio.h>
int main() {
#嵌入汇编代码
__asm {
jmp s;
#emit指令用于插入垃圾数据
_emit 0xe9;
s:
}
printf("hello world!\n");
return 0;
}
gcc内嵌汇编
#include<stdio.h>
int main() {
#gcc编译器内嵌汇编
__asm__ __volatile__ (
"jmp s\n\t" // 跳转指令,跳转到s标签
".byte 0xe9\n\t" // 插入字节0xC7
"s:\n\t" // s标签
);
printf("hello world!\n");
return 0;
}
常用的脏字节编码
构造跳转使插入的垃圾数据不被执行来欺骗反编译器。
我们将插入的垃圾数据称为脏字节。
下面就是我们插入花指令常用的脏字节。
call immed16 ----> E8 // 3字节指令,immed16为2字节,代表跳转指令的目的地址与下一条指令地址的距离
call immed32 ----> 9A // 5字节指令,immed32为4字节,代表跳转指令的目的地址与下一条指令地址的距离
jmp immed8 ----> EB
jmp immed16 ----> E9
jmp immed32 ----> EA
loop immed8 ----> E2
ret ----> C2
retn ----> C3
接下来我们介绍常见的花指令实现方式和清除方法。
简单jmp指令
jmp s
_emit 0xe9;
s:
这种 jmp 单次跳转只能骗过线性扫描算法,会被ida识别(递归下降)。
实现
msvc 编译器实现
#include<stdio.h>
int main() {
__asm {
jmp s;
_emit 0xe9;
s:
}
printf("hello world!\n");
return 0;
}
gcc 编译器实现
#include<stdio.h>
int main() {
__asm__ __volatile__ (
"jmp s\n\t"
".byte 0xe9\n\t"
"s:\n\t"
);
printf("hello world!\n");
return 0;
}
分析
我们将程序编译后利用ida打开查看
直接f5成功
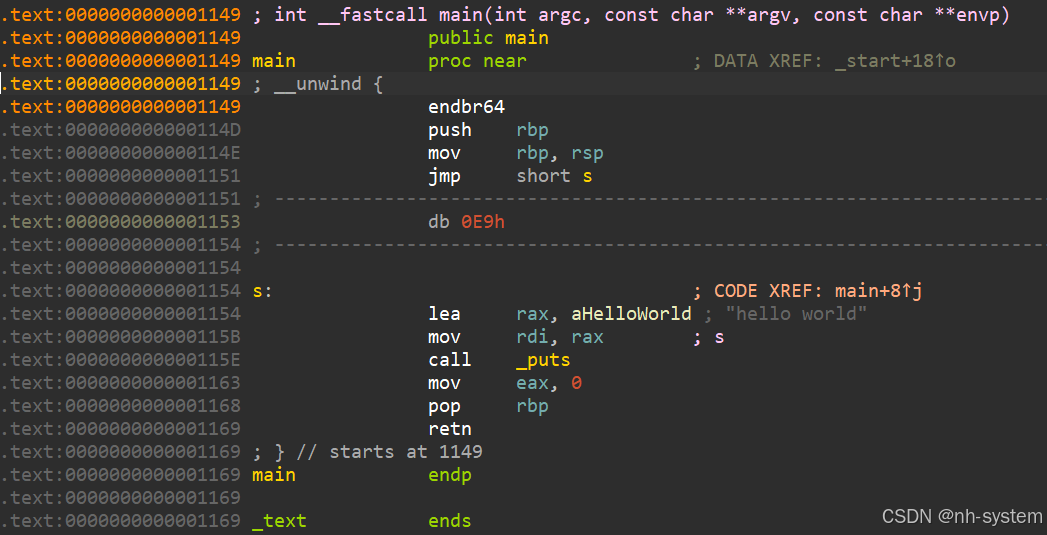
查看汇编代码,发现了我们插入的花指令。
很明显这种花指令无法骗过ida。
多层跳转
__asm{
jmp s1;
_emit 68h;
s1:
jmp s2;
_emit 0cdh;
_emit 20h;
s2:
jmp s3;
_emit 0e8h;
s3:
}
和单次跳转一样,这种也会被ida识别。
实现
msvc 编译器实现
#include<stdio.h>
int main() {
__asm {
jmp s1;
_emit 0xe9;
s1:
jmp s2;
s2:
jmp s3;
s3:
}
printf("hello world!\n");
return 0;
}
gcc 编译器实现
#include<stdio.h>
int main(){
__asm__ __volatile__(
"jmp s1\n\t"
".byte 0xe9\n\t"
"s1:\n\t"
"jmp s2\n\t"
".byte 0x68\n\t"
"s2:\n\t"
"jmp s3\n\t"
".byte 0x20\n\t"
"s3:\n\t"
);
printf("hello world\n");
return 0;
}
分析
同样ida打开成功f5。
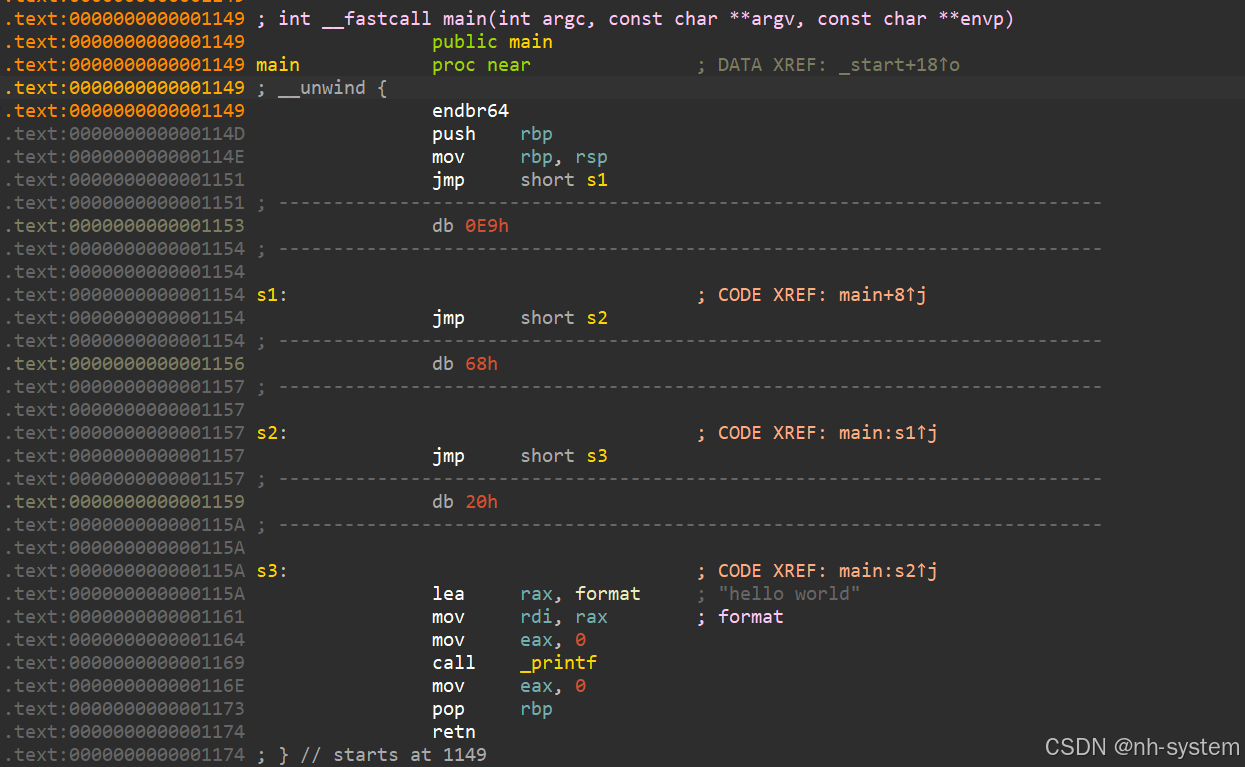
查看汇编代码,查看我们插入的花指令。
显然这种花指令也无法骗过ida。
jnx和jx互补跳转
__asm {
jz s;
jnz s;
_emit 0xC7;
s:
这种花指令去除方式也很简单,特征也很明显,因为是近跳转,所以ida分析的时候会分析出jz或者jnz会跳转几个字节,这个时候我们就可得到垃圾数据的长度,将该长度字节的数据全部nop掉即可解混淆。
实现
msvc 编译器实现
#include<stdio.h>
int main(){
__asm{
jz s:
jnz s:
_emit 0xe9;
s:
}
printf("hello world!\n");
return 0;
}
gcc 编译器实现
#include <stdio.h>
int main() {
printf("Before jump and emit instructions\n");
// 插入花指令
__asm__ __volatile__ (
"jz s\n\t" // 跳转指令
"jnz s\n\t" // 跳转指令
".byte 0xC7\n\t" // 插入字节0xC7
"s:\n\t" // 标签
);
printf("hello world!\n");
return 0;
}
分析
ida打开文件报红,f5反编译不成功。
很明显这种花指令骗过了ida。
接下来我们进行去除。
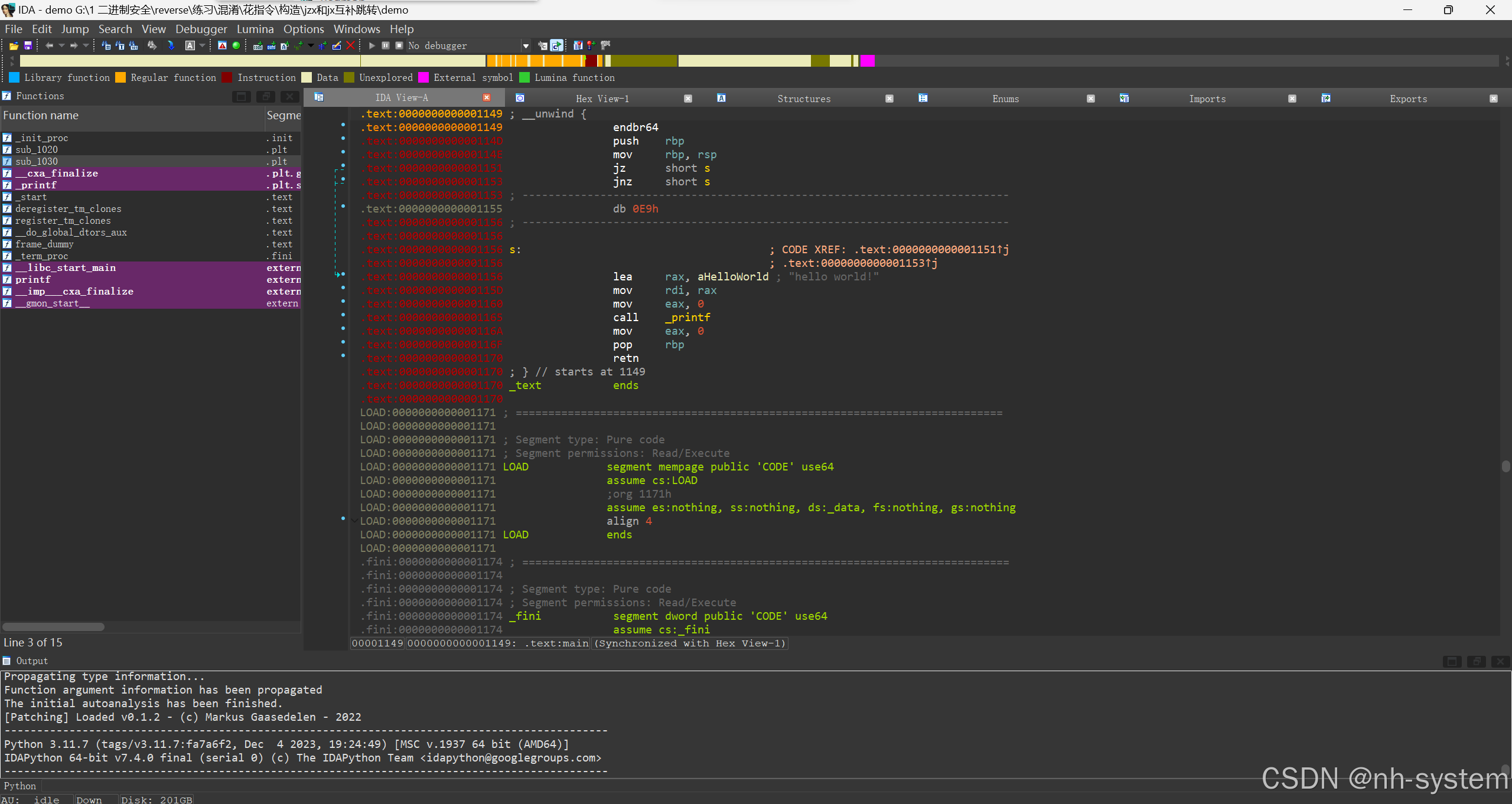
看到条件跳转到s,则中间的全部为垃圾数据。将其全部nop掉。
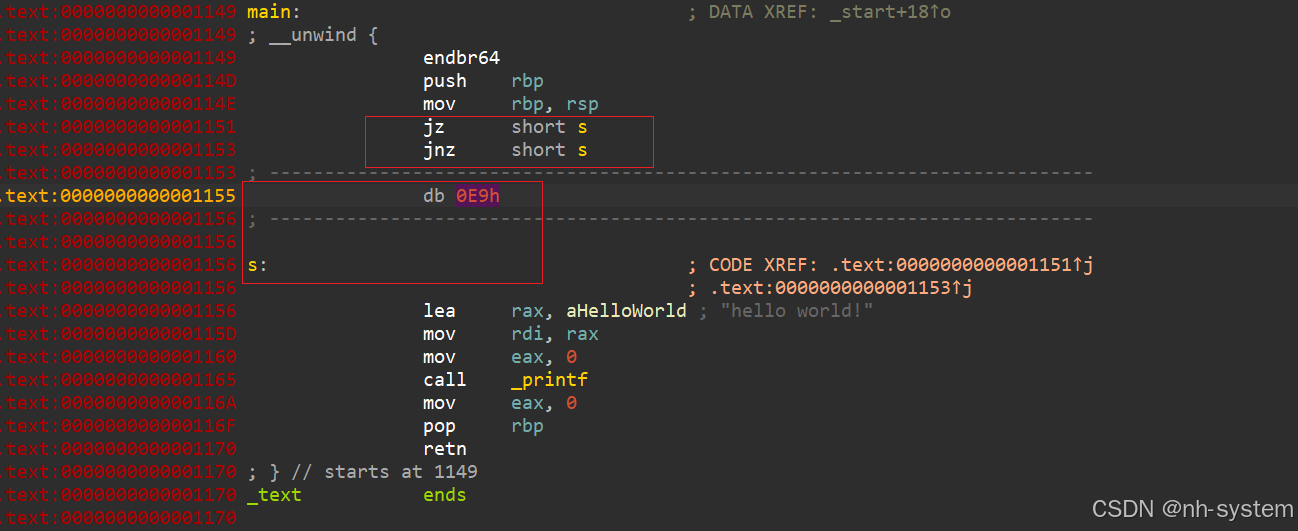
选中nop掉的数据的那一行,按快捷键c将数据解释为代码。
然后选中main函数头部,按p创建函数。
然后即可f5反编译。
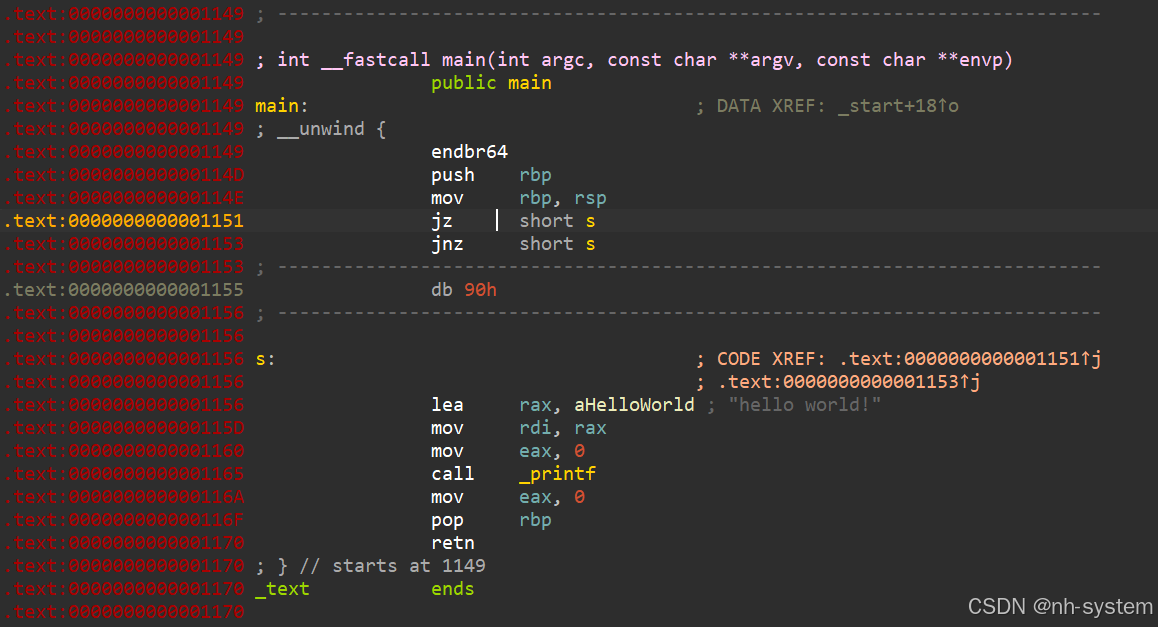
跳转指令构造花指令
__asm {
push ebx;
xor ebx, ebx;
test ebx, ebx;
jnz s1;
jz s2;
s1:
_emit 0xC7;
s2:
pop ebx;
}
实现
msvc 编译器实现
#include<stdio.h>
int main(){
__asm{
push ebx;
xor ebx,ebx;
test ebx,ebx;
jnz s1:
jz s2:
s1
_emit 0xe9;
s2:
pop ebx;
}
printf("hello world!\n");
return 0;
}
gcc 编译器实现
#include <stdio.h>
int main() {
printf("Before jump and emit instructions\n");
// 插入花指令
__asm__ __volatile__ (
"pushq %rbx\n\t" // 跳转指令
"xor %rbx,%rbx\n\t" // 跳转指令
"test %rbx,%rbx\n\t" // 插入字节0xC7
"jz s1\n\t"
"jnz s2\n\t"
"s1:\n\t"
".byte 0xc7\n\t"
"s2:\n\t"
"popq %rbx\n\t"
);
printf("hello world!\n");
return 0;
}
很明显,先对ebx进行xor之后,再进行test比较,zf标志位肯定为1,就肯定执行跳转 s1,也就是说中间0xC7永远不会执行。
不过这种一定要注意:记着保存ebx的值先把ebx压栈,最后在pop出来。
解混淆的时候也需要稍加注意,需要分析一下哪里是哪里是真正会跳到的位置,然后将垃圾数据nop掉,本质上和前面几种没什么不同。
分析
ida打开程序无法反编译,可以看到我们插入的花指令。
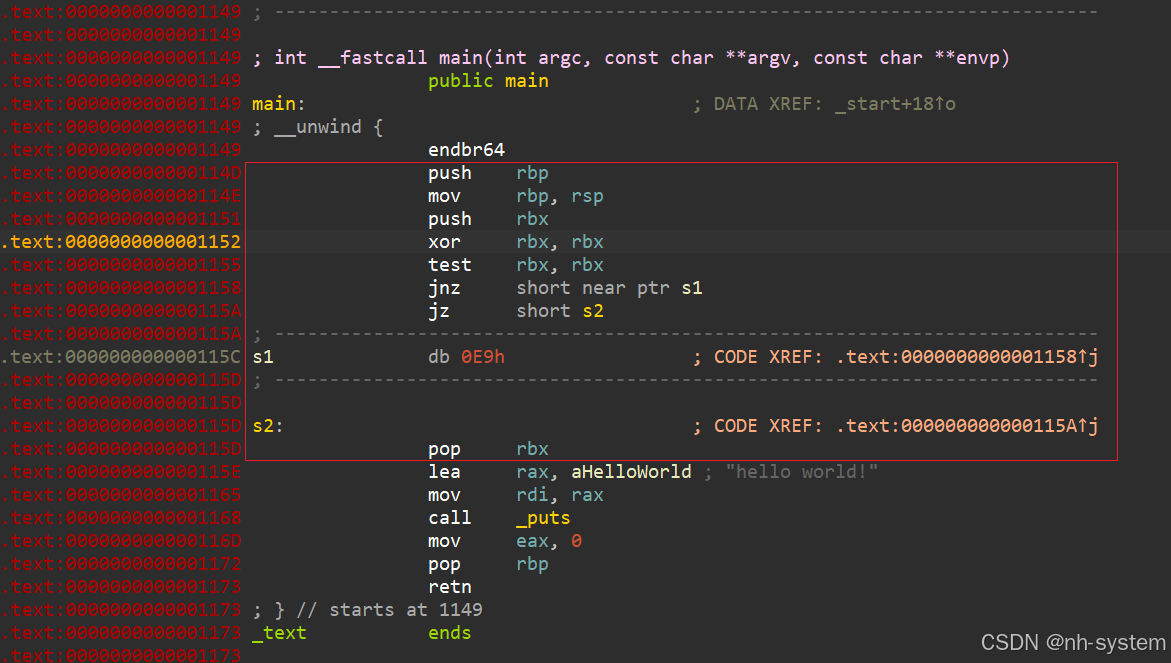
根据汇编代码判断哪里s1永远不会执行。
然后将插入的垃圾数据nop掉。
之后选中nop掉的数据的那一行,按快捷键c将数据解释为代码。
然后选中main函数头部,按p创建函数。
然后即可f5反编译。
call&ret构造花指令
__asm {
call LABEL9;
_emit 0x83;
LABEL9:
add dword ptr ss : [esp] , 8;
ret;
__emit 0xF3;
}
call之类的本质:push 函数返回地址然后 jmp 函数地址
ret指令的本质:pop eip
代码中的esp存储的是函数返回地址,对[esp]+8,就是函数的返回地址+8,正好盖过代码中的函数指令和垃圾数据。
实现
msvc 编译器实现
#include<stdio.h>
int main(){
__asm{
call s;
_emit 0x83;
s:
add dword ptr ss:[esp],8;
ret;
_emit 0xf3;
}
printf("hello world!\n");
return 0;
}
gcc 编译器实现
#include <stdio.h>
int main() {
printf("Before jump and emit instructions\n");
// 插入花指令
__asm__ __volatile__ (
"call s\n\t"
".byte 0x83\n\t"
"s:\n\t"
"addq 8,(%rsp)\n\t"
"ret\n\t"
".byte 0xf3\n\t"
);
printf("hello world!\n");
return 0;
}
分析
ida打开看到我们插入的花指令,
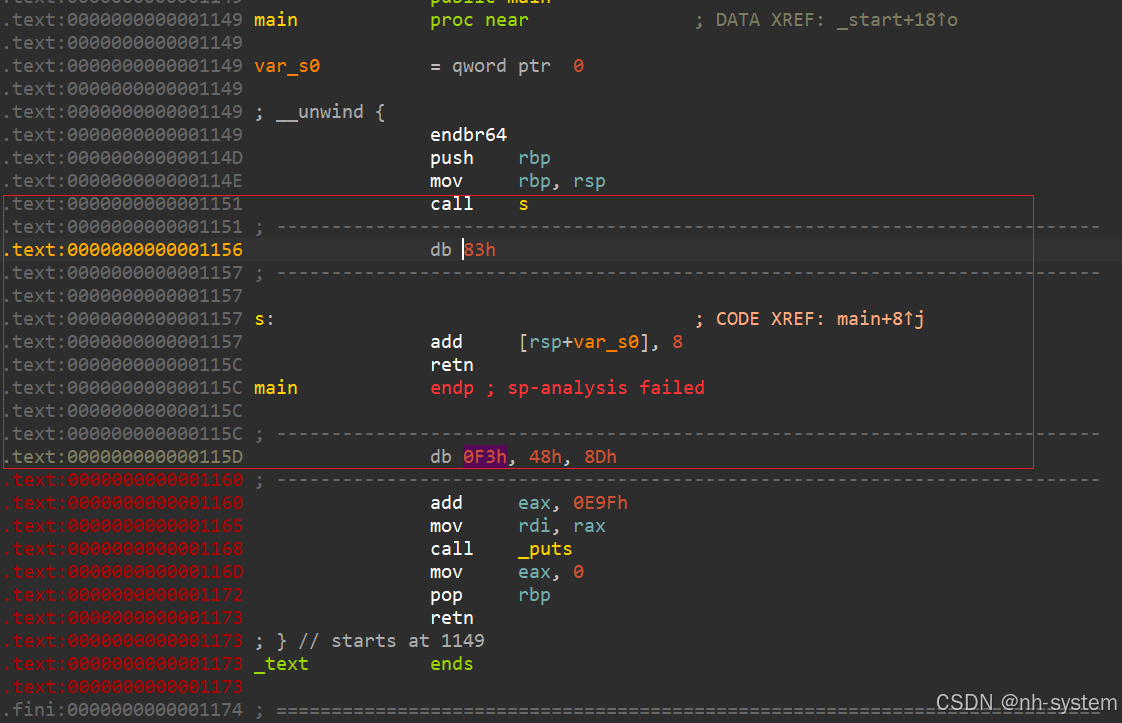
分析代码,call s直接跳转到s并将下一行代码入栈。
则0x83h永远不会被执行,并且将其地址入栈。
add指令将栈顶数据即0x83h地址加上8,则栈上地址为0x115e。
经过retn指令后,执行流直接跳到0x48h。
则不被执行的0x83和0xf3h都是垃圾数据,将它们nop即可。
汇编指令共用opcode
jmp的条指令是inc eax的第一个字节,inc eax和dec eax低效影响。这种共用opcode确实比较麻烦。
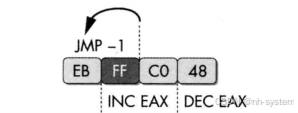
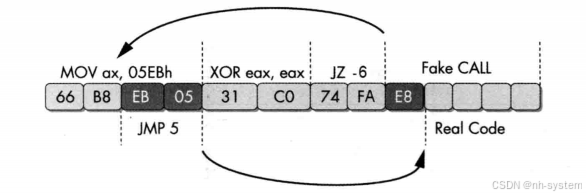
实现
msvc 编译器实现
#include<stdio.h>
int main(){
__asm{
_emit 0xeb,0xff,0xc0,0x48
}
printf("hello world!\n");
return 0;
}
gcc 编译器实现
#include <stdio.h>
int main() {
// 插入花指令
__asm__ __volatile__ (
".byte 0xeb,0xff,0xc0,0x48\n\t"
);
printf("hello world!\n");
}
分析
这种确实不好处理。。。。
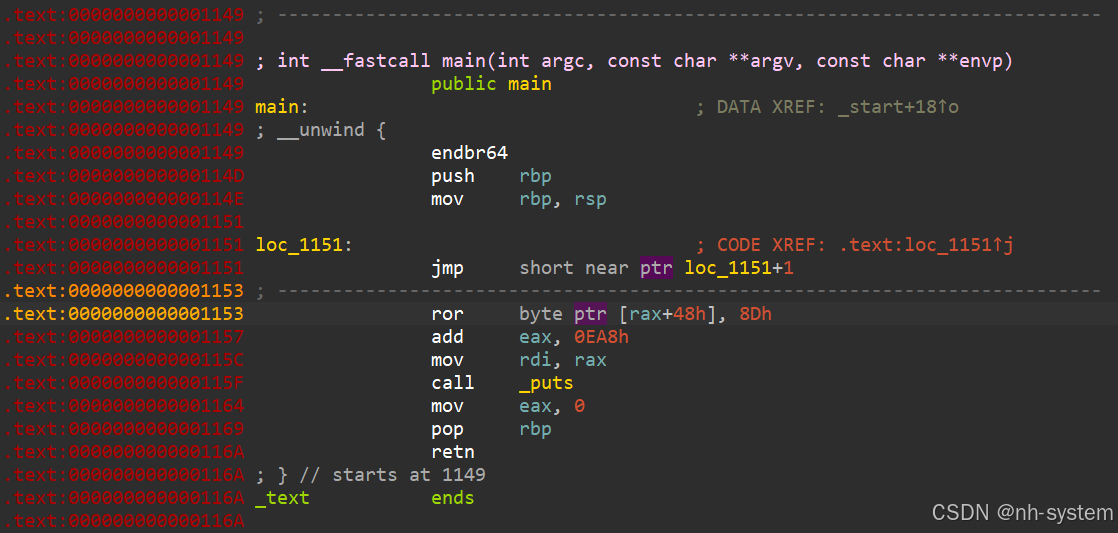
通过汇编代码逻辑分析哪些可能是花指令。
脚本清除花指令
除汇编指令共用之外,上面有3个类别花指令ida无法正常识别
- 互补条件跳转(比较好处理)
- 永真条件跳转(各种永真条件比较难匹配)
- call&ret跳转(比较难处理)
所以就只对第一种jnx和jx的花指令进行自动化处理
所有的跳转指令,互补跳转指令只有最后一个不同
70 <–> JO(O标志位为1跳转)
71 <–> JNO
72 <–> JB/JNAE/JC
73 <–> JNB/JAE/JNC
74 <–> JZ/JE
75 <–> JNZ/JNE
76 <–> JBE/JNA
77 <–> JNBE/JA
78 <–> JS
79 <–> JNS
7A <–> JP/JPE
7B <–> JNP/JPO
7C <–> JL/JNGE
7D <–> JNL/JGE
7E <–> JLE/JNG
7F <–> JNLE/JG
抄大佬的代码
from ida_bytes import get_bytes,patch_bytes
start= 0x401000#start addr
end = 0x422000
buf = get_bytes(start,end-start)
def patch_at(p,ln):
global buf
buf = buf[:p]+b"\x90"*ln+buf[p+ln:]
fake_jcc=[]
for opcode in range(0x70,0x7f,2):
pattern = chr(opcode)+"\x03"+chr(opcode|1)+"\x01"
fake_jcc.append(pattern.encode())
pattern = chr(opcode|1)+"\x03"+chr(opcode)+"\x01"
fake_jcc.append(pattern.encode())
print(fake_jcc)
for pattern in fake_jcc:
p = buf.find(pattern)
while p != -1:
patch_at(p,5)
p = buf.find(pattern,p+1)
patch_bytes(start,buf)
print("Done")
后言
暂时研究到这里,后面再整理一下idapython去花的内容和其它花指令的内容。
参考链接:花指令总结-安全客 - 安全资讯平台 (anquanke.com)