一、项目简介
随着信息时代的快速发展,电子邮件作为人们日常沟通的重要方式也变得日益普及。然而,随之而来的垃圾邮件问题不可避免地困扰着用户,对邮件通信质量造成负面影响。为了解决这一问题,我们开发了基于朴素贝叶斯算法和TF-IDF特征提取的邮件分类系统。
技术方面,我们借助Python编程语言和Sklearn、Flask、Echarts等库与框架,构建了这个功能强大的系统。朴素贝叶斯算法被选作核心分类算法,通过Sklearn库实现模型训练和分类,以提高系统的准确性。TF-IDF算法用于邮件特征提取,进一步优化了分类性能。
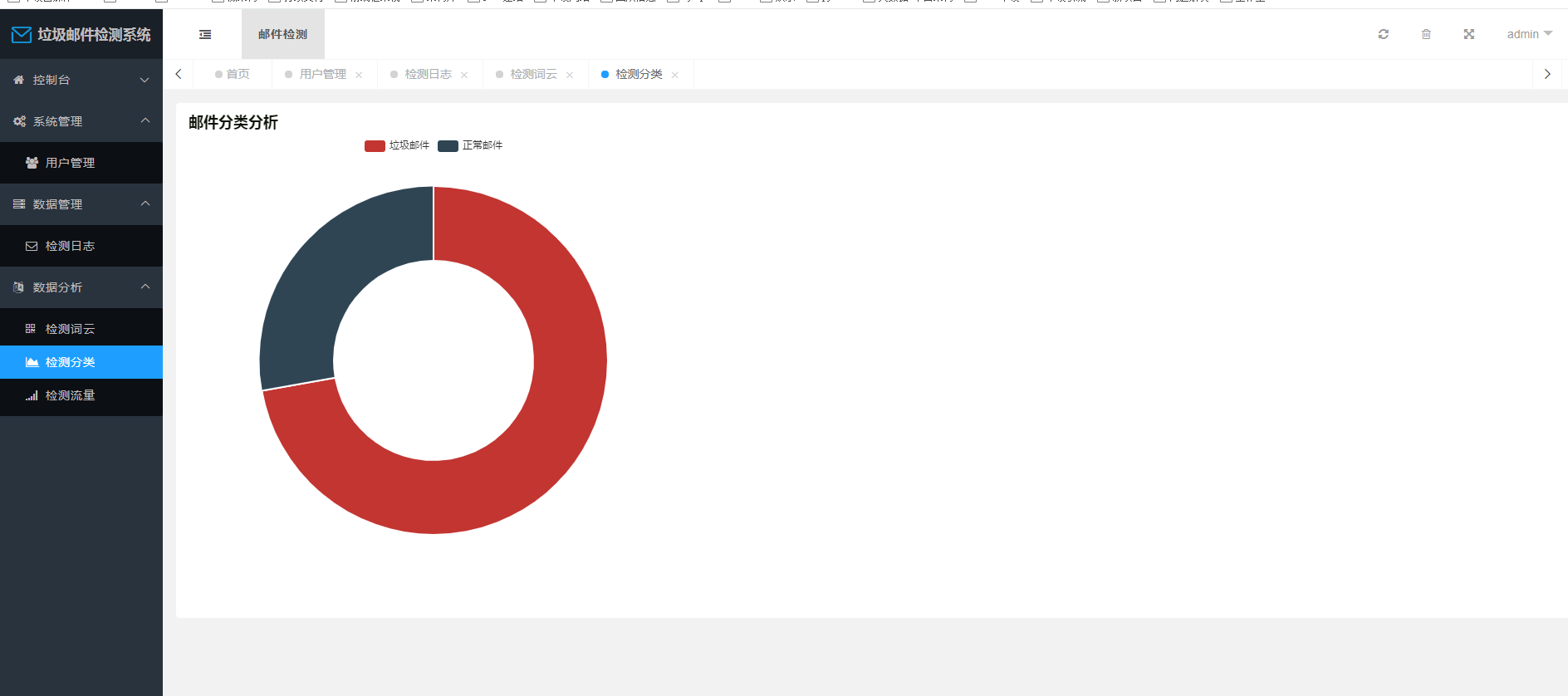
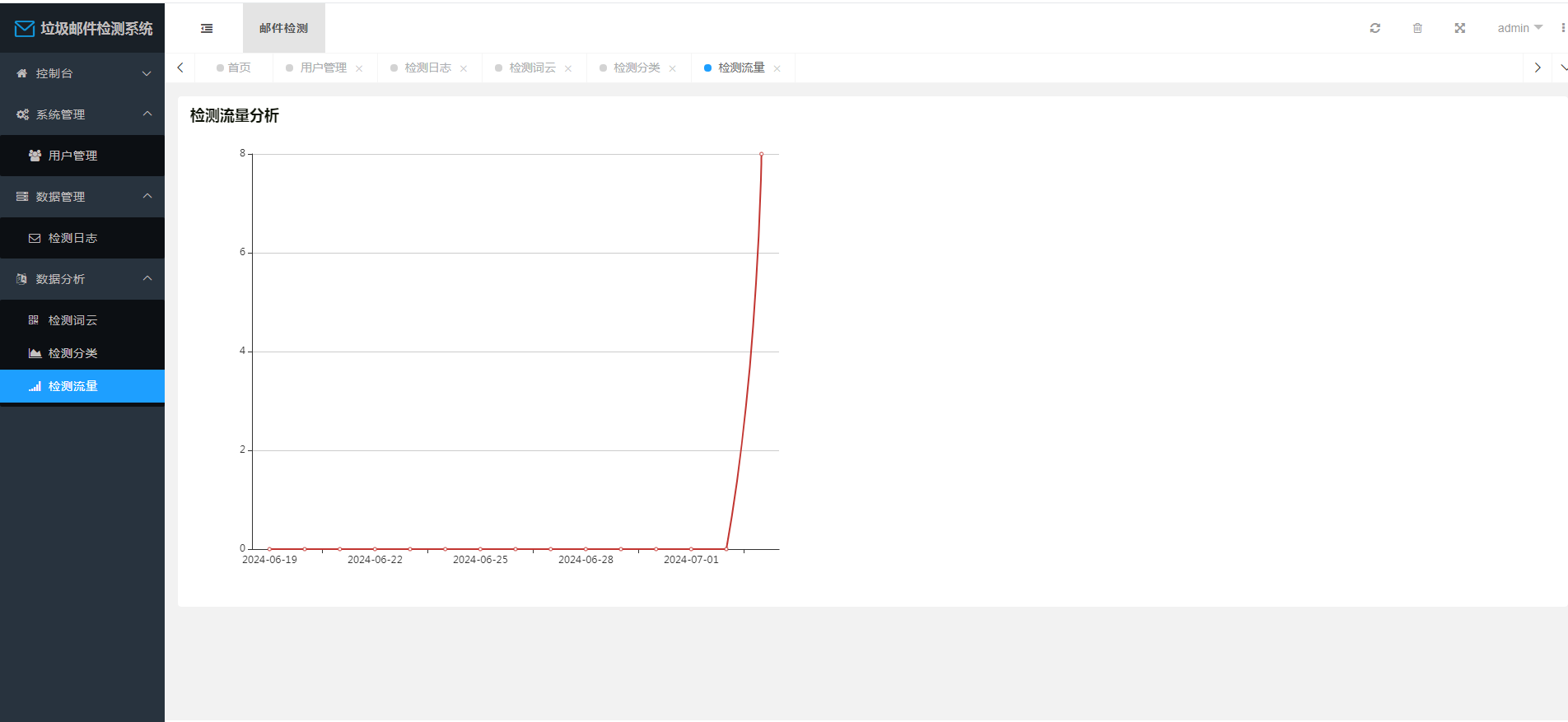
系统功能包括邮件检测与数据管理两大模块。邮件检测模块通过朴素贝叶斯算法和TF-IDF特征提取,对邮件进行准确分类,解决了垃圾邮件的问题。数据管理模块涵盖了数据存储、分析和可视化,通过Echarts库将检测日志内容以词云、分类饼状图和流量折线图的形式进行可视化展示,使用户能够直观了解邮件流量和分类情况。
这个系统的意义在于为用户提供了一个高效、智能的垃圾邮件分类解决方案。通过朴素贝叶斯算法,我们可以在海量的邮件中迅速准确地筛选出垃圾邮件,提升了邮件通信质量,释放了邮箱存储空间。同时,数据分析和可视化功能让用户能够更好地了解邮件流量和分类情况,为邮件管理提供了有力的支持。这样的系统符合现代社会信息化发展的趋势,对个人、企业和社会都具有积极的意义。
二、开发环境
| 开发环境 | 版本/工具 |
| PYTHON | 3.6.8 |
| 开发工具 | PyCharm |
| 操作系统 | Windows 10 |
| 内存要求 | 8GB 以上 |
| 浏览器 | Firefox (推荐)、Google Chrome (推荐)、Edge |
| 数据库 | MySQL 8.0 (推荐) |
| 数据库工具 | Navicat Premium 15 (推荐) |
| 项目框架 | FLASK、Skite-learn |
三、项目技术
Python: 作为开发语言,用于编写后端逻辑和数据处理。
Flask: Python的Web框架,用于搭建后端数据接口和处理HTTP请求。
PyMySQL: 用于Python与MySQL数据库的交互,实现数据的存储和读取。
Echarts: JavaScript的数据可视化库,将数据转化为图表形式展示给用户。
LAYUI: 轻量级前端UI框架,用于构建用户友好的交互界面。
JavaScript: 用于实现前端交互和处理用户输入。
HTML和CSS: 用于构建前端界面和样式设计。
scikit-learn、pandas和numpy: Python的数据处理和机器学习库,用于数据预测和分析。
AJAX: 用于实现前后端数据交互,异步请求后端数据接口。
MySQL: 数据库管理系统,用于持久化数据。
- 功能结构
系统功能结构图
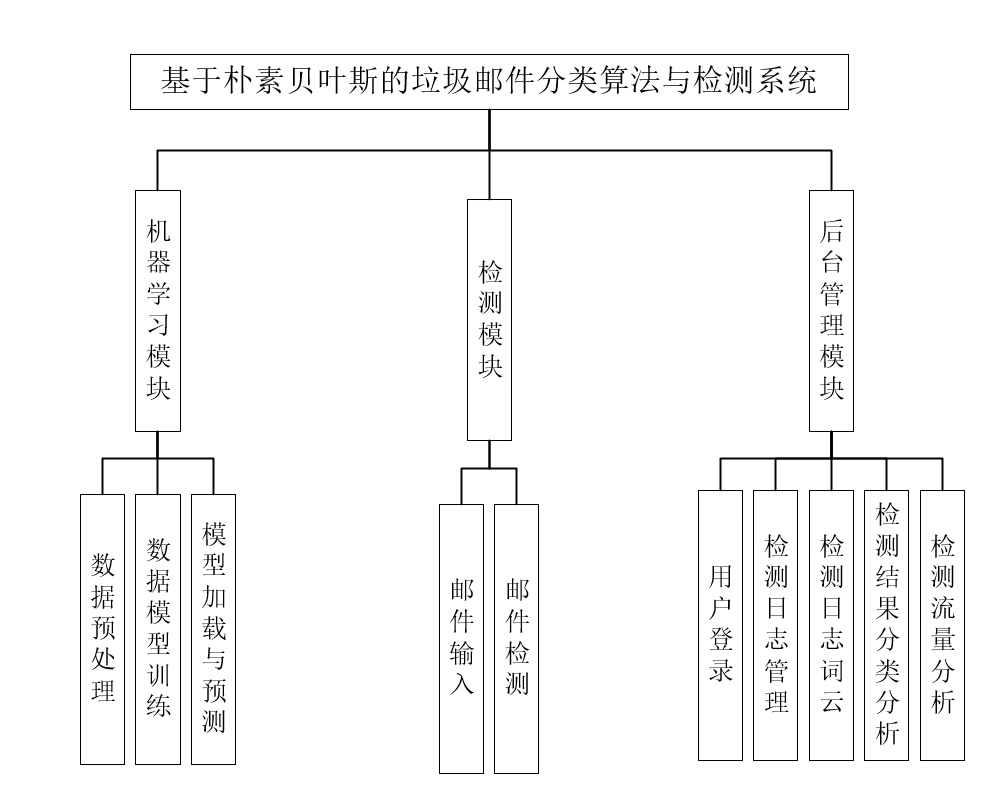
邮件检测与分类模块
功能描述
用户可以将邮件内容输入系统,系统基于朴素贝叶斯算法和TF-IDF特征提取进行邮件分类。将邮件分为垃圾邮件和正常邮件,以净化用户的邮箱。
技术实现简介
使用Sklearn库实现朴素贝叶斯算法模型的训练,将训练好的模型应用于用户输入的邮件内容,进行分类判别。TF-IDF算法用于对邮件内容进行特征提取,生成特征向量。
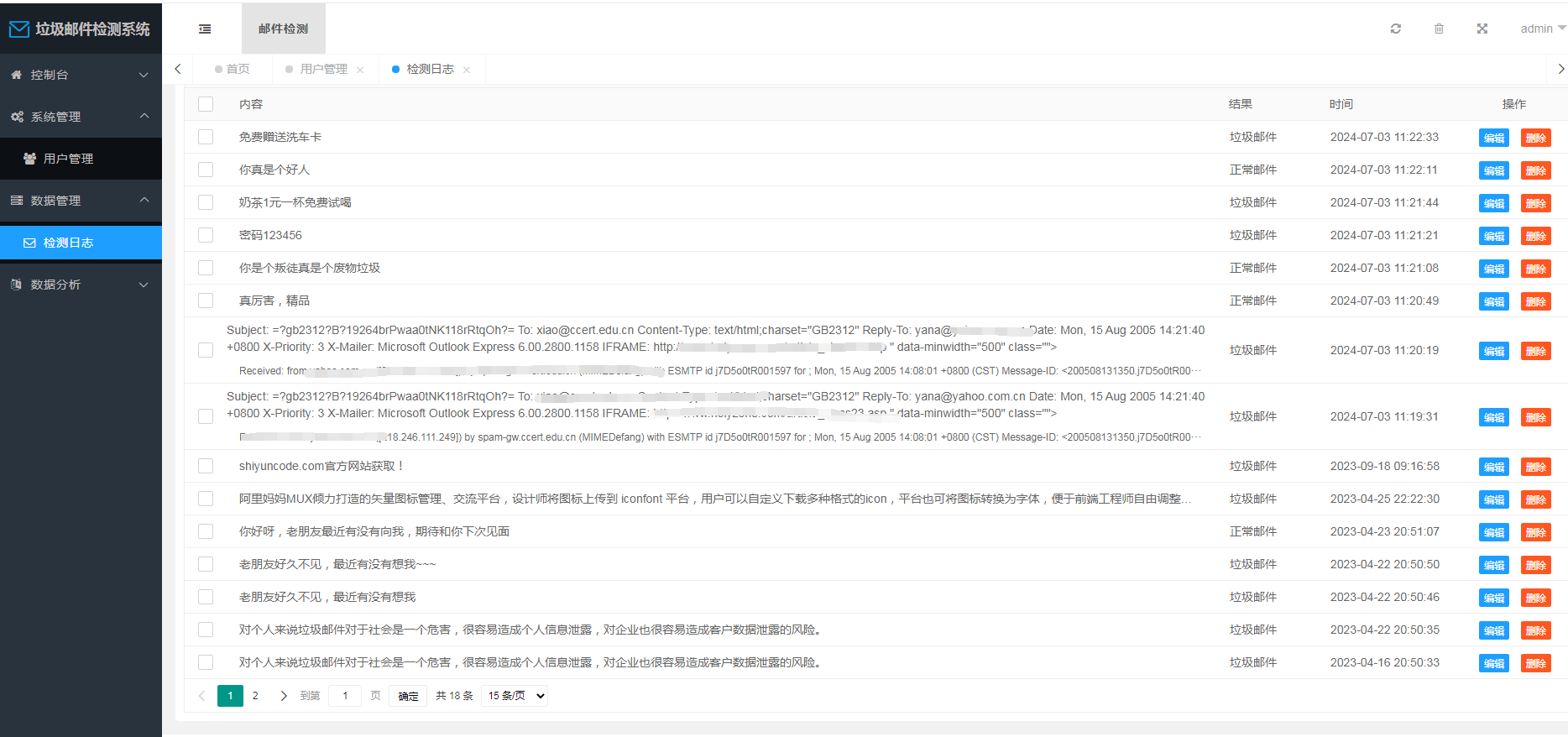
数据管理模块
功能描述
此模块负责存储和管理系统处理的邮件数据,包括垃圾邮件和正常邮件的分类结果,以及相关的检测日志。
技术实现简介
使用MySQL数据库进行数据存储,将邮件分类结果、检测日志等信息存储于数据库中。通过SQL语句实现对数据的存取、管理、查询等操作。
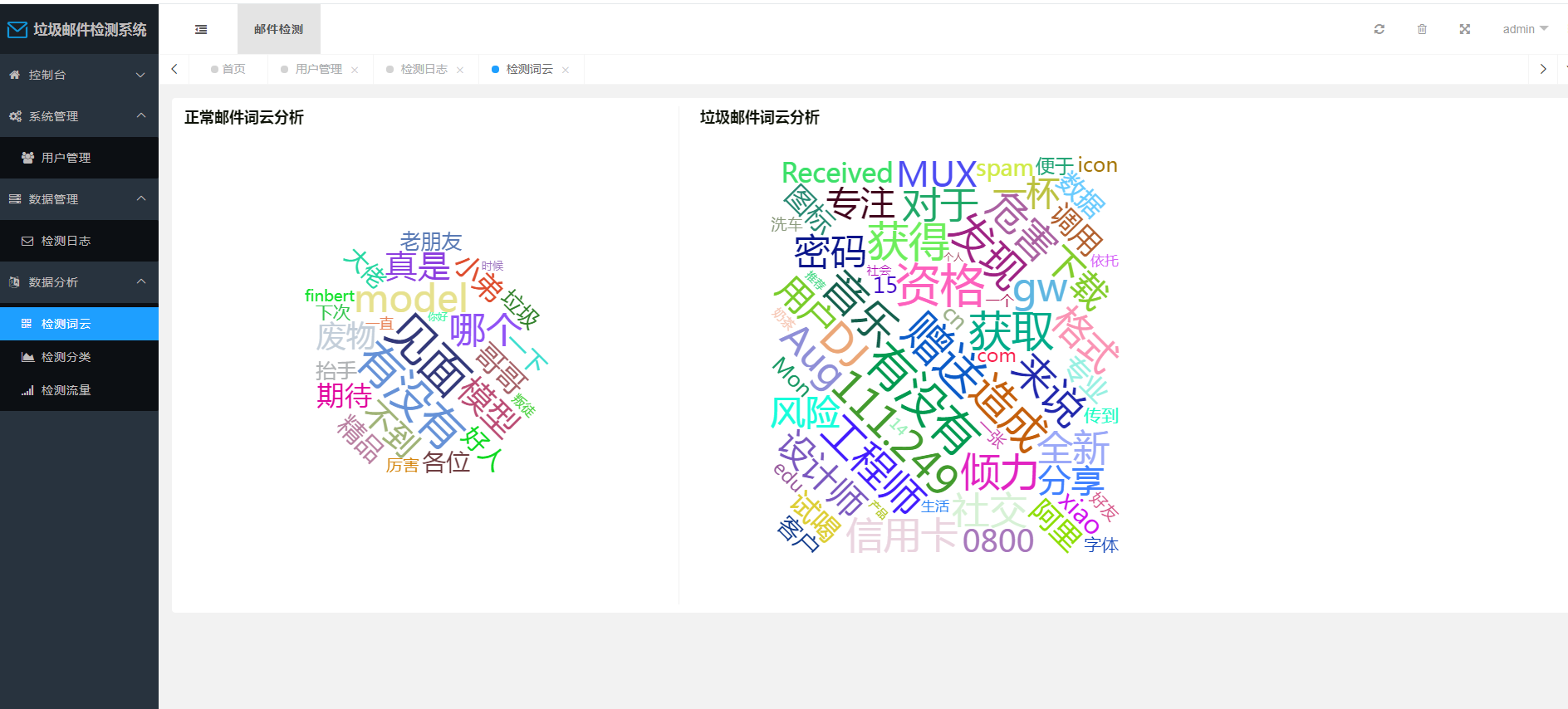
可视化分析模块
功能描述
提供对系统运行情况的数据分析和可视化展示,包括词云展示常见关键词、饼状图展示邮件分类比例、折线图展示检测流量趋势等。
技术实现简介
使用Echarts技术实现数据的可视化分析,根据数据从数据库中提取相应信息并以图表的形式展示。使用JavaScript对Echarts进行配置和调用,呈现给用户直观的数据分析结果。
这三个模块共同构成了整个系统的功能结构。邮件检测与分类模块解决了垃圾邮件分类问题,数据管理模块负责数据的存储和管理,可视化分析模块则通过图表直观展示数据分析结果,为用户提供全面的邮件管理解决方案。
五、运行截图

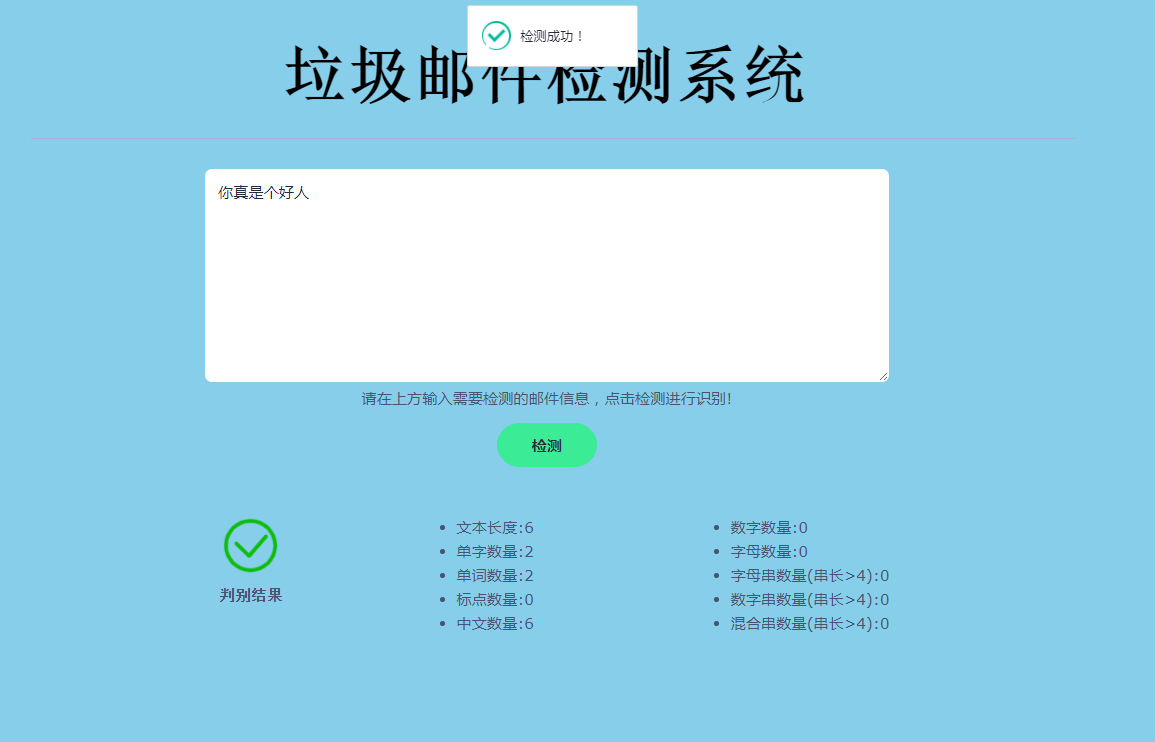

摘要:为了解决垃圾邮件导致邮件通信质量被污染、占用邮箱存储空间、伪装正常邮件进行钓鱼或诈骗以及邮件分类问题。应用Python、Sklearn、Echarts技术和Flask、Lay-UI框架,使用MySQL作为系统数据库,设计并实现了基于朴素贝叶斯算法的邮件分类系统,并以Web形式部署在本地计算机。运用Sklearn库对KNN算法、SVM算法和朴素贝叶斯算法进行建模和训练,将训练结果进行分析和对比得出朴素贝叶斯算法在准确率、召回率和精确率三个指标下比其他分类算法更适合邮件分类,因此选择朴素贝叶斯算法作为系统核心算法。系统功能包括邮件检测与数据管理两大核心模块,邮件检测模块,采用基于朴素贝叶斯算法,使用TF-IDF算法对邮件进行特征提取并将邮件内容以及检测结果存储于MySQL数据库,存储到MySQL中的数据将用于数据管理模块;数据管理模块包括数据存储、数据分析、数据可视化。系统采用黑盒测试方法对两个模块进行功能性测试,测试结果符合预期。系统满足设计基本需求,能安全、稳定和可靠地运行。
关键词:邮件分类;贝叶斯算法;MySQL;特征词提取
Design of mail classification system based on Naive Bayes
Abstract: In order to solve the spam resulting in mail communication quality pollution, occupy mailbox storage space, camouflage normal mail for phishing or fraud and mail classification problems. The mail classification system based on naive Bayes algorithm is designed and implemented by using Python, Sklearn, Echarts technology, Flask, Lay-UI framework and MySQL as the system database, and is deployed on the local computer in the form of Web. Sklearn was used to model and train KNN algorithm, SVM algorithm and naive Bayes algorithm, and the training results were analyzed and compared. Through comparison, it was concluded that naive Bayes algorithm was more suitable for mail classification than other classification algorithms under the three indexes of accuracy, recall rate and accuracy rate. Therefore, naive Bayes algorithm was chosen as the core algorithm of the system. The system functions include two core modules: mail detection and data management. Mail detection module, based on naive Bayes algorithm, uses TF-IDF algorithm to classify mails and store mail contents and detection results in MySQL database. Data stored in MySQL will be used in data management module. The data management module includes data storage, data analysis and data visualization. System uses black box test method to perform functional test on the two modules, and the test results are in line with expectations. The system meets the basic design requirements and can run safely, stably and reliably.
Keywords: Mail classification; Bayesian algorithm; MySQL; Feature word extraction
目 录
1.1 项目背景 1
1.2 国内外现状 1
1.3 项目意义 2
6.2 系统检测信息可视化以及邮件内容分析
1 绪论
1.1 项目背景
随着互联网技术的普及与应用,现今拥有各种各样的网络通讯工具,邮件作为比较正式的网络通讯工具,被互联网用户广泛的使用着,同时邮件也具有操作便利、费用低廉、速度快捷等特点,但是邮件为人们带来便利的同时,也带来了种种负面影响。人们时常会收到一些无用的推销邮件,以及散布虚假信息、反动和色情信息,甚至还有包含病毒的邮件,需要花费大量的精力和时间来清理这些垃圾邮件,这给日常生活带来了麻烦,消耗了大量的网络资源和存储空间,为社会带来了比较大的危害[1]。
1.2 国内外现状
中国互联网协会定义垃圾邮件:未经用户许可发送同时发送给大量用户,影响正常网络通信;含有恶意的、虚假的、伪装的邮件发信人等信息。2003年2月26日,中国互联网协会颁布的《中国互联网协会垃圾邮件对策规范》第3条规定:收件人事先未提出要求或不同意接收的广告、电子刊物、各种形式宣传物等宣传性电子邮件;收件人无法拒绝的电子邮件;隐藏发送者身份、地址、标题等信息的电子邮件;包含假信息源、发送者、路由等信息的电子邮件。垃圾邮件的危害主要有以下五个方面。
(1)降低通信服务质量:占用网络带宽,造成邮件服务器堵塞,降低整个网络的运营效率。
(2)干扰了人的正常工作生活,垃圾邮件耗费收件人的时间、精力。
(3)被少数别有用心的人利用邮件的便利性以及隐蔽性广泛散播虚假有害信息,严重危害社会稳定。
(4)有些钓鱼邮件具有隐蔽性和危险性,不认真审查就会泄露信息,继而被不法分子进行电信诈骗,泄露机密信息等不法行为,严重影响社会稳定。
(5)影响LSP的服务形象,发送较多的垃圾邮件的主机会被国际反垃圾阻止列入黑名单,导致该主机访问网站或者发送邮件受到限制[2]。
从2020年到2023年期间,有关于邮件分类的研究主要关注以下四个方面:
(1)深度学习在邮件分类中的应用:随着深度学习技术的不断发展和应用,越来越多的研究者开始尝试将其应用于邮件分类领域。这种新型算法可以自动提取特征,对大规模数据进行训练,从而提高了分类精度。
(2)较少监督的邮件分类方法:监督学习方法需要大量标记好的数据作为训练集,但很多情况下难以获得足够的标记数据。因此,较少监督的或无监督的邮件分类方法逐渐成为研究热点。例如,基于主题模型、协同分类等方法,可以利用已有的少量标记数据和大量未标记数据进行分类。
(3)多语言邮件分类:随着全球化的加速,越来越多的邮件涉及多种语言,使得多语言邮件分类成为重要的问题。近年来,一些研究者提出了针对多语言邮件分类的方法,如通过跨语言知识迁移、多语言文本嵌入等方式解决多语言分类问题。
(4)针对特定领域邮件分类:随着各行业的快速发展,不同领域的邮件也呈现出多样化的特点。因此,在邮件分类研究中,针对特定领域的邮件分类也成为了一个热点问题。例如,针对医疗、法律等特定领域的邮件分类研究逐渐增多[3]。
综上所述,从2020年到2023年期间,邮件分类的研究主要关注于深度学习的应用、较少监督的方法、多语言和特定领域邮件的分类等问题,这些研究成果可以为系统设计提供更加精准和高效的邮件分类技术。
1.3 项目意义
基于上述邮件分类项目的背景介绍,实现邮件分类系统不但能够解决邮件分类问题,节省更多的人力资源,提高用户的工作效率,而且可以避免垃圾邮件对用户带来的骚扰。接下来将结合邮件预处理技术以及邮件分类算法,实现邮件分类系统。
在进行垃圾邮件识别之前,我们首先需要对邮件数据进行预处理。预处理步骤包括文本分词、去除停用词、词干提取等。接下来介绍邮件内容组成以及三种文本分词技术和五种特征词分类算法。
因为电子邮件在传输过程中需要进行编码,以便于网络传输和存储,所以解析电子邮件需要解码,电子邮件数据的解码过程分为两个过程:
ASCII解码:将8位二进制数转换成对应的字符。
Base64解码:将Base64编码后的文本转换成二进制数据。Quoted-printable解码:将“=”加上其十六进制编码转换成对应的字符。需要注意的是,邮件内容的编码方式和解码方式需要同时使用,才能正确地还原邮件内容。
文本分词是一种自然语言处理技术,用于将自然语言文本分解成具有实际含义的单词或符号序列,称为词汇项。文本分词是邮件分类系统中重要的一个环节,对系统有很大的影响。分类方法一般分为两类:英文分词和中文分词[4]。
常见的文本分词技术包括基于规则的方法和基于统计学习的方法。基于规则的方法使用一组预定义规则,例如词典和语法规则,来将文本分解成单词和短语。这种方法的局限性在于需要手动添加规则,并且在面对复杂和未知的情况时效果不佳。
现在对中文分词的方法主要有三种方法:正向最大匹配法、全切分法和基于词频分词法。下文就这三种中文分词方法的原理和特点进行简单的介绍和举例说明。
2.2.1 正向最大匹配法
正向最大匹配法的基本原理是:是从左到右扫描待分词的文本,每次取文本的前面一段最长的词作为切分出的词,然后将这个词从待分词文本中去掉,继续对剩下的文本进行切分,直到文本全部被切分为止[5]。其中最大匹配指的是每次选择的词具有最长的匹配长度。
对于正向最大匹配法来说可以举一个例子来说明:
假设有一个文本串“我喜欢吃巧克力”以及一个简单的词典{我,喜欢,吃,巧克力}。
从句子开头开始匹配,首先匹配到的是“我”。因为“我”是一个词,所以匹配成功。
匹配完第一个词之后,继续从“我”的下一个字符开始匹配。此时匹配到的是“喜”。
“喜”不是一个完整的词,所以需要往后继续匹配。继续匹配下一个字符,此时匹配到的是“欢”。
继续往后匹配,此时匹配到了“喜欢”。因为“喜欢”是一个词,所以匹配成功。
继续匹配下一个字符,此时匹配到了“吃”。因为“吃”是一个词,所以匹配成功。
继续匹配下一个字符,此时匹配到了“巧”。
因为“巧”不是一个完整的词,所以需要继续往后匹配。匹配下一个字符,此时匹配到了“克”。
继续匹配下一个字符,此时匹配到了“力”。因为“巧克力”是一个词,所以匹配成功。
到达句子末尾,匹配结束。
根据以上示例,正向最大匹配法的基本流程就是在文本串中从左往右匹配出最长的词,并将其切分出来。这种方法简单易行,但也有一些局限性,例如无法处理歧义问题和新词问题等。
2.2.2 全切分法
全切分法的基本思想是:将待分词的文本中的所有可能的切分方式都进行尝试,从中选择最合适的一种切分方式作为最终的分词结果。具体来说,全切分法会对待分词文本进行递归切分,将文本从左到右依次分成不同的子串,然后对每个子串进行判断,如果是一个词,则将其加入分词结果中,否则将其继续递归切分,直到全部的子串都被切分为止。全切分法的优点是能够保证分词的准确性,但是由于需要考虑所有可能的切分方式,所以速度较慢,不适用于大规模文本的分词[6]。
2.2.3 基于词频分词法
词频分词法的基本思想是:通过统计的方法计算相邻字出现的频率来表示他们的互信息,当他们的频率超过某个阈值时,就把这两个字当成一个词,然后把这些词的词频相乘从而得到最后结果。这种方法复杂度比较高,而且低频词的错误难以克服。
将邮件文本内容经过分词处理后,提取出来的词的数量比较大,如果将这些词全部用作特征,特征向量的维数仍然比较大,可以通过对特征项作进一步的选择和提取,得到贡献比较大的特征集,来提高分类系统的运行速度和程序效率。特征词提取技术是文本挖掘领域的一种重要技术,可以从文本中自动提取出具有代表性或区分性的关键信息,以帮助计算机更好地理解和处理文本。现在常用的特征提取方法有以下五种。
2.3.1 TF-IDF(词频.倒排词频)法
该方法的基本原理是:TF(Term Frequency):词频指的是在一个文档中某个词出现的次数,TF值越高表示该词在文档中的重要性越高。IDF(Inverse Document Frequency):逆文档频率指的是一个词在整个文集中出现的频率,IDF值越高表示该词在整个文集中的重要性越低。TF-IDF:将TF和IDF相乘得到一个词的TF-IDF值,表示该词在文档中的重要性,同时考虑了该词在整个文集中的重要性。应用:TF-IDF可以用于文本分类、关键词提取、相似度计算等任务,通过计算文档中每个词的TF-IDF值,可以找到最相关的文档或者提取出最重要的关键词[7]。公式如下
TF-IDF(T)= ㏒(TF(T)/IDF(T))
2.3.2 互信息
互信息(Mutual Information)是一种用于度量两个随机变量之间相关性的方法。在自然语言处理领域中,互信息常用于词语的特征选择、文本分类和信息检索等任务中。
7 系统测试
7.1 测试方法
系统测试是确保软件系统质量的重要步骤之一。它可以帮助开发团队、测试人员和其他利益相关者识别潜在的问题和错误,并及早发现和解决这些问题,从而提高系统的可靠性、实用性和安全性。
以下是一些常用的系统测试方法:
功能测试(Functional Testing):对系统功能进行测试,确保系统每个模块都能够按照规划正常工作。
安全测试(Security Testing):对系统的安全性进行测试,以评估系统的漏洞和风险,保证系统有良好的安全性能,不容易被黑客攻击或非法入侵。
兼容性测试(Compatibility Testing):对系统硬件、操作系统和浏览器的兼容性进行测试,以保证系统能够在各种环境下正常运行。
在进行系统测试时,需要制定详细的测试计划,确定测试目标、范围和测试方法,确保测试过程和结果的准确性、可重复性和可验证性。同时,需要建立完善的测试记录和报告机制,对测试结果进行分析和总结,及时反馈问题和建议给相关方,以改进和优化系统功能和性能。
7.2 测试用例
为了能够最大限度的检测系统的完备性以及系统对于不同操作系统的兼容性和功能的准确性,本次选择以下测试用例进行系统测试。同时确保测试结果的准确性和可验证性,制作了系统测试用例表以及兼容测试用例表以便对测试结果进行分析和总结。
表7 系统测试用例表
| 测试编号 | 测试内容 | 测试步骤 | 预测结果 | 测试结果 |
| 1 | 验证系统是否能够正确分类垃圾邮件和正常邮件 | 输入已知的正常邮件和垃圾邮件样本数据。进行算法训练。输入未知的邮件数据,查看系统分类结果。 | 图表显示正常 | 通过 |
| 2 | 验证系统处理大量邮件数据时的性能表现 | 生成一定数量的邮件数据集进行朴素贝叶斯算法训练,检测系统运行速度和分类准确性 | 运行速度以及准确性达到预期 | 通过 |
| 3 | 用户登陆 | 输入正确的用户名以及密码 | 成功进入管理系统 | 通过 |
| 4 | 管理系统删除功能 | 删除一次检测记录 | 删除成功 | 通过 |
| 5 | 验证搜索功能 | 查找一次邮件检测记录中邮件的内容 | 查找成功 | 通过 |
| 6 | 用户修改密码 | 点击功能中的修改密码后成功修改密码 | 修改密码成功 | 通过 |
| 7 | 用户修改UI颜色 | 点击配色方案后选择UI颜色 | 配色方案修改成功 | 通过 |
表8 兼容测试用例表
| 测试编号 | 测试内容 | 测试步骤 | 预测结果 | 测试结果 |
| 1 | 不同浏览器下系统的邮件分类 | 使用IE浏览器进行邮件的分类 | 成功进行邮件分类录入数据库 | 通过 |
| 2 | 不同网络环境下进行邮件分类 | 分别使用有线网络以及无线网络进行分类 | 成功进行邮件分类录入数据库 | 通过 |
| 3 | 不同的操作系统下进行邮件分类 | 分别使用Linux系统和Window7系统进行 | 成功进行邮件分类录入数据库 | 通过 |
8 结论
本毕业设计说明书首先介绍开发项目的背景和目的,然后介绍了邮件预处理技术和三种分类算法,通过对三种分类算法的训练并且对其模型进行测试,使用三种指标对其进行评估分别是准确率、精确率和召回率。得出了最适合邮件分类的算法也就是朴素贝叶斯算法。在设计中,通过收集和整理大量的邮件数据样本,并使用朴素贝叶斯分类算法进行训练和测试。从测试结果来看,该系统能够对邮件进行准确地分类,能够有效地识别和分类掉垃圾邮件,通过系统内置的数据检测分析模块可以对检测结果进行分析,优化算法参数,提高系统分类效率。
此外,对于邮件处理系统,性能和安全性也是非常重要的考虑因素。在设计中,进行了性能测试以验证系统在处理大量邮件数据时的表现,并进行了安全测试以验证系统对恶意邮件的检测能力。测试结果表明,该系统具有良好的性能和安全性能。
总体而言,基于朴素贝叶斯的邮件处理系统是一种可靠、高效和安全的解决方案,可以帮助用户减少垃圾邮件骚扰,提高工作效率。但需要注意的是,由于邮件内容信息的复杂性和多变性,系统可能存在误判或漏判的情况,需要不断优化和改进算法,提高分类精度和准确性。
致谢
在此,我想向所有帮助和支持我的人表示衷心感谢。
首先,我要感谢我的导师,他给予了我无私的指导和鼓励,在我的课题设计过程中提供了宝贵的建议和意见。没有他的帮助和指导,我永远不会完成这个系统。
其次,我要感谢我的舍友,他们为我的系统提供了重要的帮助和支持。他们在我需要帮助时总是愿意提供帮助,并且与我分享他们的知识和经验。
我还要感谢我的家人和朋友们,他们一直鼓励我和支持我,在我最需要的时候给予我精神上的支持和鼓励,让我能够坚持到最后。
感谢你们所有人的付出和支持,我才能顺利完成我的毕业设计。
参考文献:
- 李剑峰. 个人计算机的安全与计算机病毒防范[J]. 计算机与网络, 2005(09):40-41.
- 王震. 如何有效治理互联网垃圾邮件[J]. 信息系统工程, 2009(05):21-22.
- 刘少阳. 大数据时代电子邮件中的隐私权保护[D]. 北京, 北京邮电大学, 2016.
- 朱冲冲. 基于排序学习的个性化推荐算法研究[D]. 北京, 北京理工大学, 2018.
- 代伟. 邮件分类器的设计与实现[D]. 长春, 吉林大学, 2010.
- 林文鹏. 基于中文文本挖掘的邮件过滤系统的设计与实现[D]. 沈阳, 沈阳理工大学, 2020.
- 梁好. 基于改进K最近邻模型的反馈学习垃圾邮件过滤系统的设计与实现[D]. 长春, 东北师范大学, 2010.
- 严石. 基于改进TF-IDF和fastText算法的文本分类研究[D]. 淮南, 安徽理工大学, 2020.
- 王斯琴. 改进朴素贝叶斯算法在垃圾邮件过滤中的应用[D]. 重庆, 重庆师范大学, 2020.
- Sun, M, A study on spam email classification algorithm based on Naive Bayes. International Journal of Security and Its Applications[J], 2017(08), 205-206.
- Chen, L. Email classification system based on improved naive Bayes algorithm. Journal of Computer Applications[J]. 2018(01), 297-298.
核心算法代码分享如下:
import jieba
from machine_learning import predict as pt
from service.slog_service import insert_slog
# 简单统计模块
# 连续字母且不成单词
# 连续数字且不具备含义
# 连续标点符号
def isPunctuation(word):
'''判断是否为特殊字符'''
string = "《》?“”:{}+——!~@#¥%……&*()/*-,。‘’;】【、|·,.;'][`\!$^()_"
if word in string:
return True
else:
return False
def isChinese(word):
'''判断是否为中文汉字'''
for i in word:
if word >= u'\u4e00' and word <= u'\u9fa5':
continue
else:
return False
return True
# 文本统计学分析
# number_minlen 字母串长度(最小长度,大于则统计)
# letter_minlen 字母串长度(最小长度,大于则统计)
# alnum_minlen 混合长度(最小长度,大于则统计)
def wordAnalysis(text, number_minlen, letter_minlen, alnum_minlen):
words_arr = jieba.cut(text)
word_num, words_num, punctuation_num, letter_num, number_num, alnum_num, chi_len, num_len, letter_len = 0.001, 0.001, 0.001, 0.001, 0.001, 0.001, 0.001, 0.001, 0.001
for word in words_arr:
word_len = len(word)
if isChinese(word):
if word_len >= 2:
words_num += 1
else:
word_num += 1
chi_len += len(word)
else:
if isPunctuation(word):
punctuation_num += 1
elif word_len > letter_minlen and word.isalpha():
letter_num += 1
letter_len += word_len
elif word_len > number_minlen and word.isdigit():
number_num += 1
num_len += word_len
elif word_len > alnum_minlen and word.isalnum():
alnum_num += 1
for i in word:
if i.isalpha():
letter_len += 1
else:
num_len += 1
return word_num, words_num, punctuation_num, letter_num, number_num, alnum_num, chi_len, num_len, letter_len
# 预测邮件
def predict(text):
y = pt.predict([text])
y = 1 if len(y) <= 0 else y[0]
insert_slog({'content': text, 'result': y})
return y