自编码器(autoencoder)是神经网络的一种,能够实现无监督的学习,解决了训练神经网络让人头痛的标签数据的问题。特别在地震勘探领域,地震剖面复杂多样,要给出标签数据难度更大。
理想很丰满,现实很骨感。
当我直接把自编码对Minist处理的程序移植到地震处理,结果却大跌眼镜。
比如一个这样的噪声图片:
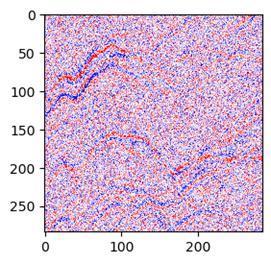
经过程序处理和调整后,是这样:
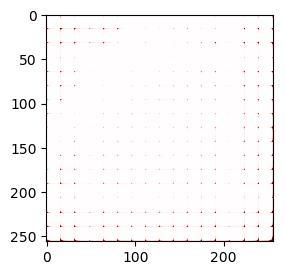
或者是这样:
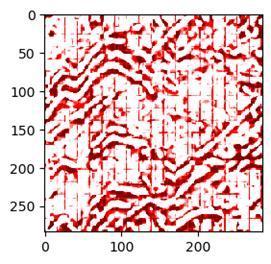
很显然,上面的效果根本拿不出手。
具体见前面几篇文章:地震去噪新探索——无监督卷积神经网络实战 ,地震去噪新探索(二)——无监督卷积神经网络调优实战 和地震去噪探索(三)——怎样让卷积神经网络学习更多特征 。
经过前面的探索,我认真总结和思考了降噪自动编码(DAE)和地震降噪的一些基本原理和一些解决思路。
01 自编码实现无监督学习的原理
自编码实现学习的基本原理就是通过神经网络学习尽量实现输出结果和输入数据相近。
这里有个问题:因为无监督学习没有标签数据,输入和标签都是同样的数据。学习过程有可能出现这样的情况:输入什么数据,无需学习就直接原样输出什么,这样就失去的学习的意义。
所以我们不应该将自编码器设计成输入到输出完全相等。自编码的网络通常需要强加一些约束,使它只能近似地复制,并只能复制与训练数据相似的输入。比如自编码的编码和解码过程就是压缩和还原过程,这个过程是有信号损失的,所以还原过程是不可能完全恢复原样的。这样当输入和标签都是同一个数据时,网络会学着去逼近输入信号,从而提高了学习能力。
比如在keras的官方教程(https://blog.keras.io/building-autoencoders-in-keras.html)有这样一段程序:
autoencoder.fit(x_train, x_train,…
这里输入和标签数据都是训练数据。
那学习的学习效果如何呢?上面是原图,下面是学习完后还原的图,可以看到还原的效果还是比较好的:

02 降噪自动编码的原理
降噪自动编码器(DAE)是独成体系的一类自动编码应用。设计DAE的初衷就是在自动编码器的基础之上,为了防止过拟合问题而对输入层的输入数据加入噪音,使学习得到的编码器具有鲁棒性而改进的,是Bengio在08年论文:Extracting and composing robust features with denoising autoencoders提出的。
论文中关于降噪自动编码器的示意图如下,类似于dropout,其中x是原始的输入数据,降噪自动编码器以一定概率(通常使用二项分布)把输入层节点的值置为0,从而得到含有噪音的模型输入xˆ。
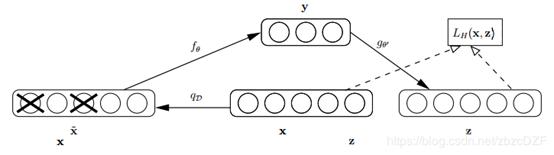
说简单点,当使用自编码来进行降噪,原理和第一部分自编码的原理差不多。还是使用自编码来学习含噪数据中的数据特征(有效信号),训练过程同样是让学习的结果尽量接近输入的数据。就是说输入是噪声数据,标签也是噪声数据。就像下面这样:
autoencoder.fit(x_train_noisy, x_train_noisy,…
训练效果就像这样,上面是含噪声的图像,下面是去噪的结果。可以看到还是有一定效果的。

03 DAE怎样适用于地震去噪
DAE处理Mnist看到了效果,直接把代码用到地震去噪效果为啥就不行呢?
1.Mnist图片和地震剖面数据的区别
首先,Mnist的数据结构很简单,数值范围是(0,255)。
训练的任务也很简单,就是要学习上图中的数字这个特征,得到下图的效果。而其它信息都认为是噪声。

然而,地震剖面数据要复杂的多。地震的数值范围没有固定值。地震去噪的任务是要从上图的噪声数据中学习到所有的同相轴信号,得到下图的效果。这里要学习的特征非常多。
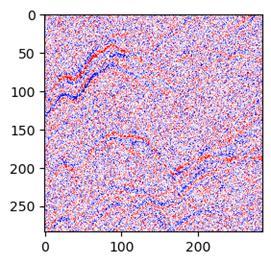
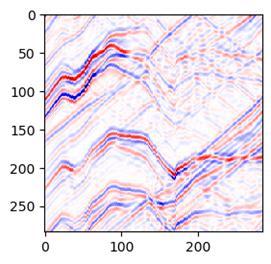
2.Mnist图片去噪使用了分类的算法,地震去噪需要使用回归的算法
这里的回归是指的线性回归,返回的是一系列连续的实数。
这里的分类是指的逻辑回归,返回的值并不是连续的,是离散的整数。
分类的实现
在逻辑回归算法中,常使用的激活函数包括:一是sigmoid,用于处理二分问题,0代表负类,或者叫“否”,1代表正类,或者叫 “是”。二是softmax,它是二分类函数sigmoid在多分类上的推广,目的是将多分类的结果以概率的形式展现出来。
逻辑回归常用的损失函数是交叉熵损失函数(cross entropy loss)这个系列。
回归的实现
在线性回归算法中,常使用的激活函数包括:一是relu,,二是tanh。
tanh优势在于其取值范围介于-1 ~ 1之间,数据的平均值为0;但是缺点是会在端值趋于饱和,造成训练速度减慢。Relu的取值范围为大于0,解决了梯度弥散问题,收敛速度很快。
因此在深层隐藏层的训练一般用relu,在输出层由于地震有负数值,所以用tanh更好。
线性回归常用的损失函数是均方差(MSE)这个系列的。
具体的函数表达式大家自行百度啦。
那么Mnist是怎样做的呢?
decoded = Conv2D(1, (3, 3), activation='sigmoid', padding='same')(x)
autoencoder.compile(optimizer='adadelta', loss='binary_crossentropy')
妥妥的都是分类的算法
要想地震去噪出效果需要这样做:
decoded = Conv2DTranspose(1, (1,1), padding='same', activation='tanh', kernel_initializer='glorot_normal')(x)
autoencoder.compile(optimizer='adadelta', loss='binary_crossentropy')
效果是这样的,上图是噪声信号,下图是去噪效果:
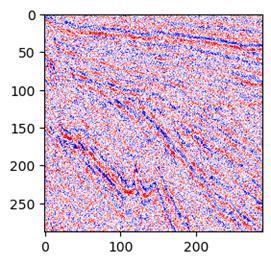
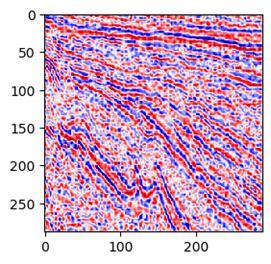
04 提升DAE地震去噪效果的一些思路
1.训练多少周期才合适?
经过实验发现,DAE训练效果并不会随迭代LOSS减少而持续变好,而是有一个极值。
比如10个epoch是这个效果:
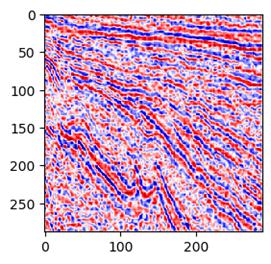
50个epoch变成了这样:
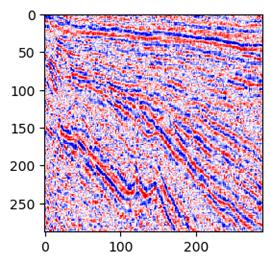
这种现象在其它网络学习中也很常见:训练少量了没有学习到特征,为欠拟合。训练太多了,学习到了很多无关的特征,过拟合。
那解决方案就是去和原始的清晰图像对比,什么时候去噪结果最接近清晰图像,这时候的迭代次数就是最优的。
2.怎样更好地学习到特征信号?
一是直接把清晰图片进行网络训练。通过噪声图片学习有效特征,始终不如直接输入清晰图片学习的彻底。所以不如先用清晰图片来训练网络,再把网络用来降噪预测。
二是在网络中增加稀疏约束。有很多专家在网络结构中增加稀疏约束,让网络更专注于学习有效的特征。
三是修改LOSS函数。根据地震的特征修改LOSS函数,就相当于改变了网络的学习能力。