之前介绍了很多的请求网站的方法,实际上我们都有一个假设,就是网站访问都是成功的。但是实际情况可能会有所不同,有可能在访问网站的时候由于地址更新,cookie没有或者,或者任何网络问题导致我们无法正常的访问网站。今天来看看如何catch在访问网站中产生的error信息。直接开始
没有对error进行处理
我们这里乱填写一个url,得到的结果是404 错误。如果在现实开发中,遇到这个错误不处理的话,那么爬虫程序就结束了。
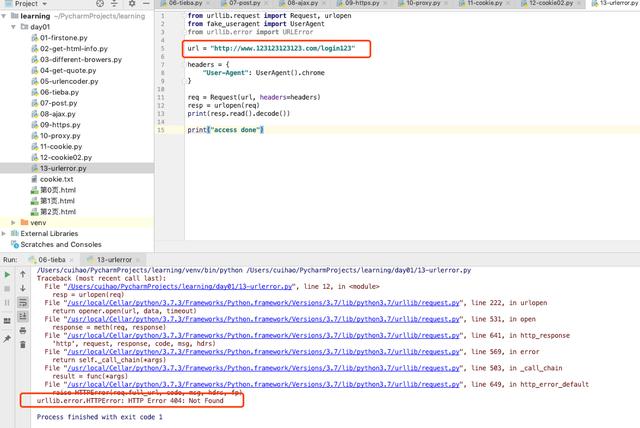
from urllib.request import Request, urlopenfrom fake_useragent import UserAgentfrom urllib.error import URLErrorurl = "http://www.123123123123.com/login123"headers = { "User-Agent": UserAgent().chrome}req = Request(url, headers=headers)resp = urlopen(req)print(resp.read().decode())print("access done")对error进行处理
这里其实和其他的应用程序都很像,都是通过try catch的方式,捕捉异常并且返回异常的详细情况。
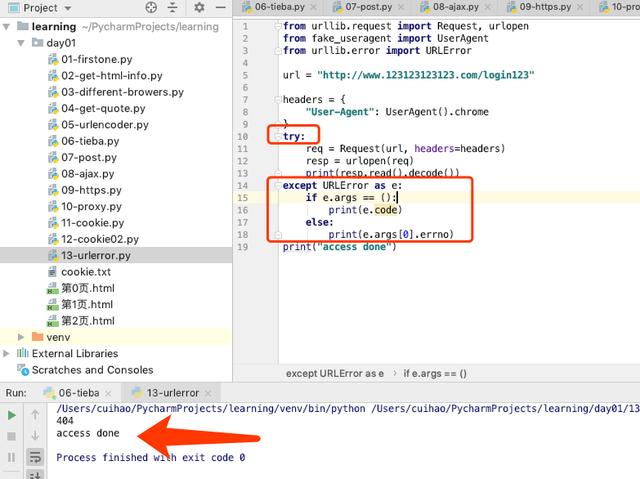
这里程序遇到问题依旧可以继续进行下去。
from urllib.request import Request, urlopenfrom fake_useragent import UserAgentfrom urllib.error import URLErrorurl = "http://www.123123123123.com/login123"headers = { "User-Agent": UserAgent().chrome}try: req = Request(url, headers=headers) resp = urlopen(req) print(resp.read().decode())except URLError as e: if e.args == (): print(e.code) else: print(e.args[0].errno)print("access done")是不是很快就搞定了?
谢谢您的关注,如果喜欢帮我转发一下。