1.etcd介绍
官方网址:https://etcd.io/docs/v3.6/op-guide/recovery/
k8s相关网址:https://v1-25.docs.kubernetes.io/zh-cn/docs/tasks/administer-cluster/configure-upgrade-etcd/#restoring-an-etcd-cluster
etcd拉起过程:
kubelet自动扫描/etc/kubernetes/manifests目录(如下图),如果发现.yaml文件自动拉起来
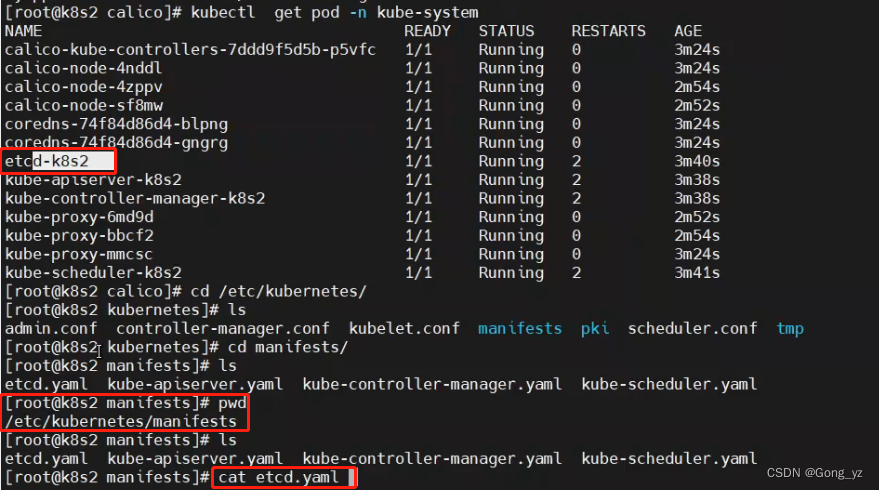
Etcd被形容为Kubernetes集群的大脑,是 Kubernetes的关键组件,因为它存储了集群的全部状态:其配置,规格以及运行中的工作负载的状态。
在Kubernetes世界中,etcd用作服务发现的后端,并存储集群的状态及其配置。
Etcd被部署为一个集群,几个节点的通信由Raft算法处理。在生产环境中,集群包含奇数个节点,并且至少需要三个。
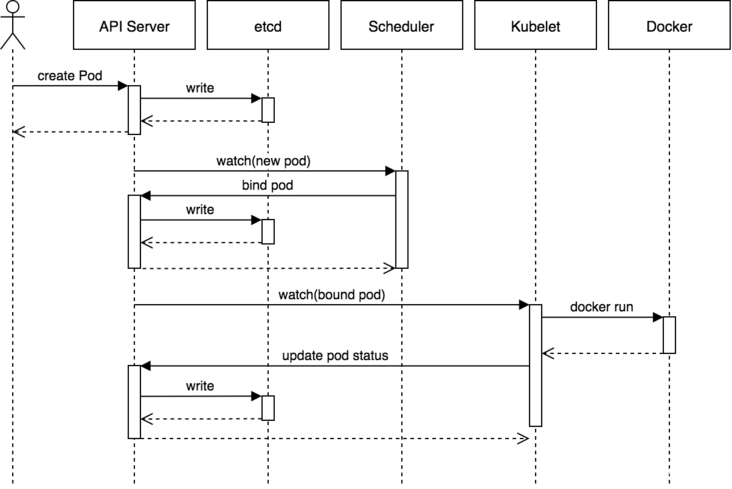
以下来自Heptio博客的序列图显示了在简单的Pod创建过程中涉及的组件。它很好地说明了API服务器和etcd的交互作用。
2.重新搭建集群环境
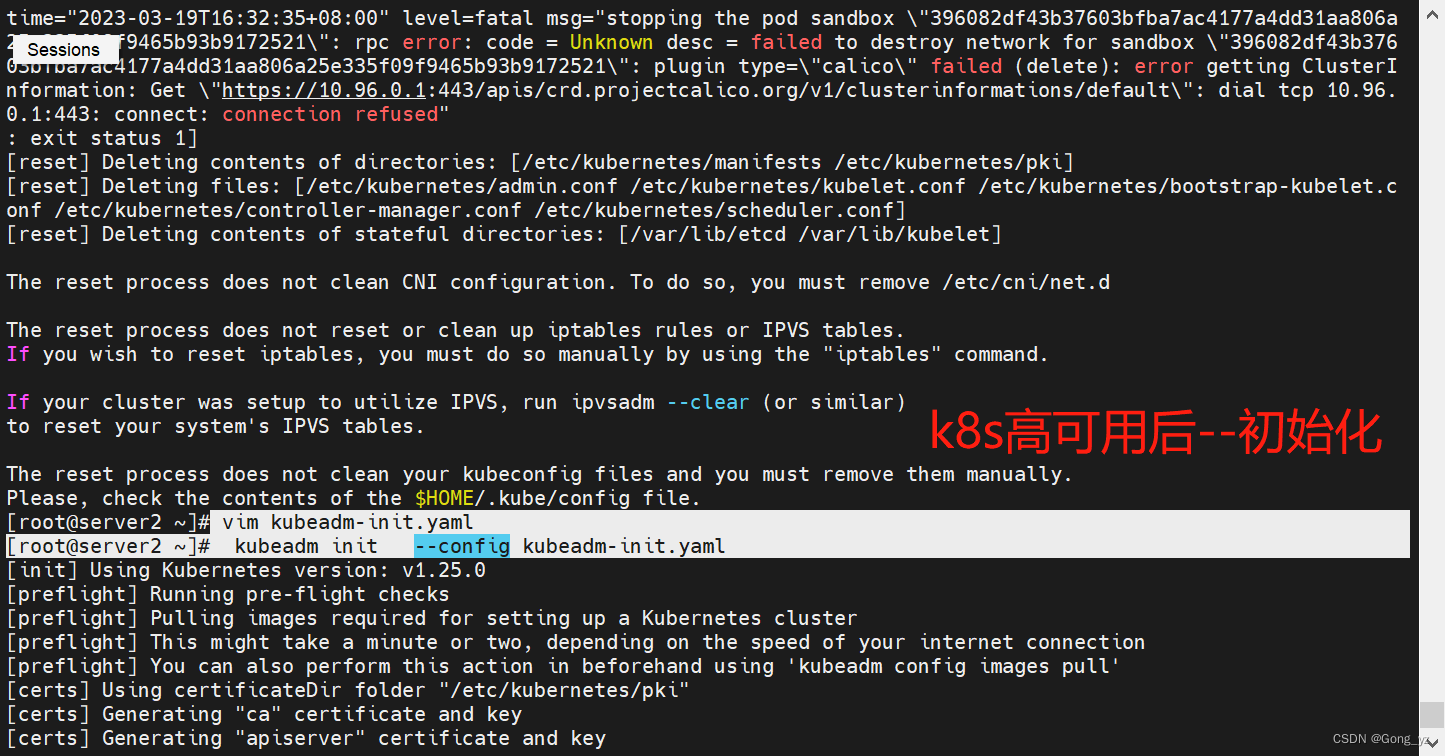
由于在k8s高可用集群实验后做该实验,我们需要重新初始化集群环境
[root@k8s2 ~]# kubeadm reset
[root@k8s2 ~]# vim kubeadm-init.yaml ##去掉高可用实验时加入的负载均衡地址(25行左右)
[root@k8s3 ~]# kubeadm reset
[root@k8s4 ~]# kubeadm reset
k8s2作为control-plane执行初始化(如下图),然后在k8s3和k8s4节点执行生成的token使这两个节点加入集群即可
[root@k8s2 ~]# kubectl get node ##
NAME STATUS ROLES AGE VERSION
k8s2 Ready control-plane 90m v1.25.0
k8s3 Ready 89m v1.25.0
k8s4 Ready 89m v1.25.0
3.etcd的备份
所有 Kubernetes 对象都存储在 etcd 上。 定期备份 etcd 集群数据对于在灾难场景(例如丢失所有控制平面节点)下恢复 Kubernetes 集群非常重要。 快照文件包含所有 Kubernetes 状态和关键信息。为了保证敏感的 Kubernetes 数据的安全,可以对快照文件进行加密。
备份 etcd 集群可以通过两种方式完成:etcd 内置快照和卷快照。也可以使用 etcdctl 选项的快照;
本实验我们采用etcdctl 选项的快照.
得到etcdctl命令
为了版本能够对应,我们未采用安装一个etcdctl,而是从镜像中拷贝etcdctl二进制命令,具体操作如下:
从镜像中拷贝etcdctl二进制命令(需确保docker服务开启:systemct status docker)
[root@k8s2 ~]# docker run -it --rm reg.westos.org/k8s/etcd:3.5.4-0 sh
输入ctrl+pq快捷键,把容器打入后台
获取容器id
[root@k8s2 ~]# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
c8a2291ce220 reg.westos.org/k8s/etcd:3.5.4-0 "sh" 5 seconds ago Up 4 seconds 2379-2380/tcp, 4001/tcp, 7001/tcp vibrant_ishizaka
从容器拷贝命令到本机 ##上课实验时命令路径查看:docker history reg.westos.org/k8s/etcd:3.5.4-0
[root@k8s2 bin]# docker container cp c8a2291ce220:/usr/local/bin/etcdctl /usr/local/bin
[root@k8s2 ~]# which etcdctl
/usr/local/bin/etcdctl
删除容器
[root@k8s2 bin]# docker rm -f c8a2291ce220
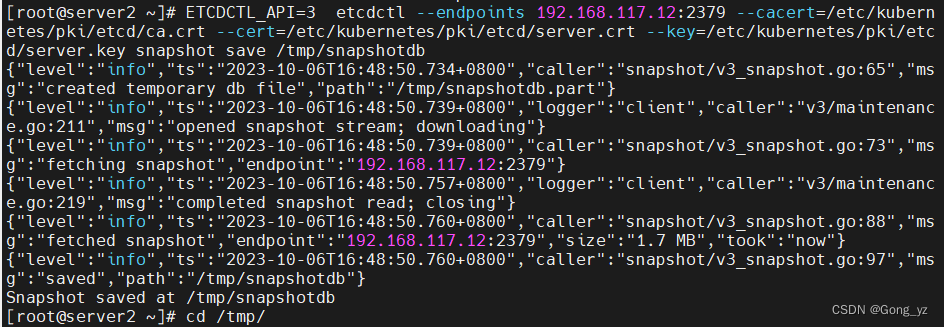
备份
[root@k8s2 etcd]# ETCDCTL_API=3 etcdctl --endpoints 192.168.56.12:2379 --cert=/etc/kubernetes/pki/etcd/server.crt --key=/etc/kubernetes/pki/etcd/server.key --cacert=/etc/kubernetes/pki/etcd/ca.crt snapshot save /tmp/snapshotdb
注:
ETCDCTL_API=3 ----###v3版本
etcdctl --endpoints 192.168.56.12:2379 ----###
–cert=/etc/kubernetes/pki/etcd/server.crt----###证书位置
–key=/etc/kubernetes/pki/etcd/server.key----###key位置
–cacert=/etc/kubernetes/pki/etcd/ca.crt —###ca位置,因为有安全通信
snapshot save /tmp/snapshotdb----###创建snapshot(快照)的位置:/tmp/snapshotdb
如果加:member list----###列出成员
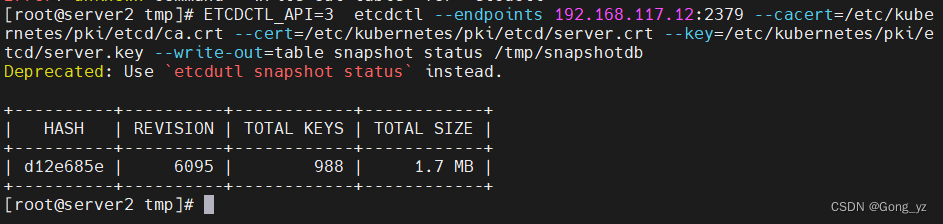
查看快照状态
[root@k8s2 etcd]# ETCDCTL_API=3 etcdctl --endpoints 192.168.56.12:2379 --cert=/etc/kubernetes/pki/etcd/server.crt --key=/etc/kubernetes/pki/etcd/server.key --cacert=/etc/kubernetes/pki/etcd/ca.crt –write-out=table snapshot status /tmp/snapshotdb
注:
–write-out=table snapshot status /tmp/snapshotdb----###表示输出的时候通过表格的方式进行显示
删除集群资源
[root@k8s2 etcd]# kubectl get pod ##pod为提前建好,等会恢复即可证明实验成功
NAME READY STATUS RESTARTS AGE
myapp-fcfbd4477-8mg4l 1/1 Running 0 27m
myapp-fcfbd4477-h52c9 1/1 Running 0 27m
myapp-fcfbd4477-s7nf2 1/1 Running 0 27m
[root@k8s2 etcd]# kubectl delete deployments.apps myapp
deployment.apps "myapp" deleted
[root@k8s2 etcd]# kubectl get pod ##已经删除干净
No resources found in default namespace.
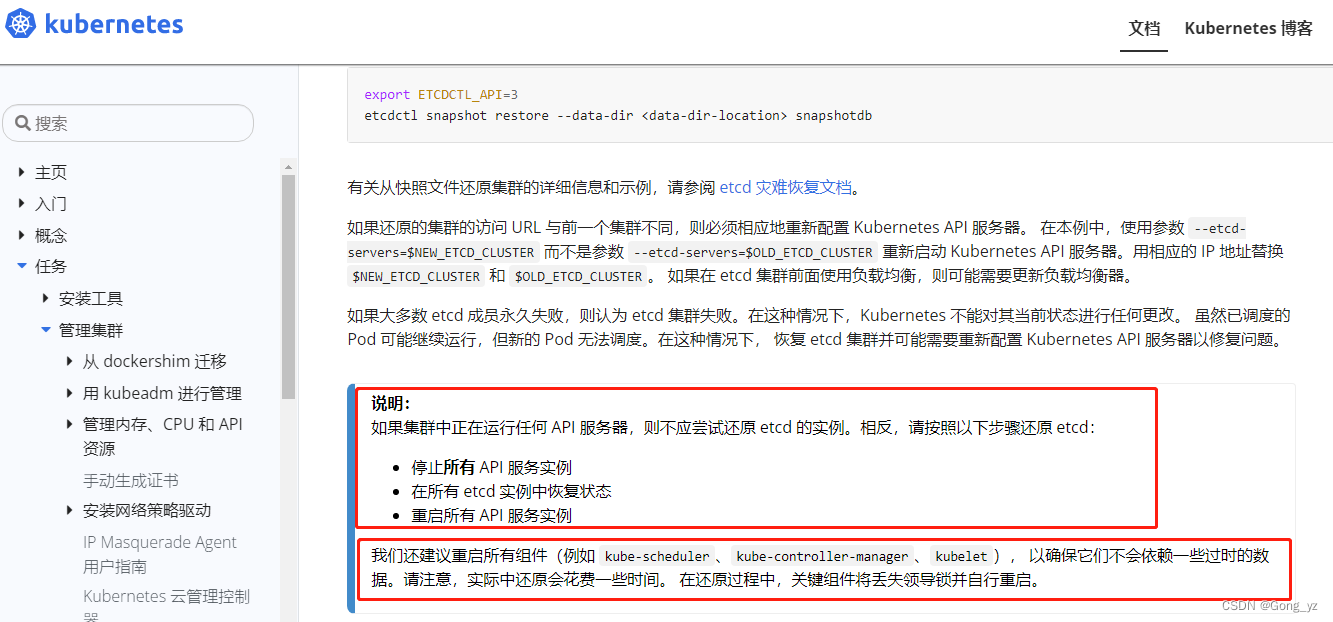
4.etcd数据的恢复
下图需注意:如果是集群恢复,需要将control-plane节点全部停止API,逐个进行恢复;所以集群恢复更加麻烦
在/etc/kubernetes/manifests/目录中,所有的核心示例都用静态pod定义;
所以,停止所有核心组件,把该目录的文件移走即可;kubelet会扫描该目录,则对应容器自动停止
停止所有核心组件
[root@k8s2 etcd]# cd /etc/kubernetes/manifests/
[root@k8s2 manifests]# ls
etcd.yaml kube-apiserver.yaml kube-controller-manager.yaml kube-scheduler.yaml
[root@k8s2 manifests]# mv * /mnt/
移除yaml文件后对应容器自动停止:只剩下下图所示,kubectl命令无法使用
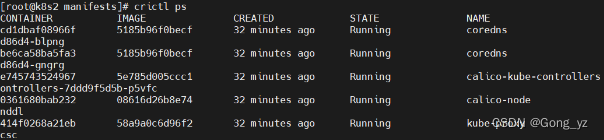
从快照恢复
[root@k8s2 manifests]# cd /var/lib/etcd/ ##所有数据的位置目录
[root@k8s2 etcd]# ls
member
[root@k8s2 etcd]# mv member/ /tmp/ ##为了不覆盖,把member目录移走
[root@k8s2 etcd]# ETCDCTL_API=3 etcdctl snapshot restore --data-dir /var/lib/etcd/ /tmp/snapshotdb
##恢复快照;指定数据目录为/var/lib/etcd/ ;快照位置:/tmp/snapshotdb
[root@k8s2 etcd]# ls
member ##恢复后的新目录
重启所有组件
[root@k8s2 ~]# cd /etc/kubernetes/manifests/
[root@k8s2 manifests]# mv /mnt/* .
yaml文件移动回来后容器自动启动
测试:
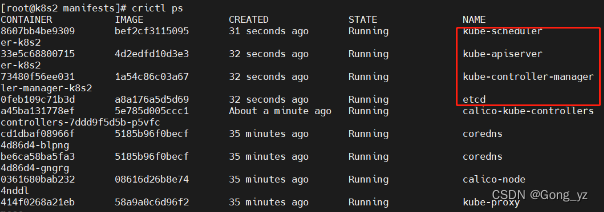
所有集群节点重启kubelet服务
[root@k8s2 manifests]# systemctl restart kubelet
[root@k8s3 ~]# systemctl restart kubelet
[root@k8s4 ~]# systemctl restart kubelet
看到pod恢复表示成功
[root@k8s2 manifests]# kubectl get pod ##删除的pod已经恢复,pod的name等都不变
NAME READY STATUS RESTARTS AGE
myapp-fcfbd4477-8mg4l 1/1 Running 0 34m
myapp-fcfbd4477-h52c9 1/1 Running 0 34m
myapp-fcfbd4477-s7nf2 1/1 Running 0 34m